Google's subsea fiber optics, explained

Stephanie Wong
Head of Developer Skills & Community, Google Cloud
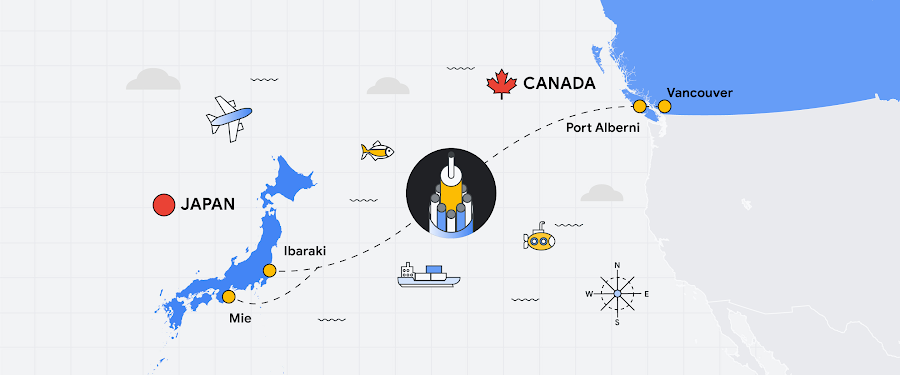
Fiber optic networks are a foundation of the modern internet. In fact, subsea cables carry 99% of international network traffic, and yet we are barely aware that they exist. What you might not know is that the first subsea cable was deployed in 1858 for telegraph messages between Europe and North America. A message took over 17 hours to deliver, at 2 minutes and 5 seconds per letter by Morse code.
Today, a single cable can deliver a whopping 340 Tbps capacity; that’s more than 25 million times faster than the average home internet connection. Over the years at Google, we have worked with partners around the world to engineer more capacity into the fiber optics that can be underground or laid at the bottom of the ocean. It takes an impressive combination of physics, marine technology, and engineering, which is why I set out to make a video about what it takes to plan and implement a global network in a world of ballooning network demand.
When I started making this video, there were a few questions that I wanted to answer. After 25+ hours of research—from interviewing optical network engineers to exploring our network design documents—I finally started to scratch the surface of a sea of information, so let’s dive into my findings (puns intended)!
How does Google Cloud predict network traffic and plan for capacity?
Physical infrastructure permitting, identifying power sources, and installing cooling and hardware. The entire process for one project can take multiple years to plan and implement. As a result, capacity planning must be done far in advance. It’s difficult to predict capacity needs; a typical trend line analysis won’t work. Given these long lead times and a 20+ year typical life of a cable, our forecasting and asset acquisition decision analysis looks at demand forecasts across a longer time horizon of multiple years rather than months.
One factor is certain: Cloud is a big growth driver of Google’s network demand, with Gartner predicting the world’s cloud spending to increase to $917B by 2025. Google Cloud has pushed our need to increase the availability and speed of our network and services. We need to handle traffic surges that can stem from Google Cloud customers. We also need to plan for higher network capacity when we add new regions, with redundant pathways to those new locations. Because our Global Networking team wants to deliver capacity when Google Cloud customers need it, we design our network with reliability in mind, consider multiple points of failure, and provide fast failover.
Forecasting in parts
To forecast capacity needs, we predict demand five years out, three years out, and 3-6 months out using sensitivity analyses. We then determine the size of the cable investment that meets an optimal point on the cost curve–one that balances capacity and cost, while meeting Google Cloud requirements like latency. To help with forecasting, we break our network down into three categories:
Inter-metro network – pathways connecting major metropolitan areas, both within a continent and across continents.
Regional – pathways connecting data centers within a metropolitan region
Edge – pathways connecting Google’s network to internet service providers (ISPs)
Engineering teams are obsessed with network resilience
Dozens of engineering teams work to forecast and design the network. They determine:
The bandwidth needs of individual Google services (for example, a Google Cloud service, Search, YouTube).
The shape of the network topology to optimize for performance (how various nodes, devices, and connections are physically or logically arranged in relation to each other).
The number of routes (that is, the number of circuits to each location) needed for high availability. We look for routes that are fully disjointed and diverse to prevent any single points of failure.
Testing optical fiber to improve capacity planning
The Optical Network Engineering team tests our fiber optic cables to understand how they will perform in the Google Cloud network. These tests play a significant role in capacity planning because the results help us predict what we can deliver.
The goal is to achieve the highest signal to noise ratio. As light travels through fiber over long distances, the signal it carries gets distorted. While we can’t house an entire cable in a lab, we do have dozens of spools of fiber that we daisy chain together to replicate the Google Cloud network. Using an optical spectrum analyzer we check the quality of the signal as we pulse lasers, pushing 1.2 Tbps of 0s and 1s through the cable!

But fiber is not just about lasers, cables, and the laws of physics. Our response to changes and issues in hardware requires robust automation through software. We build automation pipelines to enable us to deploy new fiber to connect our regions. If there are disruptions in the fiber, automation enables us to pinpoint the issue with an accuracy of a few meters and respond rapidly.
What technology have we developed to increase the reliability and scale of the network?
Space Division Multiplexing
The Grace Hopper cable is breaking records by using space division multiplexing (SDM) to fit sixteen fiber pairs into the cable, instead of the usual six or eight. Once delivered, that cable will be able to transmit 340 Tbps–enough to stream my video in 4K 4.5 million times simultaneously! SDM increases cable capacity in a cost-effective manner with additional fiber pairs while taking advantage of power-optimized repeater designs. With the Topaz cable, we are working with partners to use SDM technology and sixteen fiber pairs to give it a design capacity of 240 Tbps. The 19th century electrochemical scientist Michael Faraday would be proud of us knowing that we could send over 2.4 trillion bits every second across the Pacific Ocean in a single cable.

Wavelength Selective Switching
Topaz will also use wavelength selective switching (WSS). WSS can be used to dynamically route signals between optical fibers based on wavelength. This greatly simplifies the allocation of capacity, giving the cable system the flexibility to add and reallocate it in different locations as needed. Here’s how it works:
Branching Units are used to split a portion of the cable to land at a different location. Branching can be either at the fiber pair or wavelength level.
WSS splits the signal between the main trunk and the branch path based on its wavelength. This allows the signals from different paths to share the same fiber instead of installing dedicated fiber pairs for each link.
The cable system can then carve up the spectrum on an optical fiber pair and apply capacity to different locations using a single fiber pair, giving us the ability to redirect traffic on the fly.

WSS for resilient and dynamic paths was first sketched on a Google whiteboard over four years ago. Now this innovation is being adopted across the industry.
Why is it so rare for Google Cloud customers to notice when a cable is affected?
While fiber optic cables are protected, they aren’t immune to damage. Fishing vessels and ships dragging anchors account for two-thirds of all subsea cable faults.
Though the risks are unavoidable, it’s important to remember that fiber optic cables are part of the network backbone of the internet that links data centers and thousands of computers together. That’s why Google maintains an intense focus on building and operating a resilient global network while we continue to advance its breadth, reliability, and availability. For example, it can sometimes take weeks to repair a cable that has been physically damaged. So, to ensure that services aren’t affected in such a situation, we design the network with extra capacity: each cross section has multiple cables and no single point of failure.
Our philosophy is to create enough concurrent network paths at the metro, regional, and global level—coupled with a scalable software control plane—to support traffic redistribution while minimizing network congestion. When service disruptions occur, we’re still able to serve people around the world because other network paths exist to reroute traffic seamlessly. When a link between the US and Chile becomes disrupted, for example, Google Cloud can reroute traffic for customers on our additional diverse paths.
How can Google Cloud customers make the most of these advancements?
Network planning, operations, and monitoring are linchpins at Google.
Premium Tier network is the gateway to Google’s high-speed network
To understand the Google Cloud network backbone, it is useful to have an understanding of how the public internet works. Dozens of large ISPs interconnect at network access points in various cities. The typical agreement between providers involves something called hot potato routing. An ISP hands off traffic to a downstream ISP as quickly as it can to minimize the amount of work that the ISP's network needs to do. This can mean more hops between networks and routers before traffic arrives at its destination. This kind of routing is available on Google Cloud with our Standard Tier network.
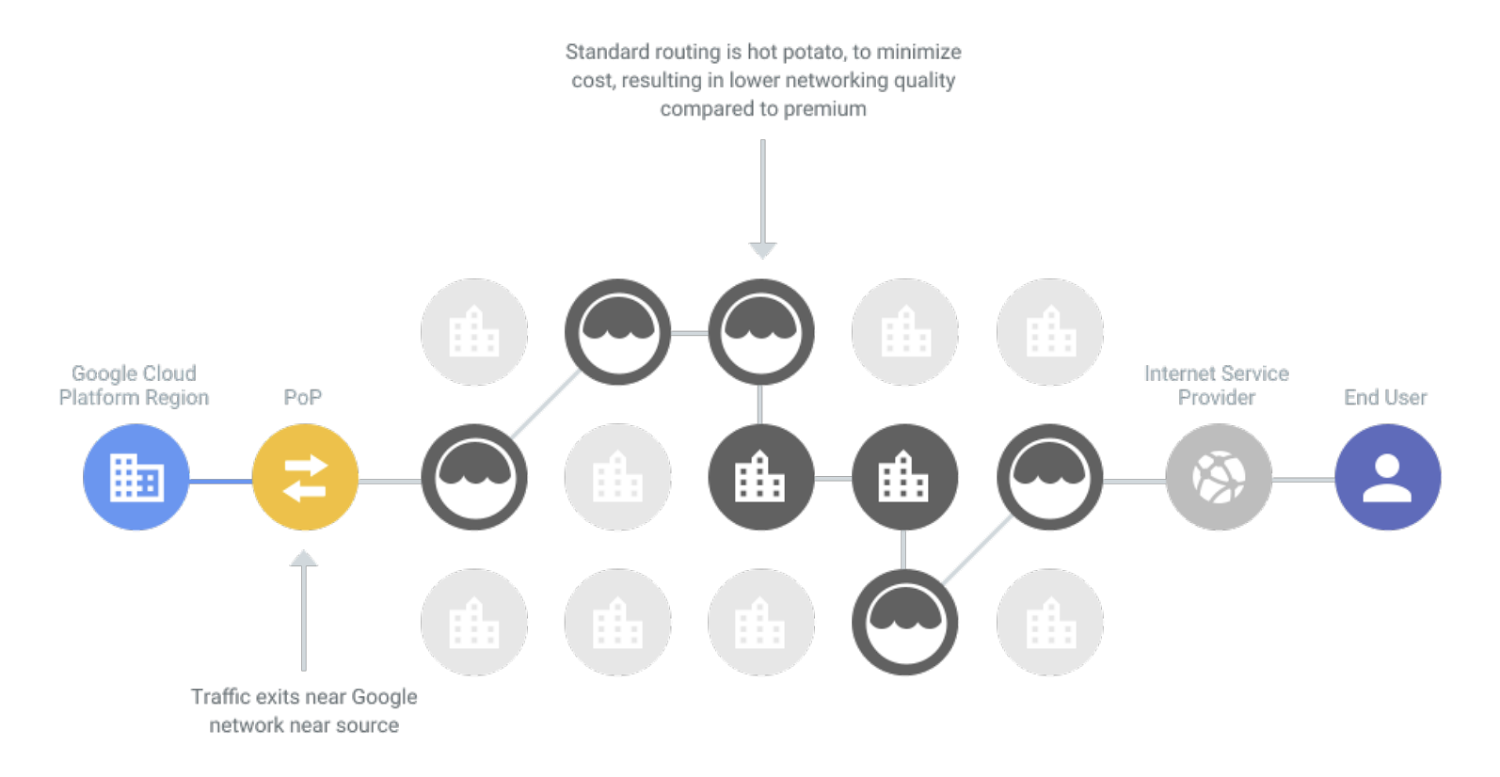
Google Cloud’s Premium Tier network, in contrast, uses cold potato routing. It keeps traffic on its private network backbone, requiring fewer hops between ISPs. It offloads traffic to ISPs at the last possible moment, when the data is closest to the end user.
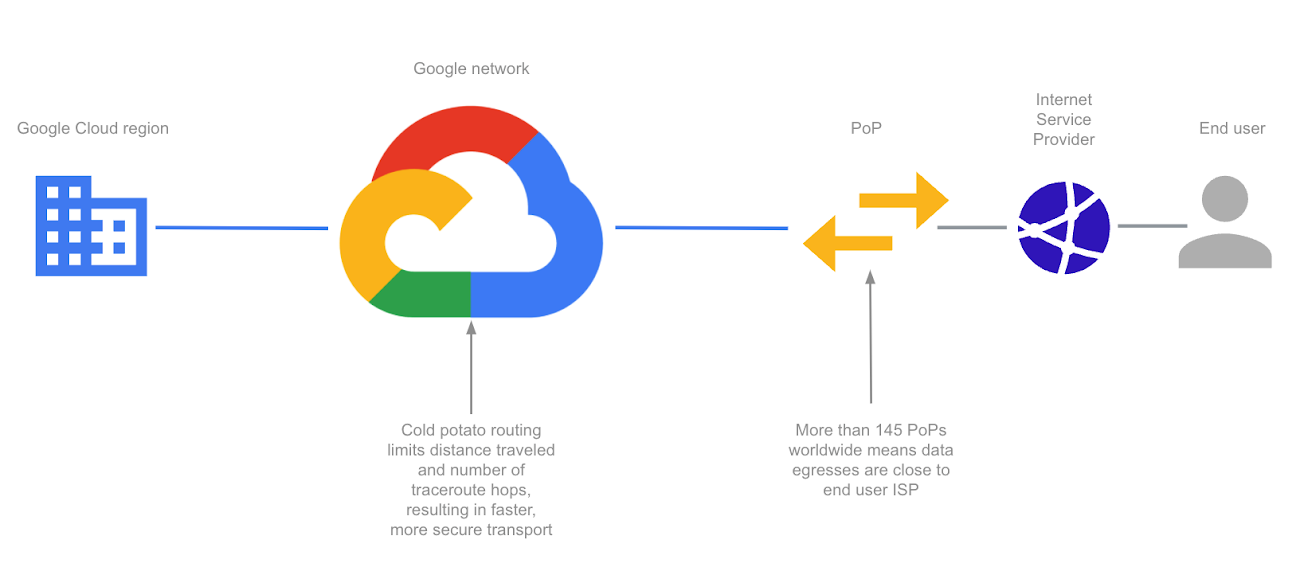
Let’s put this in perspective with an example. If you’re a company using traditional networks, your traffic from your own private data center in the US to its destination in Chile will first traverse your local ISP. That local ISP most likely uses a fiber supplier and passes that traffic off to another ISP. Between the many hot-potato hops, you may face higher latency and limited bandwidth capacity.
With Google Cloud, you can use our Premium Tier network to achieve 1.4X higher throughput than the Standard Tier, as well as Cloud CDN to cache content closest to your end users.
The beauty of vertical integration
Let’s not forget the software stack that sits on top of the physical network. The network topology and software-defined controller for traffic routing is built for fault tolerance. Our data center network fabric is made up of a closed hierarchical switching fabric that we designed called Jupiter, which connects hundreds of thousands of machines across data centers, providing 1 Pbps of bisection bandwidth.
Jupiter is able to provide such high bandwidth because it’s nonblocking, which means it can handle routing a request to any free output port without interfering with other traffic. This means it can scale or burst with extremely low latency, and is fault-tolerant. If something in the fabric breaks, it is built to handle disruptions.

Google Cloud is underpinned by Andromeda, a virtualized software-defined network built on top of Jupiter, giving you your very own slice of our massive global switching fabric. Andromeda enables you to deploy a global virtual private cloud network–with the aim of providing you both functional and performance isolation, as well as a high degree of security. With its global control plane, high-speed on-host virtual switch, and packet processors, you can burst thousands of stateful machines online in minutes or deploy firewall rules across thousands of machines immediately without chokepoints. Google Cloud’s global Virtual Private Cloud (VPC), for example, gives you the ability to have a single VPC that can span multiple regions without communicating across the public internet. Because various microservices may be separated and talk to each other through the network, they can scale independently so you get virtually unlimited storage and stateless, resilient compute, along with features like live migration.
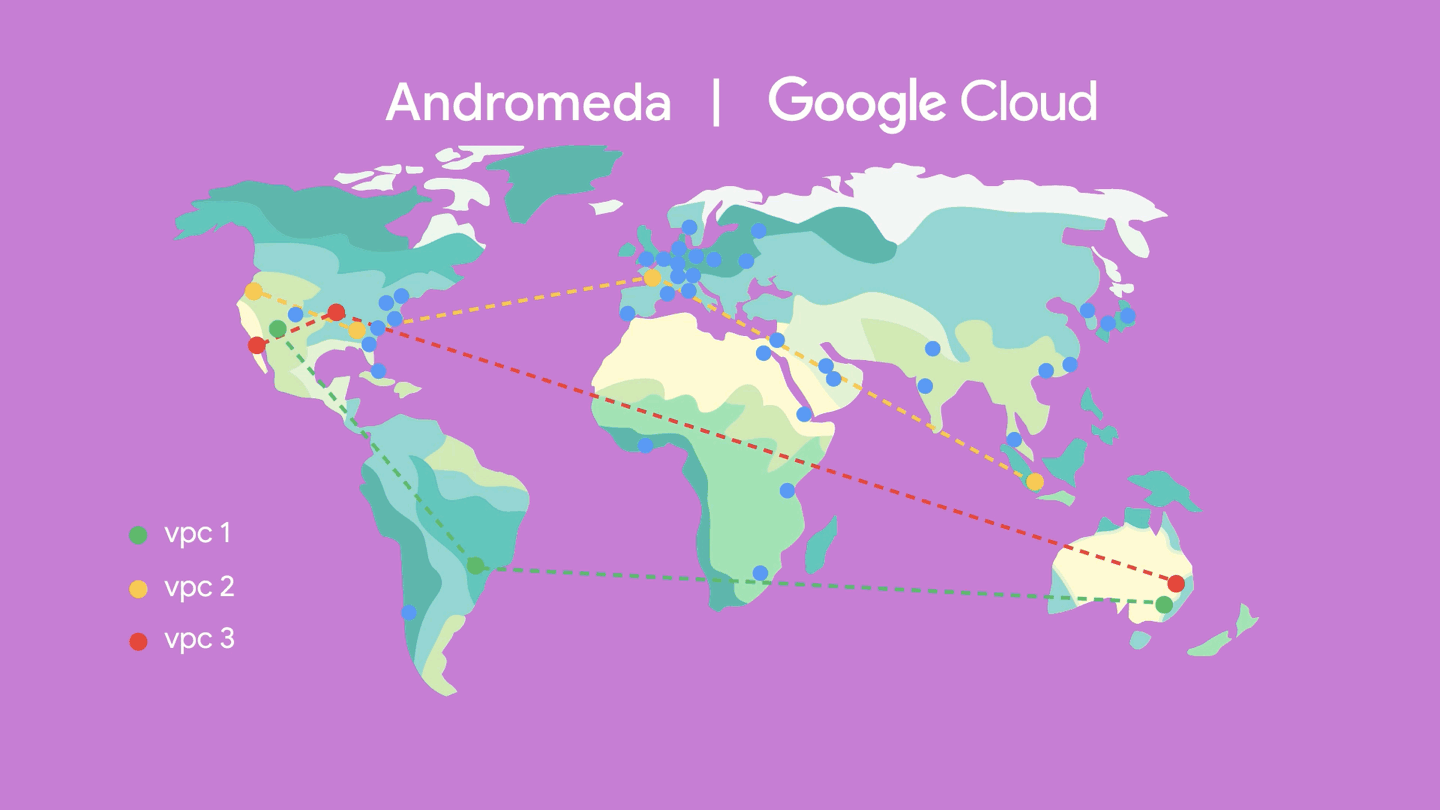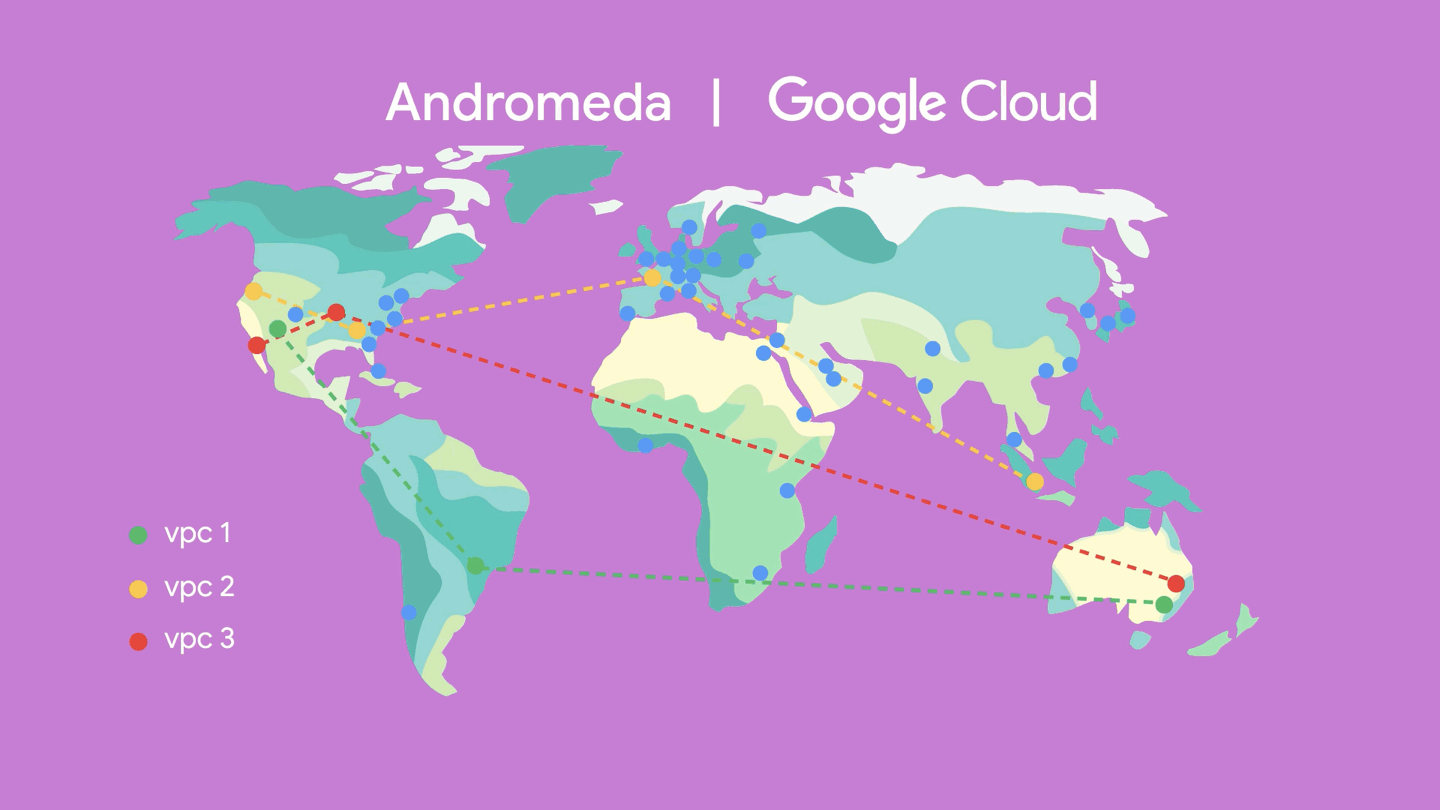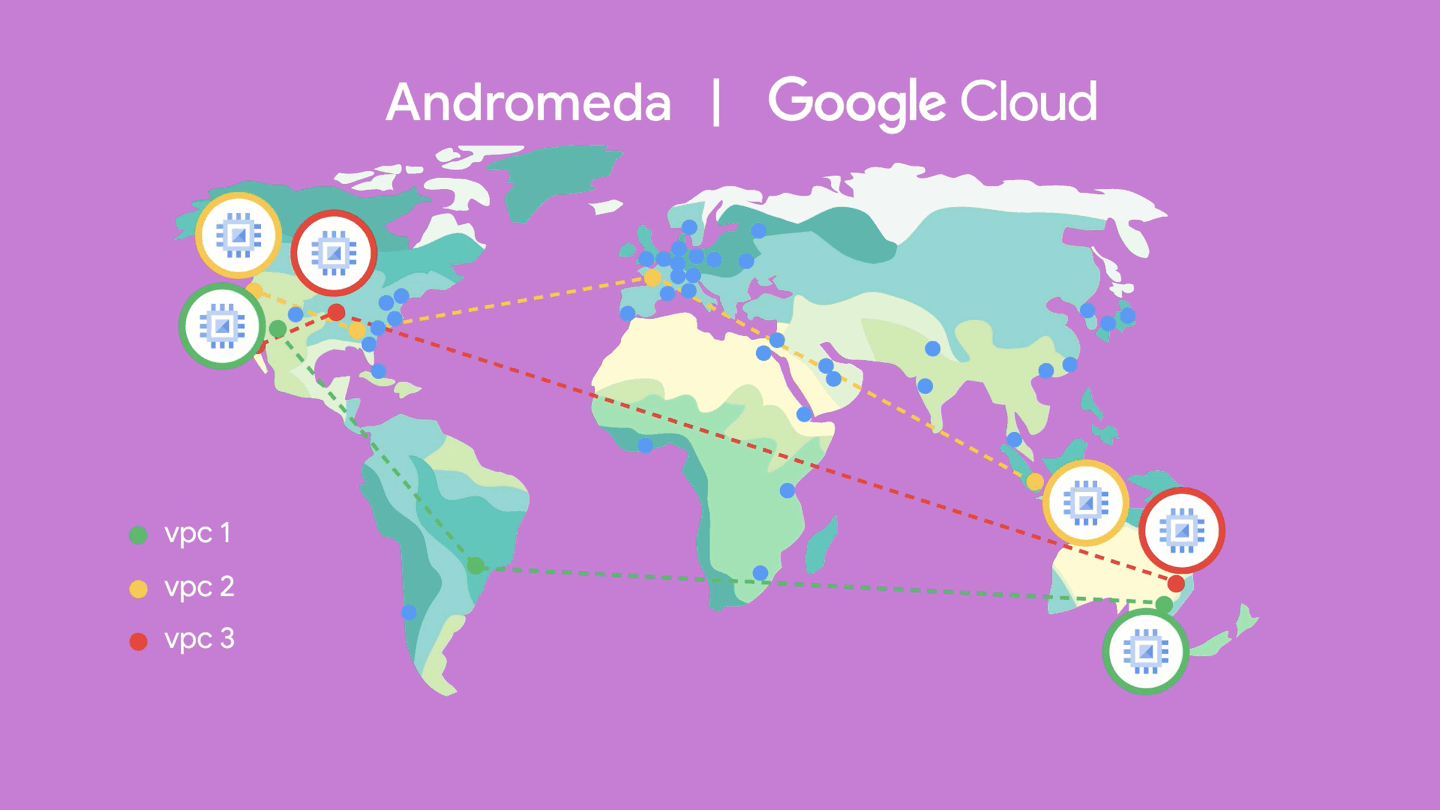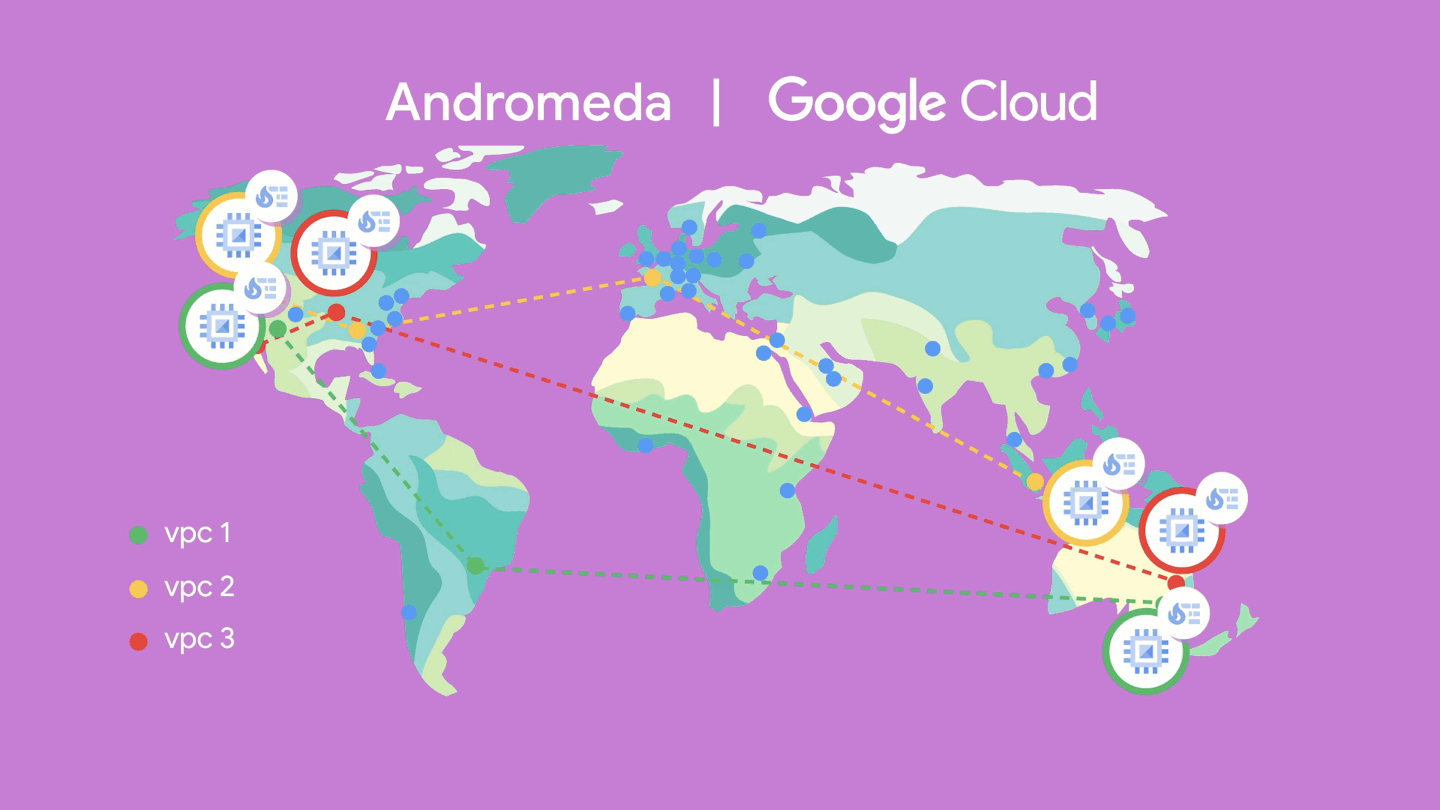
Whether you’re processing petabytes of data in seconds using BigQuery, running consistent databases across regions using Spanner, or autoscaling GKE clusters across zones, Google's global network backbone provides the capacity to get the job done.
It’s been a great journey to deep dive into how Google plans and builds its fiber optic cable network. Every engineer, project manager, and public policy expert I talked to exuded a passion to extend the global connectivity of the internet to the entire world (with Google Cloud being a major catalyst in this endeavor).
Be sure to check out more ways to catch a ride on the Google Cloud Premium Tier network.
Interested in championing Google Cloud technology with a chance to access exclusive events? Join Google Cloud Innovators.
Have thoughts about this article? Give me a shout @stephr_wong.