Databases on Google Cloud Part 4: Query, Index, CRUD and Crush your Java app with Firestore APIs

Abirami Sukumaran
Developer Advocate, Google
With Google Cloud Firestore, we can develop rich mobile, web and IoT applications using a fully managed, scalable, and serverless No-SQL document database that horizontally scales to meet any demand, with no maintenance. Some of my favorite features of Firestore besides the fact that it is fully managed, serverless and that it effortlessly auto scales up or down to meet any demand with no maintenance windows or downtime are that it has
1. Built-in live synchronization and offline mode that make it easy to build multi-user, collaborative applications2. A powerful query engine that allows you to run ACID-compliant transactions while providing flexibility in how you structure your data
3. High availability (99.99–99.999%) that we achieve through strongly consistent data replication
4. Pay as you go, with no up-front expenditure or underutilized resources
5. Simplified architecture that lets your apps talk directly to Firestore from your mobile or web clients
For other detailed features and documentation, refer to product documentation.
In this blog
I'll walk through setting up Firestore, creating complex queries and indexes, making the database calls for standard Create, Read, Update, and Delete (CRUD) operations using Firestore APIs on a Java Spring Boot application deployed on Cloud Run without using a Dockerfile. For this experiment, I have taken the use case of the “Yoga posture and breathing manager” database to achieve the CRUD and query (However the full implementation of the app’s use case is not in scope for this blog). Also we would cover in detail:
1. Demo of CRUD and query operations on a client app using Firestore APIs2. Collection and Sub Collection queries
3. Equality / Inequality queries
4. Single Field Index and Composite Index
5. Top Level Collection vs a Collection Group
Firestore Setup
The documentation has more complete steps on how to set up a Firestore instance. At a high level, to start out, I will follow these steps:
1. In the Google Cloud console, on the project selector page, select or create a Google Cloud project
2. Make sure that billing is enabled for your Cloud project. Learn how to check if billing is enabled on a project
3. Go to the Firestore Viewer and from the Select a database service screen, choose Firestore in Native mode
4. Select a location for your Firestore
5. Click Create Database
When you create a Firestore project, it also enables the API in the Cloud API Manager
6. Once it’s set up, you should see the Firestore Database, Collection and Document view in Native mode as seen in image below:

7. You could click “Start Collection” and create a new collection :
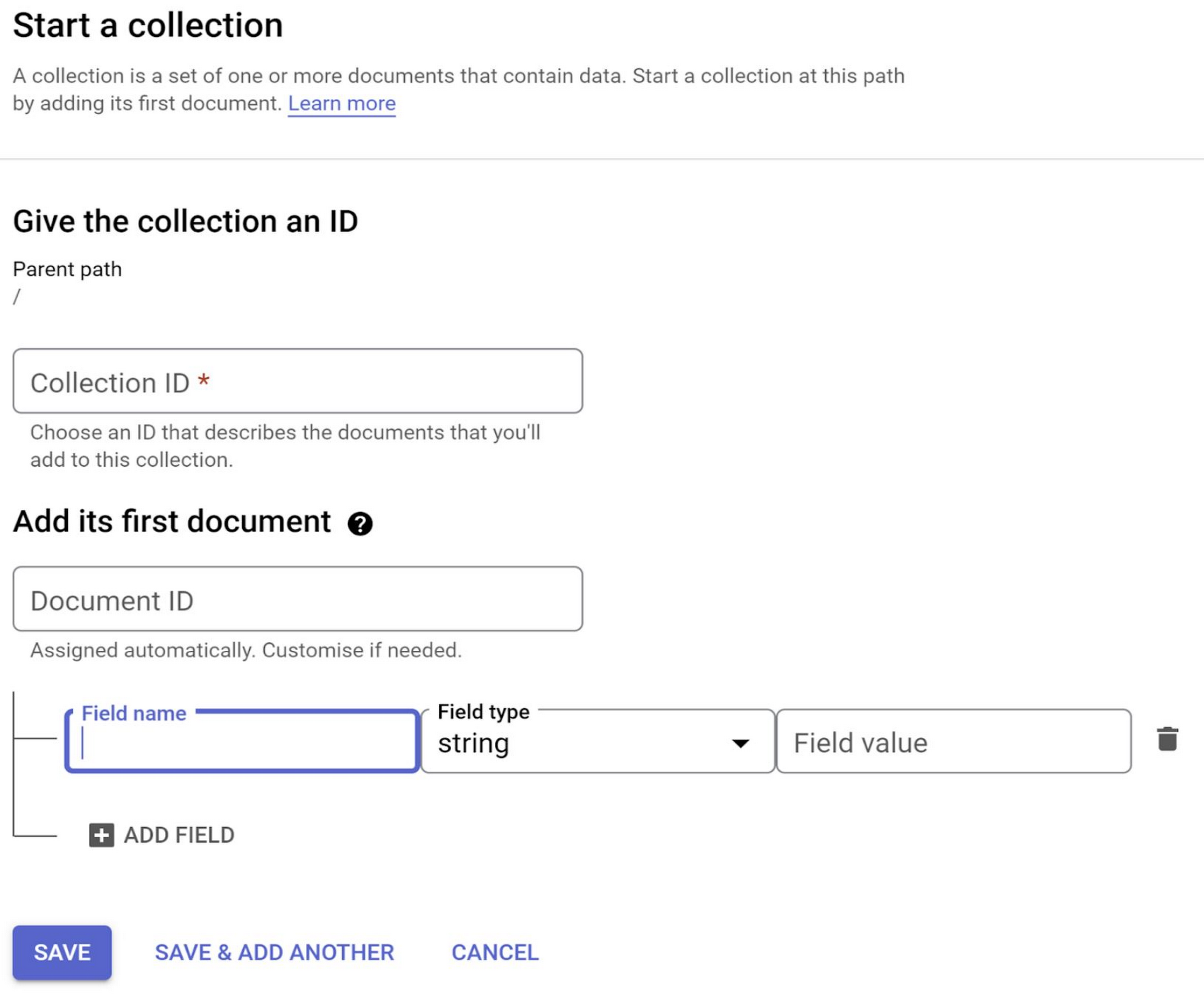
Pro-tip: Be sure to edit, monitor and test your security rules before deploying / rolling out the project from the development phase because it is often the silent culprit behind why your app is working differently :)
Firestore REST API
1. The REST API can be helpful for the following use cases:
a. Accessing Firestore from a resource-constrained environment where running a complete client library is not possibleb. Automating database administration or retrieving detailed database metadata
2. The easiest way to use Firestore is to use one of the native client libraries, there are some situations when it is useful to call the REST API directly
3. In the scope of this blog, you will see usage and demonstration of Firestore REST APIs and not native client libraries
4. For authentication, the Firestore REST API accepts either a Firebase Authentication ID token or a Google Identity OAuth 2.0 token. For more information on the Authentication and Authorization topic, refer to the documentation
5. All REST API endpoints exist under the base URL https://firestore.googleapis.com/v1/
Spring Boot and Firestore API on Cloud Run
This solution in Spring Boot Framework is to demonstrate a client application that uses Firestore APIs to collect and modify Yoga posture and breath details with a user interactive experience.
The following diagram represents the high level architecture of this experiment:

- While Google Cloud can be operated remotely from your laptop, you'll use Cloud Shell, a command-line environment running in Google Cloud
- If not already, please follow the steps here to activate Cloud Shell, check you are already authenticated and set to your PROJECT_ID
- If, for some reason, the project is not set, simply issue the following command:
gcloud config set project <PROJECT_ID>
- From Cloud Shell, enable Cloud Run API:
gcloud services enable run.googleapis.com
git clone https://github.com/AbiramiSukumaran/firestore-project
2. Bootstrapping Spring Boot Java Client App
- From the Cloud Shell environment, use the following command to initialize and bootstrap a new Spring Boot application:
$ curl https://start.spring.io/starter.tgz -d packaging=jar -d dependencies=cloud-gcp,web -d baseDir=firestore-project -d bootVersion=2.3.3.RELEASE | tar -xzvf -$ cd firestore-project
Use this command if you are not cloning the repo. This will create a new firestore-project/ directory with a new Maven project, along with Maven's pom.xml, a Maven wrapper and an application entrypoint
- In the pom.xml file, add the Spring boot starter, web and other dependencies you will need
- In application.properties, configure Firestore database connection information:
../firestore-project/src/main/resources/application.properties
spring.cloud.gcp.firestore.project-id=<<Project Id>>
spring.cloud.gcp.firestore.credentials.location=file:{PATH_TO_YOUR_CREDENTIALS_FILE}
- Build the app:
./mvnw package - Create the entity class at
../firestore-project/src/main/java/com/example/demo/Pose.java -- The PoseController.java class contains the methods that invokes the Firestore REST APIs for GET, PATCH, DELETE, RUNQUERY methods to route to the HTML pages, perform CRUD operations and some Server side validations:
1. Method to invoke API that searches a given document (Search by Pose Name)
showPose(Pose pose)
2. Method to invoke API that creates a new pose with breathing and posture details (Patch - create / update)
createPose(Pose pose)
3. Method to invoke API that edits (Patch - create / update)
editPose(Pose pose)
The “toString()” method overload will come in handy when you try to patch as it requires a JSON request body for the Pose class.
4. Method that is invoked on delete pose call (Delete by Pose Name)
deletePose(Pose pose)
5. Method that is invoked on RunQuery API call (Run your own structured query)
runQuery(Pose pose)
You can see more about this RunQuery usage in the Query section and API section of this blog.
- Thymeleaf is a server-side Java template engine for both web and standalone environments. Its main goal is to bring elegant natural templates to your development workflow — HTML that can be correctly displayed in browsers and also work as static prototypes, allowing for better collaboration in development teams. The ../templates folder contains the Thymeleaf templates for the CRUD HTML pages (View Layer) in the location
../firestore-project/src/main/resources/templates/
3. Build & Run
./mvnw package./mvnw spring-boot:run4. Containerize your app without Dockerfile!
- With Jib, you can containerize your app in an optimized way without Dockerfile / daemon and publish to any container registry
- Before proceeding, you need to activate the Container Registry API. This only needs to be done once per project to make the API accessible:
$ gcloud services enable containerregistry.googleapis.com- Run Jib to build a Docker image and publish to Container Registry
$ ./mvnw com.google.cloud.tools:jib-maven-plugin:3.1.1:build \-Dimage=gcr.io/$GOOGLE_CLOUD_PROJECT/<<your-container-name>>
- Note: In this experiment, we did not configure the Jib Maven plugin in pom.xml, but for advanced usage, it is possible to add it in pom.xml with more configuration options
- Check if the image is successfully published by going to the Cloud Console, clicking the Navigation menu, and selecting Container Registry
5. Deploy it on Cloud Run
Run the following command to deploy your containerized app to Cloud Run:
gcloud run deploy <<application>> --image gcr.io/$GOOGLE_CLOUD_PROJECT/<<container>> --platform managed --region us-central1 --allow-unauthenticated --update-env-vars DBHOST=$DB_HOST
- –allow-unauthenticated will let the service be reached without authentication
- –platform-managed means you are requesting the fully managed environment and not the Kubernetes one via Anthos
- –update-env-vars expects the Connection String to be passed on to the environment variable DBHOST
- When the deployment is done, you should see the deployed service URL in the command line
Watch the logs as your app is shipped to the cloud! When the deployment is complete, you should see the URL for the client app. Open the URL and play CRUD with your application. Also access the “Run Your Own Query” link to experiment your supported queries with Cloud Firestore.
Collection, Collection Group, Composite Index and Queries
Unlike a SQL database, there are no tables or rows. Instead, you store data in documents, which are organized into collections.
- A document is a lightweight record that contains fields, which map to values (key-value pairs)
- Complex, nested objects in a document are called map
- Documents are lightweight JSON records (documents support extra data types and are limited in size to 1 MB)
- Documents can contain subcollections and nested objects, and can include primitive fields or complex objects like lists
In our experiment, we have a Yoga Pose as a document with fields “Breath” and “Posture” as seen in image below:

- Documents live in collections, which are simply containers for documents
- A collection contains documents and nothing else. It can't directly contain raw fields with values, and it can't contain other collections
- If either the collection or document does not exist, Cloud Firestore implicitly creates it
- A subcollection is a collection associated with a specific document
- Subcollections allow you to structure data hierarchically and you can nest data up to 100 levels deep

- A database index maps the items to their locations. If no index exists for a query, most databases search contents item by item which becomes slower as the database grows. Cloud Firestore guarantees high query performance by using indexes for all queries. As a result, query performance depends on the size of the result set and not on the number of items in the database
- The indexes required for the most basic queries are automatically created for you
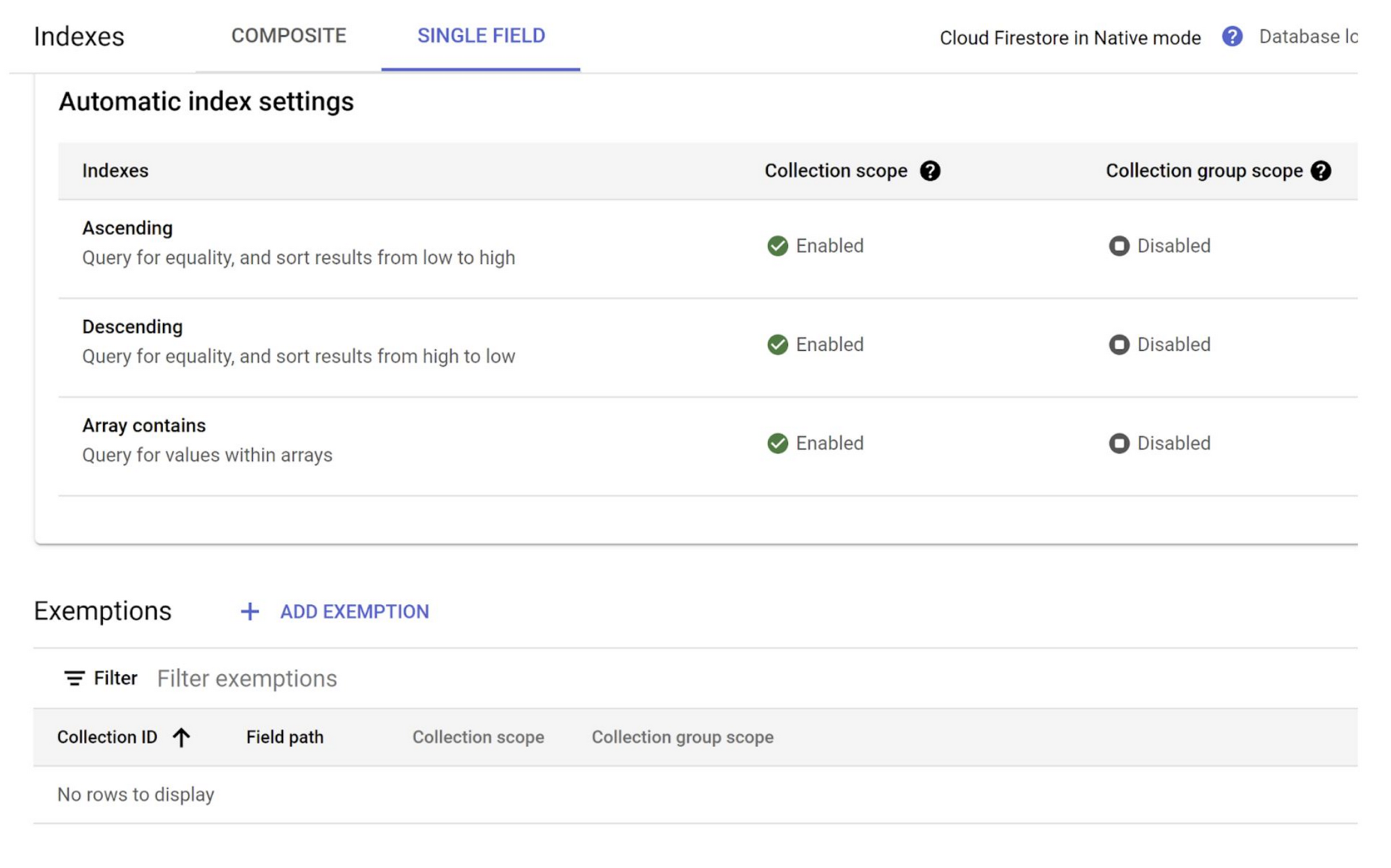
- Cloud Firestore uses two types of indexes: Single-field and Composite:
Single-field Index:
- Sorted mapping of all the documents in a collection that contain a specific field
- By default Cloud Firestore automatically maintains single-field indexes for each field in a document and each subfield in a map
- You can exempt a field from your automatic indexing settings by creating a single-field index exemption (An indexing exemption overrides the database-wide automatic index settings)
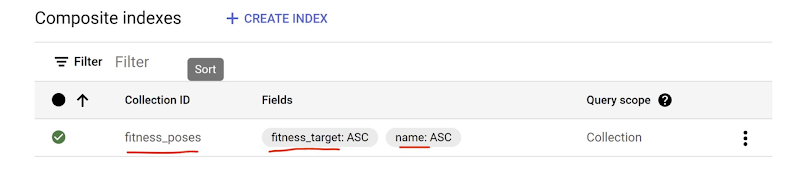
Composite Index:
- Sorted mapping of all the documents in a collection based on an ordered list of fields to index
- It does not automatically create composite indexes because of the large number of possible field combinations. Instead, it helps identify and create required composite indexes as you build your app
- You can see these 2 types in images below. Single indexes automatically created for non-map fields in ascending, descending direction and for array-contains queries
- Composite indexes that were custom created for one of the queries I opted for my application which involved the combination of fields - name, breath and posture:
4. Collection Group Query and Index
- Collection Group structure refers to the hierarchical structure in which there are nested collections, documents and sub collections for those documents and so on and so forth
Query Request Body:
- Querying these Collection Groups is enabled through “Collection Group Indexes”
- When you create a query and run the application without having the required index in place, Firestore will fail your request with an error code 400 but will provide a link to create the index automatically. Please see screenshot image below:
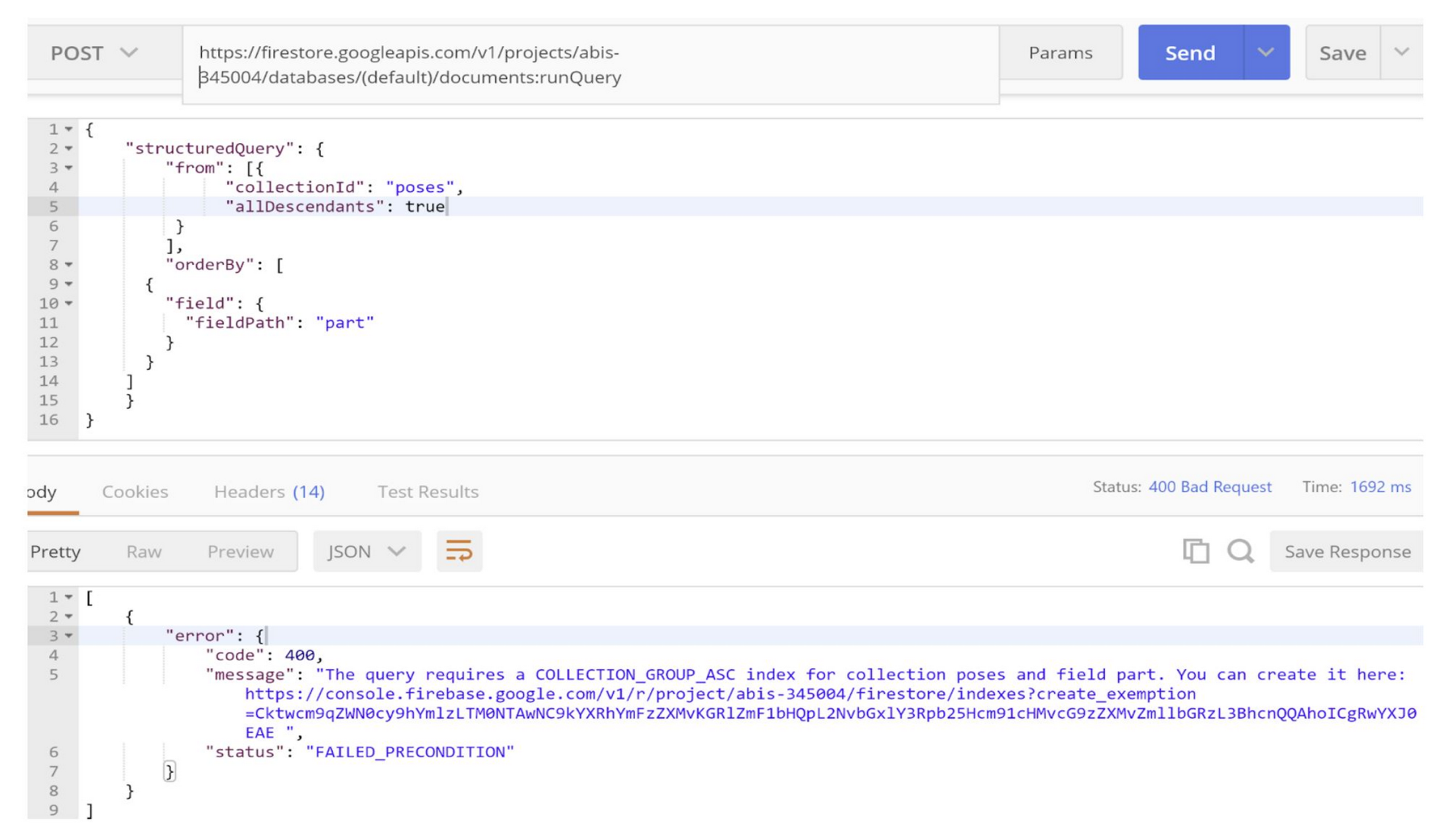
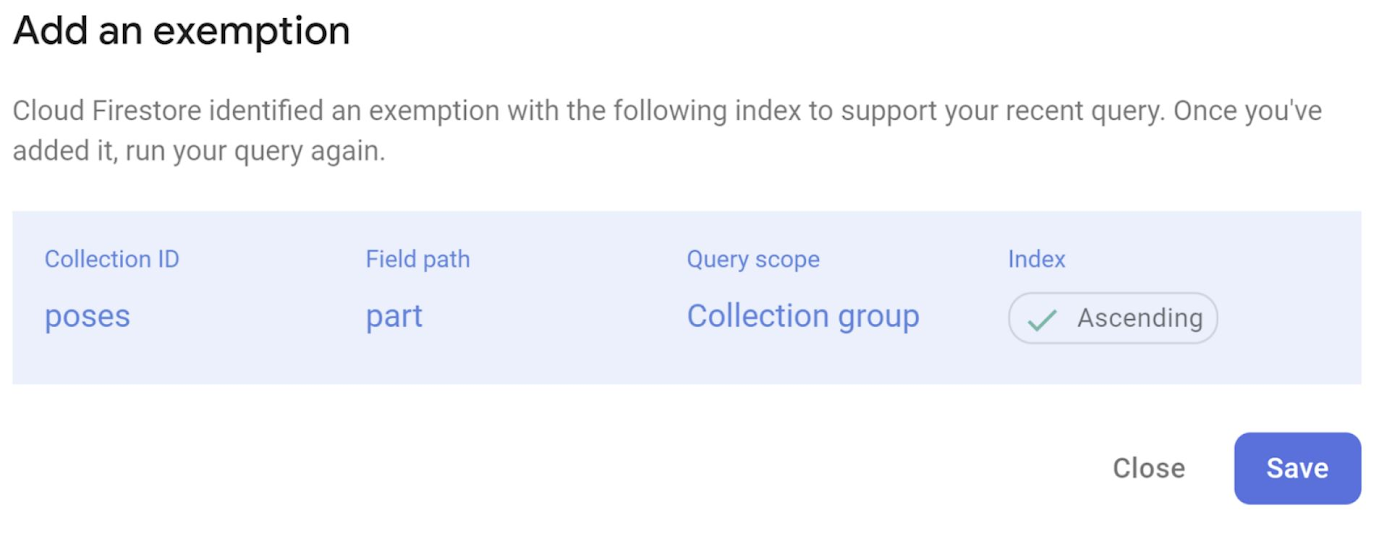
- When you click the link, you are able to create the index (in this example, as a single-index exemption)
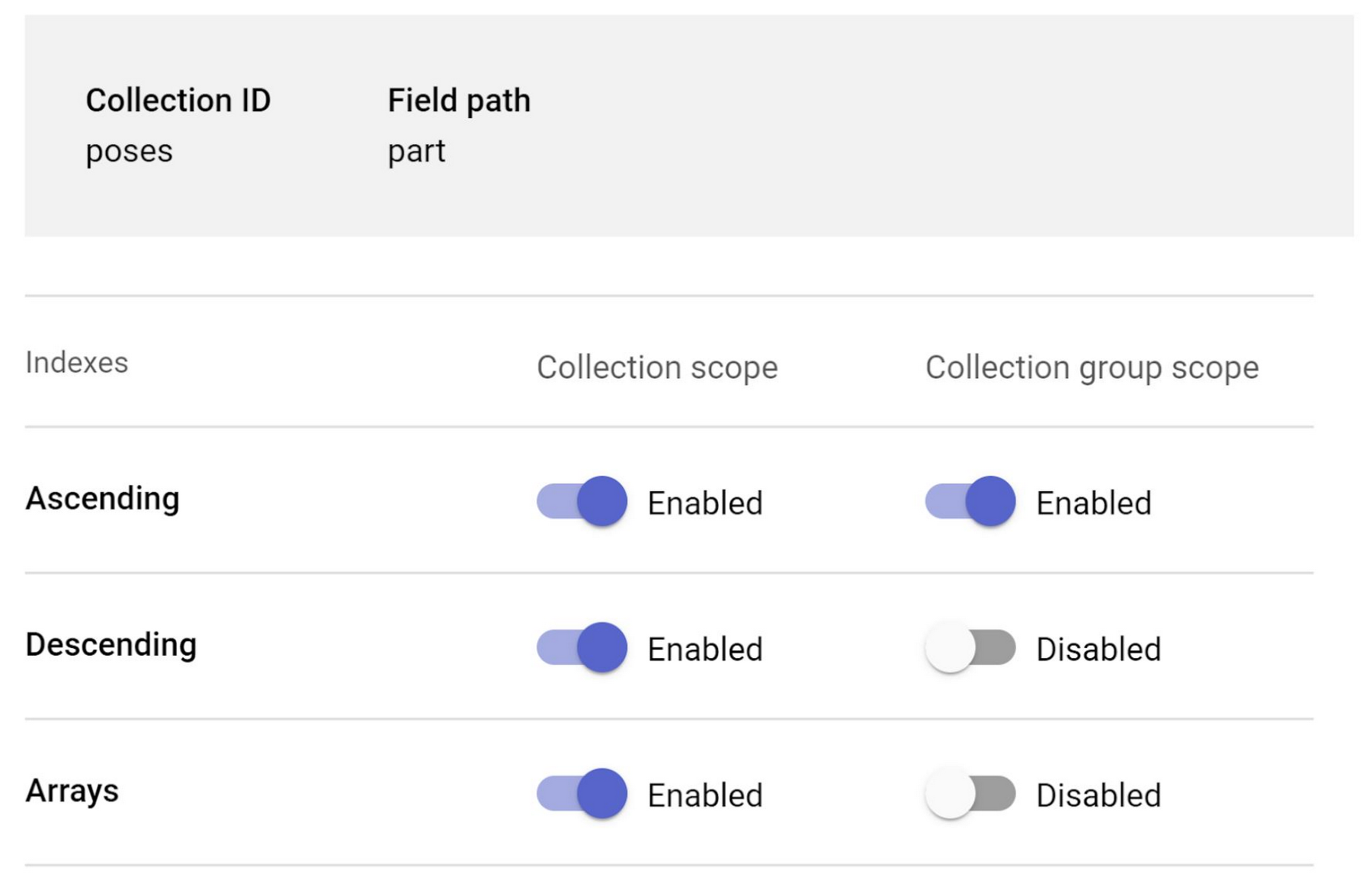
- Once you hit save, you should be able to see the index getting created:
5. Data Model Choice: Collection Group (Hierarchical) vs. Top Level Collection
It’s natural to question why you should go for a Collection Group (hierarchical) way of storing data and not store it in a “Top Level Collection” format. To define Top Level Collection format - it is the equivalent of storing data in a denormalized style in a Relational Database Management System (in my opinion). The answer is here. It is for 2 reasons:
- Ease of query / access for scenarios where you are ordering data across more than 1 field within a document and its own subcollection
- Also, from a security rules standpoint, it's fairly common to restrict child documents based on some data that exists in their parent, and that's significantly easier to do when you have data set up in subcollections
In our experiment here, I tried to compare the hierarchical (subcollection) structure with a denormalized (Top Level Collection) model, and I feel comfortable with the latter because I like to do a lot of cross-joins (accessing multiple fields across documents and subcollections).
- Firestore provides powerful query functionality for specifying which documents you want to retrieve from a collection or collection group
- In the scope of this blog we are looking at querying using the Firestore API RunQuery Method
- This method allows you to run your query with the structured query format input
URL:
POST
https://firestore.googleapis.com/v1/{parent=projects/*/databases/*/documents}:runQuery
- “parent” is an API parameter with value in the format:
“projects/{project_id}/databases/{databaseId}/documents”- There are a few JSON Request body attributes:
- Structured Query is where you actually specify your query in the HTTP request
- The structure of the Structured Query is:
- The fields / attributes in “from” clause are:
- The attributes of the “where” clause contains:
object (FieldReference) - The field to filter by.
op
enum (Operator) - The operator to filter by.
value
object (Value) - The value to compare to.
- The operators supported can be referenced from this link
- Sample simple JSON Input body for the RunQuery method (from our experiment):
My favorite Firestore gotchas…
- For creating indexes, it is best to just try to run the query in the code and let the request fail with the 400 error so you can follow the link to generate the index in Firestore
- When you are designing / planning for your data model always think about what kind of situations you would be querying documents for the most and if it is too hard to figure, get started intuitively
In Firestore, queries, filtering and ordering are indexed by default, so query performance is proportional to the size of your result set, not your data set. This means that the time it takes to search through your dataset of 1 Billion records and extract result set is same as the time it takes to search through a dataset of 1 thousand records
Zig-zag merge joins are joins that jump back and forth between two (or more) indexes sorted by document ID, it finds matches between the ids to improve query performance without having to rely on a composite index
Zig Zag merges are great as they conveniently allow you to coalesce results from different indexes without having to create a composite index. Be aware that if both your indexed result sets are large but their overlap is small, then you may run into performance issues. This is where you manually create Composite indexes for such fields to improve performance of your query. You can learn more about it here.
Make sure to check your Security Rules configuration from the Firebase interface while trying to access and provision access for data
Before you go…
I hope you enjoyed this little experiment with Firestore API on Spring Boot with Dockerless Containers deployed on Cloud Run. I have deliberately taken an exception to implement this Springboot framework experiment with Firestore REST APIs just to play around with the APIs even though it is not a restricted environment (like IoT scenario in which case I cannot actually implement the Firestore client library). Why don’t you try out the same experiment with Firestore client libraries for Spring Boot framework?
The below code labs and references can come in handy for your implementation:
https://firebase.google.com/docs/firestore/quickstart
https://firebase.google.com/codelabs/firestore-web?hl=en#7
https://cloud.google.com/firestore/docs/reference/libraries#java_1
https://codelabs.developers.google.com/codelabs/cloud-kotlin-jib-cloud-run#4
https://codelabs.developers.google.com/codelabs/cloud-run-hello#4



