BigQuery Write API explained: An overview of the Write API
Stephanie Wang
Senior Developer Relations Engineer
Google BigQuery Write API was released to general availability in 2021 and is BigQuery’s preferred data ingestion path which offers high-performance batching and streaming in one unified API. Since its inception, numerous features and improvements have been made to improve performance and usability, making it easier for users to directly ingest data into BigQuery. Some exciting capabilities on top of the unification aspect include:
Ingesting data directly to BigQuery without having to stage it in Google Cloud Storage which simplifies your workflows.
Stream processing data and immediately reading it, which enables you to build low-latency, fast-response data applications.
Guaranteeing exactly-once delivery, which ensures that you don't have to write custom deduplication logic.
Supporting row batch-level transaction, which allows for safe retries and schema update detection.
In this first post, we will delve into these new features and explore how the BigQuery Write API compares to the other existing data ingestion methods in BigQuery, and how you can quickly get started with it.
Ingesting data into BigQuery
There are several ways to ingest data into BigQuery’s managed storage. The specific ingestion method depends on your workload. Generally, for one-time load jobs and recurring batch jobs, where batch latency is not a concern, you can use the BigQuery Data Transfer Service or BigQuery Load Jobs. Otherwise, the BigQuery Write API is the recommended way to ingest data.
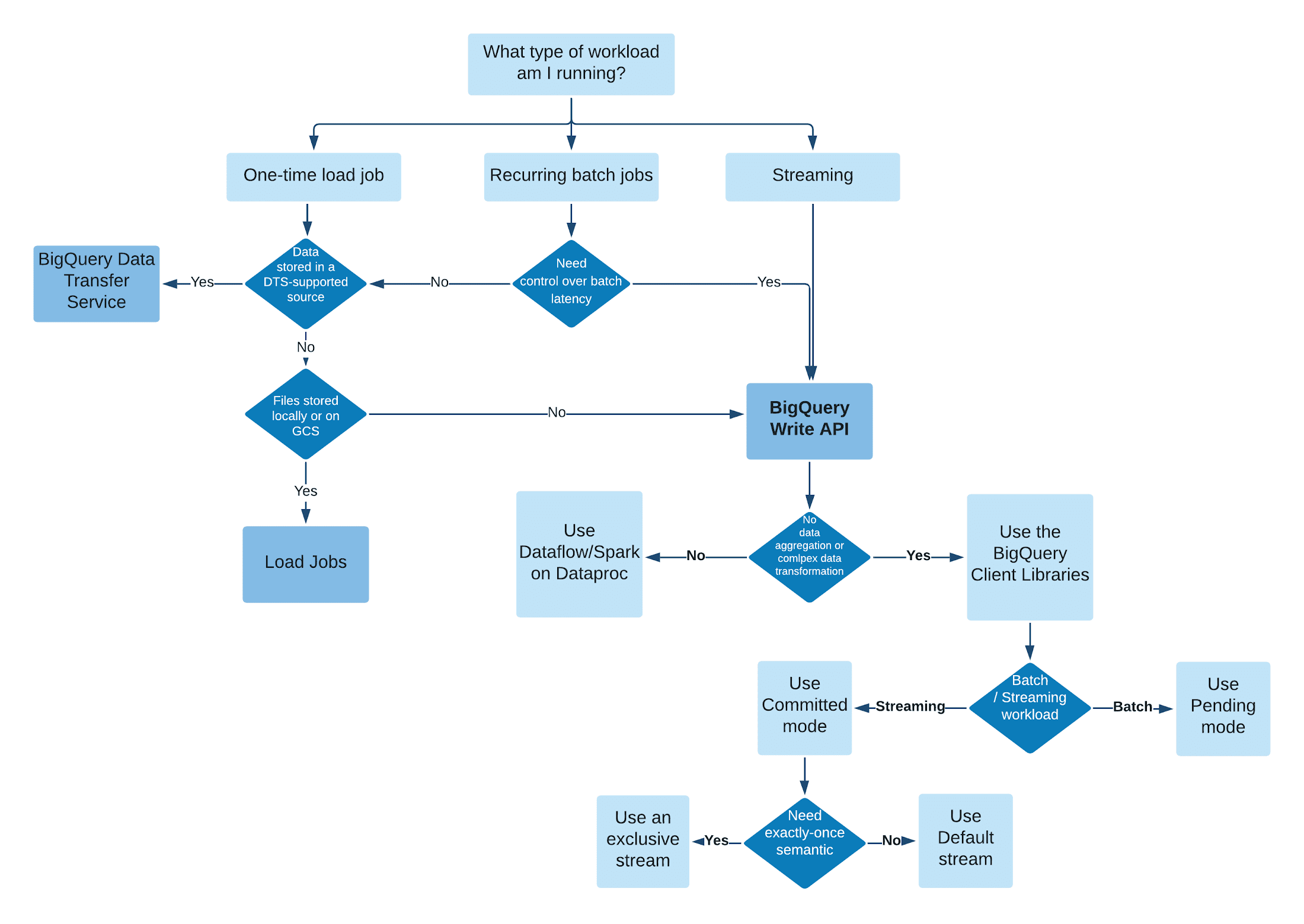
Before the BigQuery Write API, there were two ways to ingest data into BigQuery: via a BigQuery Load job or the legacy Streaming API.
Load
BigQuery Load jobs are primarily suited for batch-only workloads that ingest data from Google Cloud Storage into BigQuery. BigQuery Data Transfer Service uses Load under the hood but allows you to transfer data from more sources other than Google Cloud Storage and to run batch loads on a schedule. However, because Load is a batch mode insert, jobs can take a long time to run and ingestion performance is proportional to the allocated compute resources (see BigQuery Reservation). In other words, Load jobs don't allow you to ingest data directly from your data source into BigQuery with low latency.
Compared to BigQuery Load jobs, the BigQuery Write API provides:
Stream level transaction: One stream can only be committed once, which enables safe retries.
Simpler workflows: By writing directly to BigQuery storage, you can avoid exporting your data to Google Cloud Storage and then loading it into BigQuery.
SLO: The BigQuery Write API has the same level of SLO as other existing BigQuery APIs such as Query Jobs and the legacy Streaming API.
Legacy Streaming API
The legacy streaming API does provide you with the ability to ingest data in real-time with very low latency, but you are responsible for tracking insert status and if you retry, you may end up with duplicate records.
Compared to the legacy streaming API, the BigQuery Write API provides:
Write idempotency: The legacy streaming API only supports best-effort deduplication for a small period of time (order of a few minutes). The BigQuery Write API, however, ensures that one append can only happen once at a given offset on the same stream, therefore guaranteeing write idempotency.
Higher throughput: The Write API has three times more default quota (3 GB/s) compared to the legacy streaming API (1 GB/s), allowing higher throughput in data ingestion. Additional quota can be provisioned upon request.
Lower cost: 50% lower per GB cost compared to the legacy streaming API.
In addition, since the Write API supports unified batch and streaming, you will no longer need to use separate APIs to handle all of your workloads at scale.
Unified batch and streaming API powered by the new streaming backend
The Write API is backed by a new streaming backend that can handle much larger throughput with better data reliability compared to the old backend. The new backend is an exabyte scale structured storage system behind BigQuery, built to support stream-based processing for scalable streaming analytics across all analytic engines in GCP. Unlike its predecessor that is optimized for batch mode processing, the new streaming backend treats streaming as a first-class workload and supports high throughput real-time streaming and processing. It is a stream-oriented storage that allows exactly-once semantics and immediate data availability for queries.
How can you get started with the BigQuery Write API?
You can start using BigQuery Write API to stream data with high throughput by creating a StreamWriter and calling the append method on it. Here is an example of sending data in binary format over the wire in Java:
If your data is not stored in Protobuf format, you can use the client library’s JsonStreamWriter (currently provided in Java) to directly stream JSON data into BigQuery. In addition, this example provides at-least-once(instead of exactly-once) semantics because it uses the default Stream. Stay tuned to see how to achieve exactly-once semantics with Dataflow and the client library in later posts.
What’s Next?
In this article, we reviewed where BigQuery Write API fits in the data ingestion paths to BigQuery, what makes the BigQuery Write API fast and cheap, and how to get started with the BigQuery Write API. In upcoming posts, we will look at how to easily incorporate the BigQuery Write API in your data pipeline, some new key concepts that are critical to using the API, and new features!
Stay tuned. Thank you for reading! Have a question or want to chat? Find me on Twitter or LinkedIn.
Thanks to Gaurav Saxena, Yiru Tang, Pavan Edara, and Veronica Wasson for helping with the post.



