Agent Factory Recap: Reinforcement Learning and Fine-Tuning on TPUs

Shir Meir Lador
Head of AI, Product DevRel
In our agent factory holiday special, Don McCasland and I were joined by Kyle Meggs, Senior Product Manager on the TPU Training Team at Google, to dive deep into the world of model fine tuning. We focused specifically on reinforcement learning (RL), and how Google's own infrastructure of TPUs are designed to power these massive workloads at scale.
This post guides you through the key ideas from our conversation. Use it to quickly recap topics or dive deeper into specific segments with links and timestamps.

When to Consider Fine-Tuning
Timestamp: 3:13
We started with a fundamental question: with foundational models like Gemini becoming so powerful out of the box, and customization through the prompt can often be good enough, when should you consider fine-tuning?
Fine tuning your own model is relevant when you need high specialization for unique datasets where a generalist model might not excel (such as in the medical domain), or when you have strict privacy restrictions that require hosting your own models trained on your data.
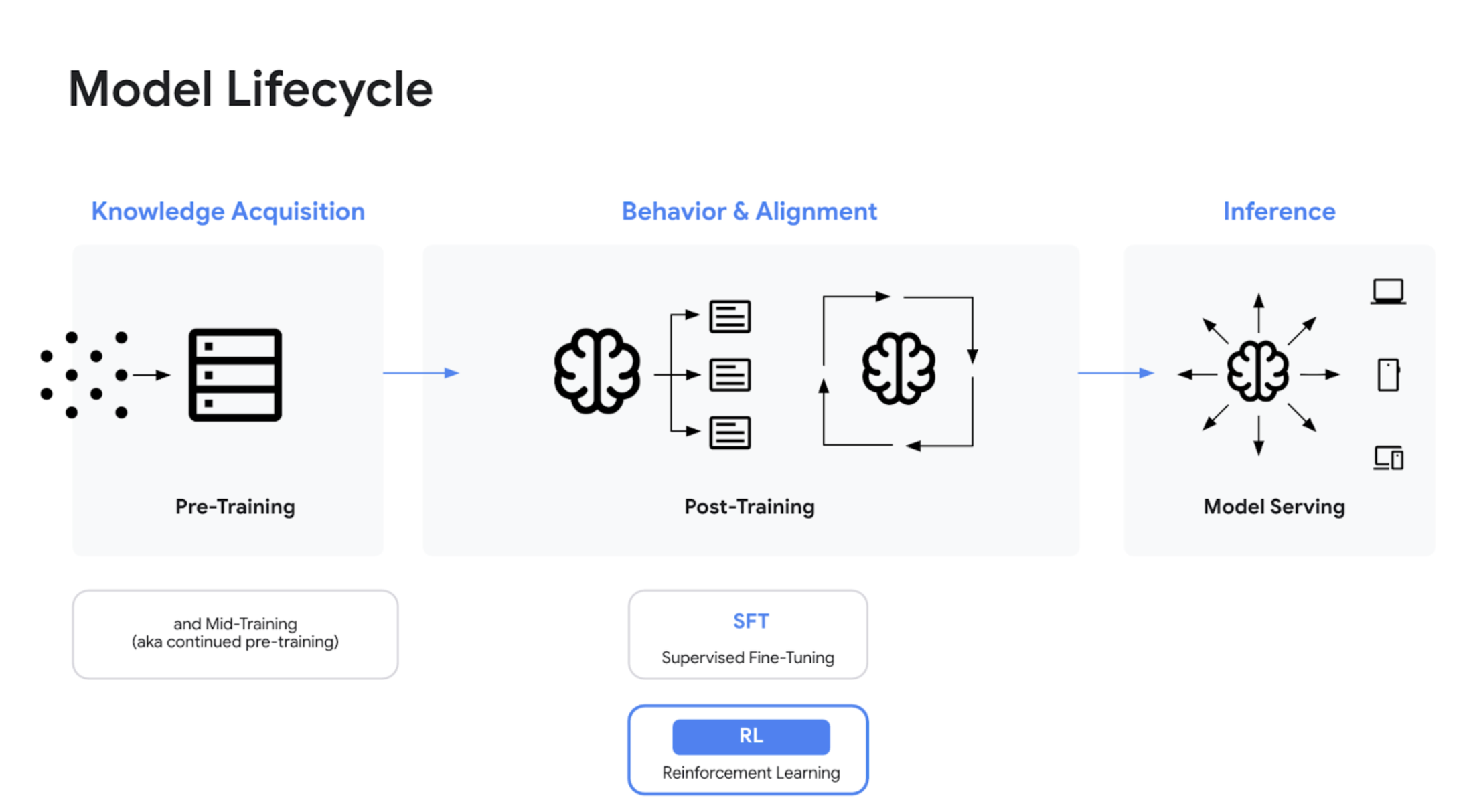
The Model Lifecycle: Pre-training and Post-training (SFT and RL)
Timestamp: 3:52
Kyle used a great analogy inspired by Andrej Karpathy to break down the stages of training. He described pre-training as "knowledge acquisition," similar to reading a chemistry textbook to learn how things work. Post-training is further split into Supervised Fine-Tuning (SFT), which is analogous to reading already-solved practice problems within the textbook chapter, and Reinforcement Learning (RL), which is like solving new practice problems without help and then checking your answers in the back of the book to measure yourself against an optimal approach and correct answers.
Why Reinforcement Learning (RL) is Essential
Timestamp: 5:50
We explored why RL is currently so important for building modern LLMs. Kyle explained that unlike SFT, which is about imitation, RL is about grading actions to drive "alignment." It’s crucial for teaching a model safety (penalizing what not to do), enabling the model to use tools like search and interact with the physical world through trial and error, and for performing verifiable tasks like math or coding by rewarding the entire chain of thought that leads to a correct answer.
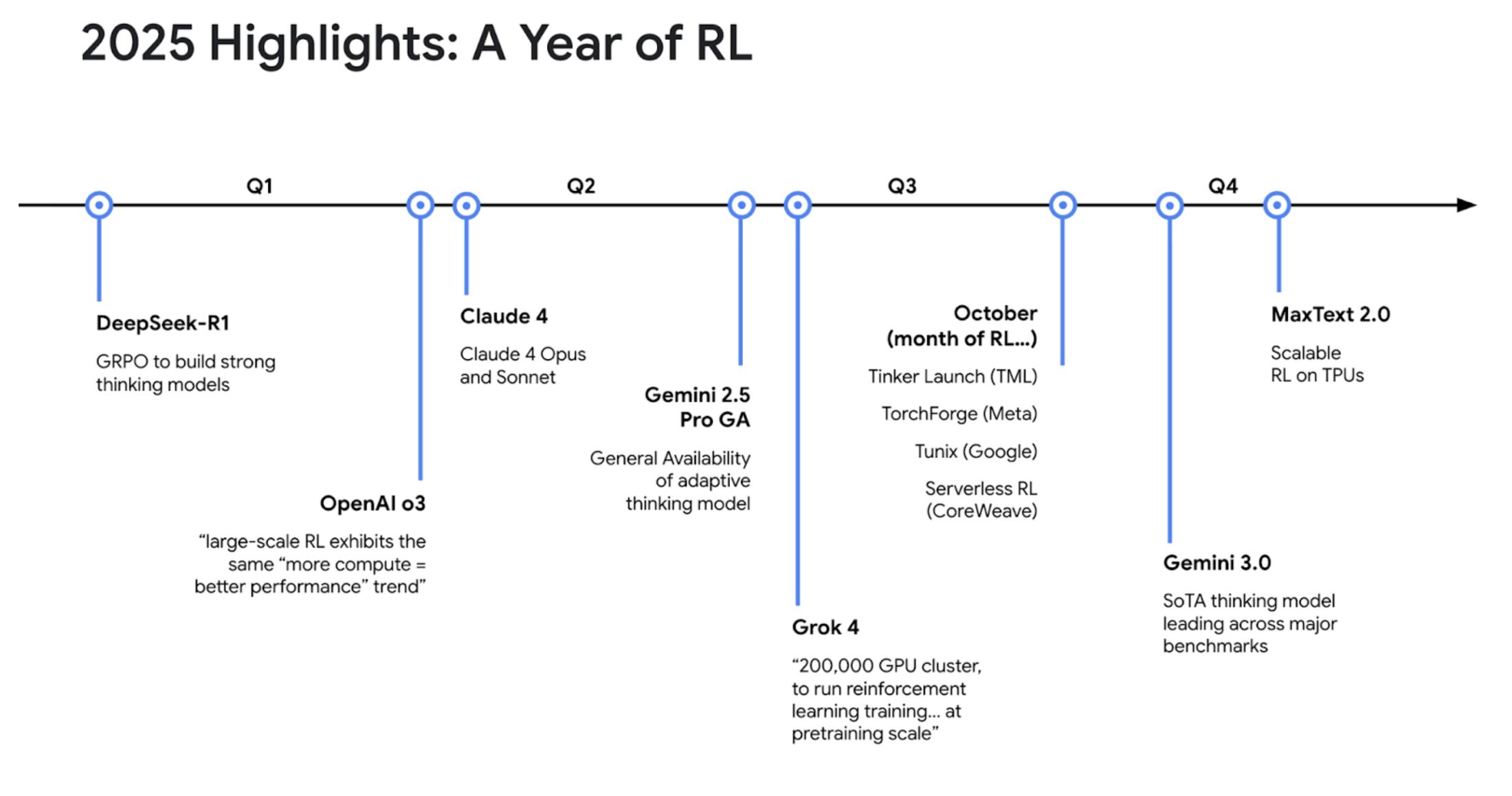
The Agent Industry Pulse: Why 2025 is the year of RL
Timestamp: 8:33
In this segment, we looked at the rapidly evolving landscape of RL. Kyle noted that it is fair to call 2025 the "year of RL," highlighting the massive increase in investment and launches across the industry:
-
January: DeepSeek-R1 launched, making a huge splash with open-source GRPO.
-
Summer: xAI launched Grok 4, reportedly running a 200k GPU cluster for RL at "pre-training scale."
-
October: A slew of new tooling launches across Google, Meta, and TML.
-
November: Gemini 3 launched as a premier thinking model.
-
Recent: Google launched MaxText 2.0 for fine-tuning on TPUs.
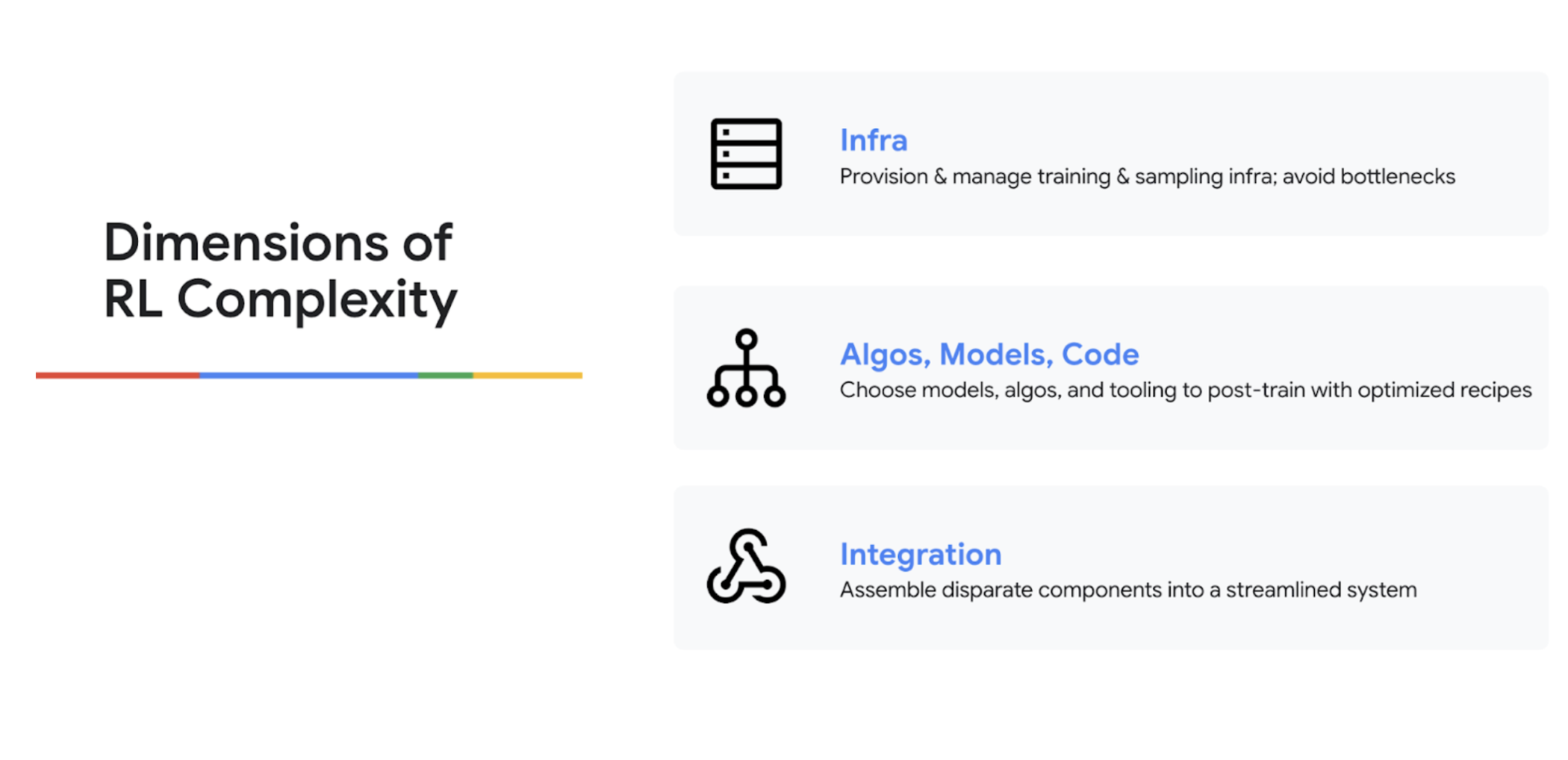
The Hurdles of Implementing RL
Timestamp: 10:46
Following the industry trends, we discussed why RL is so difficult to implement. Kyle explained that RL combines the complexities of both training and inference into a single process. He outlined three primary challenges: managing infrastructure at the right balance and scale to avoid bottlenecks; choosing the right code, models, algorithms (like GRPO vs. DPO), and data; and finally, the difficulty of integrating disparate components for training, inference, orchestration, and weight synchronization.
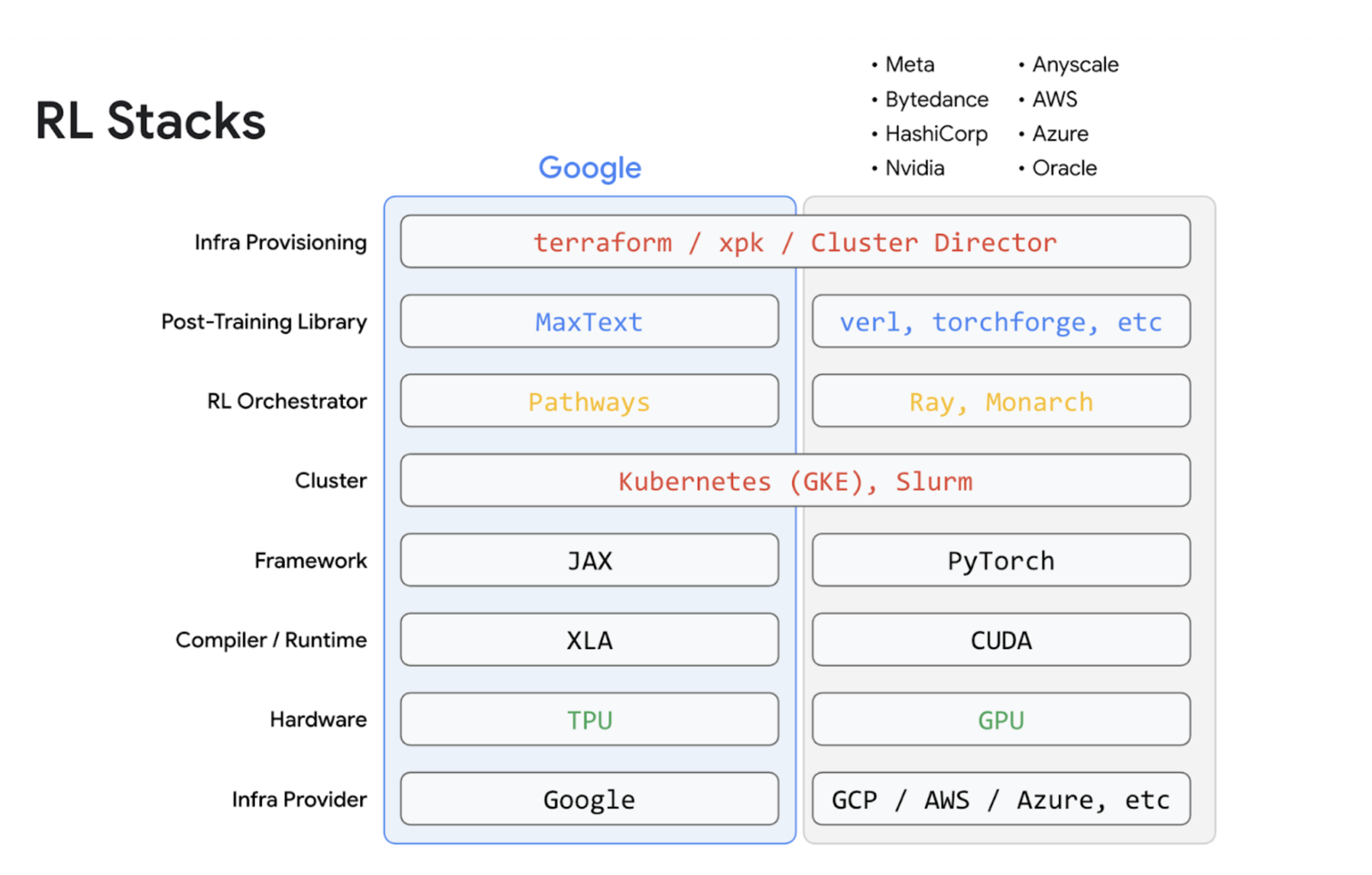
To provide a solution across these dimensions of complexity, Google offers MaxText, a vertically integrated solution to help you perform RL in a highly scalable and performant fashion. MaxText provides highly optimized models, the latest post-training algorithms, high performance inference via LLM, and powerful scalability/flexibility via Pathways.

In contrast to DIY approaches where users assemble their own stack of disparate components from many different providers, Google’s approach offers a single integrated stack of co-designed components, from silicon to software to solutions.
The Factory Floor
The Factory Floor is our segment for getting hands-on. Here, we moved from high-level concepts to practical code with a live demo.
Why TPUs Shine for RL
Timestamp: 12:52
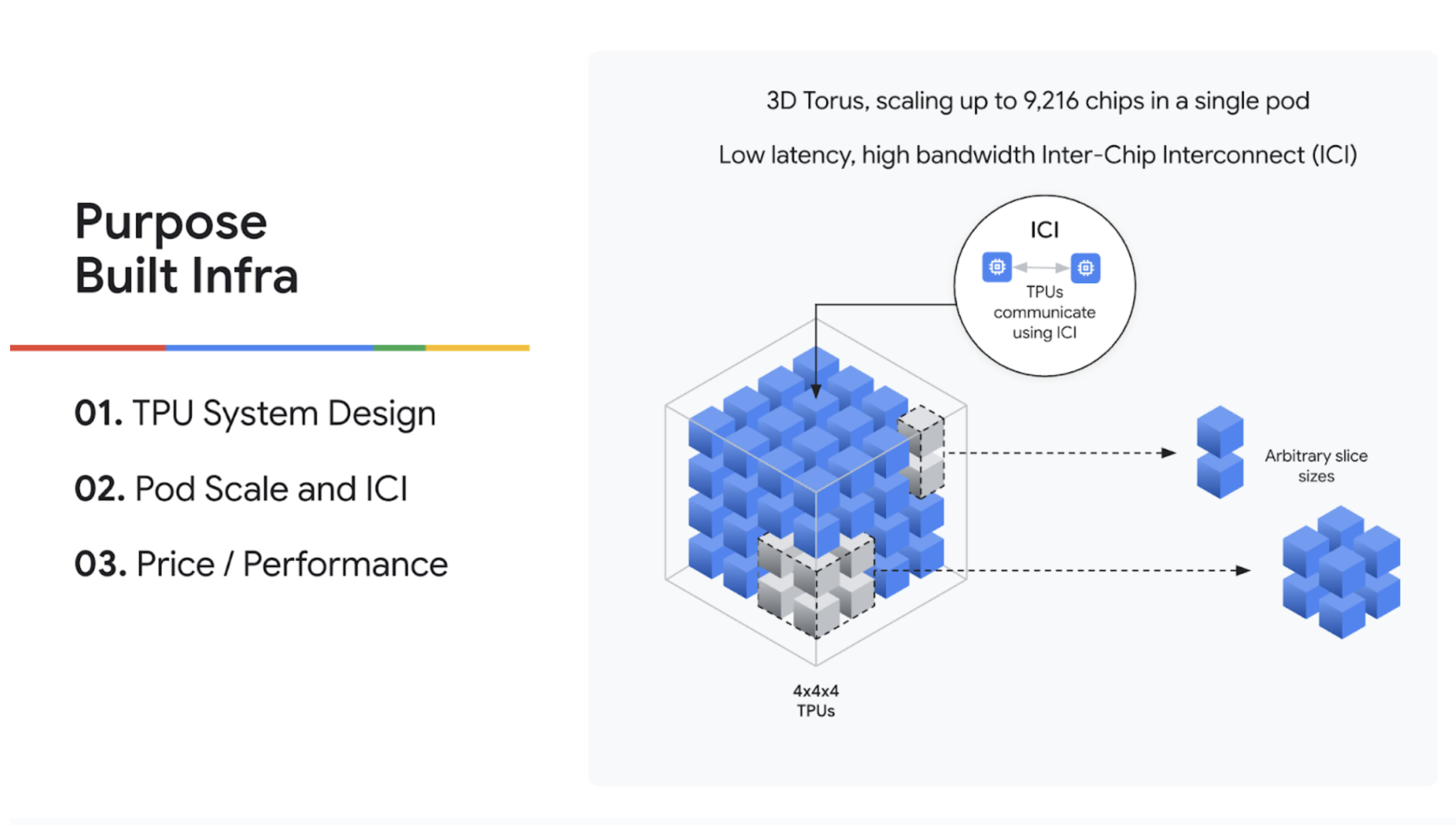
Before diving into the demo, Kyle explained why TPUs are uniquely suited for complex AI workloads like RL. Unlike other hardware, TPUs were designed system-first. A TPU Pod can connect up to 9,216 chips over low-latency interconnects, allowing for massive scale without relying on standard data center networks. This is a huge advantage for overcoming RL bottlenecks like weight synchronization. Furthermore, because they are purpose-built for AI, they offer superior price-performance and thermal efficiency.
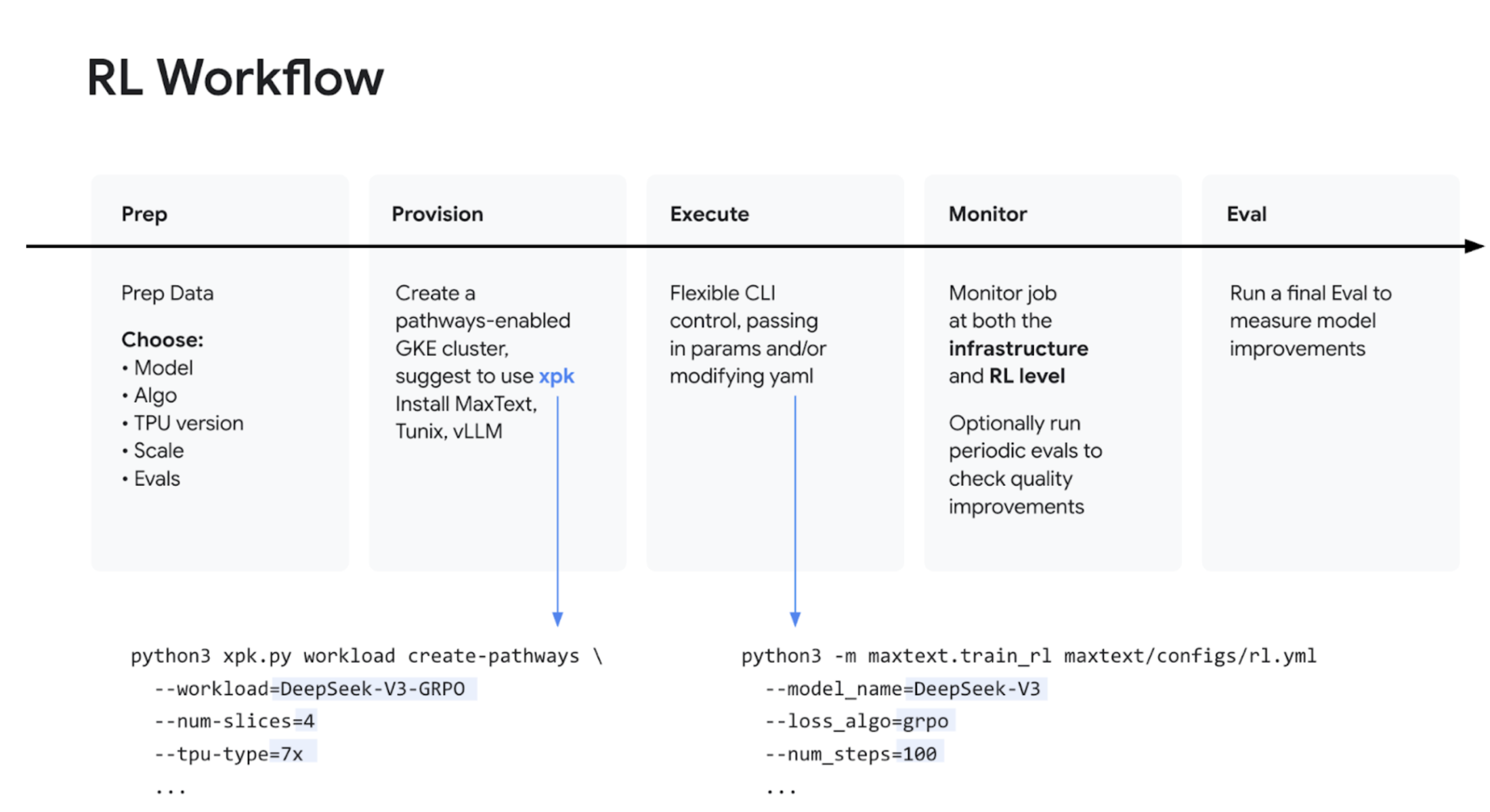
Demo: Reinforcement Learning (GRPO) with TPU
Timestamp: 15:53
Don led a hands-on demonstration showing what RL looks like in action using Google's infrastructure. The demo showcased:
-
Using MaxText 2.0 as an integrated solution for the workload.
-
Leveraging models from MaxText and algorithms from Tunix.
-
Handling inference using vLLM.
-
Utilizing Pathways for orchestration and scaling to run GRPO (Group Relative Policy Optimization).
Conclusion
This holiday special was a great deep dive into the cutting edge of model fine tuning. While foundational models are getting better every day, the future of highly specialized, capable agents relies on mastering post-training techniques like RL, and having the right vertically integrated infrastructure, like TPUs, to run them efficiently.
Your turn to build
We hope this episode gave you valuable tools and perspectives to think about fine-tuning your own specialized agents. Be sure to check out the resources below to explore MaxText 2.0 and start experimenting with TPUs for your workloads. We'll see you next year for a revamped season of The Agent Factory!
Resources
Post-Training Docs https://maxtext.readthedocs.io/en/latest/tutorials/post_training_index.html
-
Google Cloud TPU (Ironwood) Documentation: https://docs.cloud.google.com/tpu/docs/tpu7x
-
Google Cloud open source code:
-
GPU recipes - https://github.com/AI-Hypercomputer/gpu-recipes
-
TPU recipes - https://github.com/AI-Hypercomputer/tpu-recipes
-
Andrej Karpathy - Chemistry Analogy: Deep Dive into LLMs like ChatGPT
-
Paper: "Small Language Models are the Future of Agentic AI" (Nvidia): https://arxiv.org/abs/2506.02153
-
Fine tuning blog: https://cloud.google.com/blog/topics/developers-practitioners/a-step-by-step-guide-to-fine-tuning-medgemma-for-breast-tumor-classification?e=48754805
Connect with us
-
Shir Meir Lador → https://www.linkedin.com/in/shirmeirlador/, X
-
Don McCasland → https://www.linkedin.com/in/donald-mccasland/
-
Kyle Meggs → https://www.linkedin.com/in/kyle-meggs/



