New file checksum feature lets you validate data transfers between HDFS and Cloud Storage
Dennis Huo
Software Engineer, Google Cloud
Julien Phalip
Solutions Architect, Google Cloud
When you’re copying or moving data between distinct storage systems such as multiple Apache Hadoop Distributed File System (HDFS) clusters or between HDFS and Cloud Storage, it’s a good idea to perform some type of validation to guarantee data integrity. This validation is essential to be sure data wasn’t altered during transfer.
For Cloud Storage, this validation happens automatically client-side with commands like gsutil cp and rsync. Those commands compute local file checksums, which are then validated against the checksums computed by Cloud Storage at the end of each operation. If the checksums do not match, gsutil deletes the invalid copies and prints a warning message. This mismatch rarely happens, and if it does, you can retry the operation.
Now, there’s also a way to automatically perform end-to-end, client-side validation in Apache Hadoop across heterogeneous Hadoop-compatible file systems like HDFS and Cloud Storage. Our Google engineers recently added the feature to Apache Hadoop, in collaboration with Twitter and members of the Apache Hadoop open-source community.
While various mechanisms already ensure point-to-point data integrity in transit (such as TLS for all communication with Cloud Storage), explicit end-to-end data integrity validation adds protection for cases that may go undetected by typical in-transit mechanisms. This can help you detect potential data corruption caused, for example, by noisy network links, memory errors on server computers and routers along the path, or software bugs (such as in a library that customers use).
In this post, we’ll describe how this new feature lets you efficiently and accurately compare file checksums.
How HDFS performs file checksums
HDFS uses CRC32C, a 32-bit Cyclic Redundancy Check (CRC) based on the Castagnoli polynomial, to maintain data integrity in several different contexts:
- At rest, Hadoop DataNodes continuously verify data against stored CRCs to detect and repair bit-rot.
- In transit, the DataNodes send known CRCs along with the corresponding bulk data, and HDFS client libraries cooperatively compute per-chunk CRCs to compare against the CRCs received from the DataNodes.
- For HDFS administrative purposes, block-level checksums are used for low-level manual integrity checks of individual block files on DataNodes.
- For arbitrary application-layer use cases, the
FileSysteminterface definesgetFileChecksum, and the HDFS implementation uses its stored fine-grained CRCs to define such a file-level checksum.
For most day-to-day uses, the CRCs are used transparently with respect to the application layer, and the only CRCs used are the per-chunk CRC32Cs, which are already precomputed and stored in metadata files alongside block data. The chunk size is defined by dfs.bytes-per-checksum and has a default value of 512 bytes.
Shortcomings of Hadoop’s default file checksum type
By default when using Hadoop, all API-exposed checksums take the form of an MD5 (a message-digest algorithm that produces hash values) of a concatenation of chunk CRC32Cs, either at the block level through the low-level DataTransferProtocol, or at the file level through the top-level FileSystem interface. The latter is defined as the MD5 of the concatenation of all the block checksums, each of which is an MD5 of a concatenation of chunk CRCs, and is therefore referred to as an MD5MD5CRC32FileChecksum. This is effectively an on-demand, three-layer Merkle tree.
This definition of the file-level checksum is sensitive to the implementation and data-layout details of HDFS, namely the chunk size (default 512 bytes) and the block size (default 128MB). So this default file checksum isn’t suitable in any of the following situations:
- Two different copies of the same files in HDFS, but with different per-file block sizes configured.
- Two different instances of HDFS with different block or chunk sizes configured.
- Copying across non-HDFS Hadoop-compatible file systems
- https://wiki.apache.org/hadoop/HCFS
- (HCFS) such as Cloud Storage.
You can see here how the same file can end up with three checksums depending on the file system's configuration:
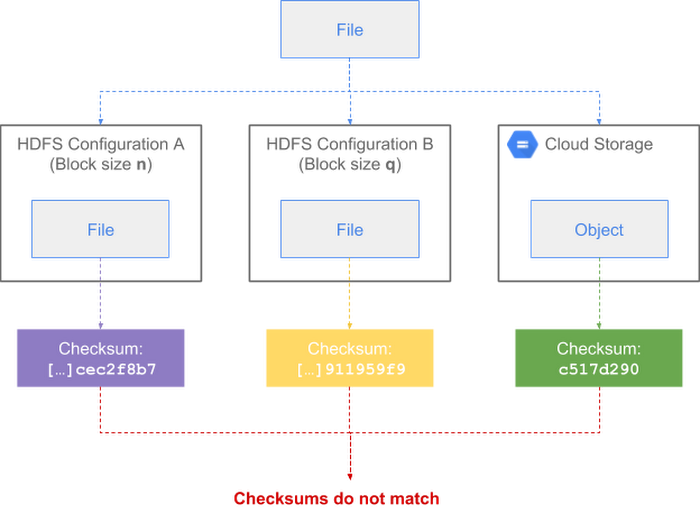
For example, below is the default checksum for a file in an HDFS cluster with a block size of 64MB (dfs.block.size=67108864):
And below, the default checksum for the same file in an HDFS cluster with a block size of 128MB (dfs.block.size=134217728):
You can see in the above examples that the two checksums differ for the same file.
Because of these shortcomings, it can be challenging for Hadoop users to reliably copy data from HDFS to the cloud using the typical Apache Hadoop Distributed Copy (DistCp) method. As a workaround for Twitter's data migration to Google Cloud, Twitter engineers initially modified DistCp jobs to recalculate checksums on the fly. While the workaround provided the desired end-to-end validation, the on-the-fly recalculation could cause a non-negligible performance strain at scale. So Joep Rottinghuis, leading the @TwitterHadoop team, requested that Google help implement a new comprehensive solution in Hadoop itself to eliminate the recalculation overhead. With this solution, there’s now an easier, more efficient way to perform this validation.
How Hadoop’s new composite CRC file checksum works
Our Google engineers collaborated with Twitter engineers and other members of the Hadoop open-source community to create a new checksum type, tracked in HDFS-13056 and released in Apache Hadoop 3.1.1, to address the above shortcomings. The new type, configured by dfs.checksum.combine.mode=COMPOSITE_CRC, defines new composite block CRCs and composite file CRCs as the mathematically composed CRC across the stored chunk CRCs. This replaces using MD5 of the component CRCs in order to calculate a single CRC that represents the entire block or file and is independent of the lower-level granularity of chunk CRCs.
CRC composition is efficient, allows the resulting checksums to be completely chunk/block agnostic, and allows comparison between striped and replicated files, between different HDFS instances, and between HDFS and other external storage systems. (You can learn more details about the CRC algorithm in this PDF download.)
Here’s a look at how a file's checksum is consistent after transfer across heterogenous file system configurations:

This feature is minimally invasive: it can be added in place to be compatible with existing block metadata, and doesn't need to change the normal path of chunk verification. This also means even large preexisting HDFS deployments can adopt this feature to retroactively sync data. For more details, you can download the full design PDF document.
Using the new composite CRC checksum type
To use the new composite CRC checksum type within Hadoop, simply set the dfs.checksum.combine.mode property to COMPOSITE_CRC (instead of the default value MD5MD5CRC). When a file is copied from one location to another, the chunk-level checksum type (i.e., the property dfs.checksum.type that defaults to CRC32C) must also match in both locations.
For example, below is the composite CRC checksum for a file in an HDFS cluster with a block size of 64MB (dfs.block.size=67108864):
And below, for the same file in an HDFS cluster with a block size of 128MB (dfs.block.size=134217728):
And below, for the same file in Cloud Storage:
When using the Cloud Storage connector to access Cloud Storage, as shown in the above example, you must explicitly set the fs.gs.checksum.type property to CRC32C. This property otherwise defaults to NONE, causing file checksums to be disabled by default. This default behavior by the Cloud Storage connector is a preventive measure to avoid an issue with DistCp, where an exception is raised if the checksum types mismatch instead of failing gracefully.
You can see that the composite CRC checksums returned by the above three commands all match, regardless of block size, as well as between HDFS and Cloud Storage. By using composite CRC checksums, you can now guarantee that data integrity is preserved when transferring files between all types of Hadoop cluster configurations.
Last, the validation is performed automatically by thehadoop distcp command:If the above command detects a file checksum mismatch between the source and destination during the copy, then the operation will fail and return a warning.
Accessing the feature and migrating Hadoop
The new composite CRC checksum feature is available in Apache Hadoop 3.1.1 (see release notes) and backports to versions 2.7, 2.8 and 2.9 are in the works. It is included by default in sub-minor versions of Cloud Dataproc 1.3 since late 2018.
For more details about Hadoop migration, check out our guide on Migrating On-Premises Hadoop Infrastructure to Google Cloud Platform.
Thanks to contributors to the design and development of this feature, in no particular order: Joep Rottinghuis, Vrushali Channapattan, Lohit Vijayarenu, and Zhenzhao Wang from the Twitter engineering team; Xiao Chen, Steve Loughran, Ajay Kumar, and Aprith Agarwal from the Hadoop open-source community; Anil Sadineni and Yan Zhou, partner engineers from the Google Cloud Professional Services.


