Announcing new storage features to help ensure data is never lost
Guru Pangal
VP and GM Storage, Google Cloud
Brian Schwarz
Director Product Management
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialData is a company’s most important input and asset and one of the most critical tasks is protecting it. At the same time, customers tell us they wish it were easier to get the right level of protection for their data. That can be hard to do, whether your data is on-premises or in the cloud. For example, configuring synchronous replication on-prem for a tier-one application requires you to set up, manage and monitor both networking and storage. Additionally, many organizations struggle to extend the standard protection policies they have in place for VMs to container infrastructure.
Today, we are adding extensions to our popular Cloud Storage offering, and introducing two new services, Filestore Enterprise, and Backup for Google Kubernetes Engine (GKE). Together, these new capabilities will make it easier for you to protect your data out-of-the box, across a wide variety of applications and use cases.
“Enterprise customers want to spend less time managing storage,” said Matt Eastwood, Senior Vice President, Enterprise Infrastructure and Cloud, IDC. “Although public cloud is growing fast, it is still new in many organizations, and skill gaps are something we know slows cloud adoption. It is great to see Google Cloud focusing on ease of use as they bring new services to market.”
Extending Cloud Storage dual-region buckets
One of Cloud Storage’s most important features is dual-region and multi-region buckets. Relying on technologies such as Colossus and Spanner, Cloud Storage dual-region buckets enable what we like to call a “continent-sized storage system”—a true single namespace (a.k.a. bucket) that spans regions. A dual-region bucket is not a simple load balancer or access point in the network tier sitting on top of two independent buckets. It is a true single namespace bucket, active-active for read/write/delete, which offers some important strong consistency properties. As a result, developers can treat a continent like a single bucket, dramatically simplifying the application programming model. Google Cloud is unique in offering this capability among major public cloud vendors.
As our customers are aware, it's super easy to create a dual-region bucket. Setting up a dual-region bucket is a simple matter of selecting the dual-region option when you first create it:
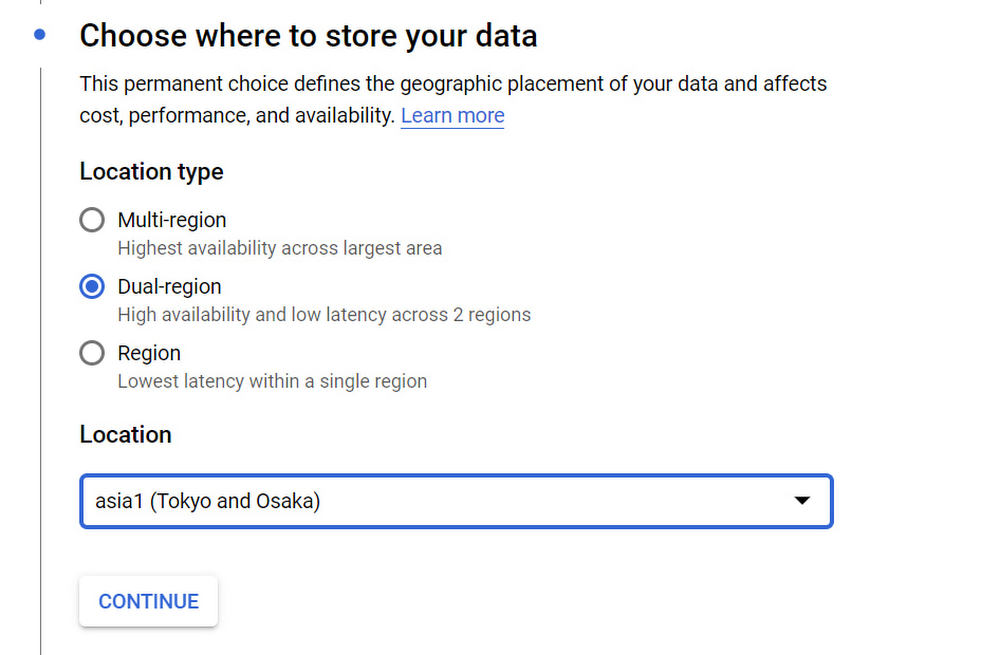
Today we are extending our dual-region buckets in two important ways:
Custom region selection for dual-region buckets - Previously, Google Cloud assigned dual region pairs for you to choose from. In an upcoming release, you’ll be able to select your own region pairs that meet your regulatory or compliance requirements, or optimize your app performance. Are you a financial company working with market data in Frankfurt and London? West coast US media firm that wants to use Los Angeles and Las Vegas? All this will be possible with this new capability.
Optional SLA-backed 15 min Recovery Point Objective (RPO) - Object storage is increasingly being used for important applications that can’t tolerate any data loss. Getting 99% of your data back after a regional outage just doesn’t cut it. We are excited to announce Turbo Replication for dual-region buckets, which replicates 100% of your data between regions in 15 minutes or less, backed by a Service Level Agreement, a first from a leading cloud provider.
To learn more about your data locality options, check out this guide to Cloud Storage bucket locations.
New Backup for GKE protects data in containers
Google Cloud users continue to adopt GKE in droves, benefitting from the greater application-development velocity it provides. And they’re no longer just running stateless applications in containers; they’re also running databases such as MySQL and PostgreSQL inside containers, as well as other stateful workloads. To help further accelerate this trend, we introduced Backup for GKE, a new native GKE service that makes it easier to protect your critical container-based data.
To learn more about Backup for GKE and how customers such as Broadcom and Atos are using it, check out the dedicated blog.
Filestore Enterprise offers protection from zonal outages
Filestore Enterprise is a brand new member of the fully managed Filestore family targeted at traditional tier-one enterprise applications (e.g., SAP) that need to share files. In addition to high-performance reads and writes, Filestore Enterprise offers high availability via synchronous replication across multiple zones in a region. When any zone within the region becomes unavailable, Filestore continues to transparently serve data to the application without any operational intervention.
To find out more about Filestore Enterprise and hear how Sabre is using it for their SAP deployment and their stateful GKE apps, check out this blog.
Data protection is in our DNA
Here at Google Cloud, we take data protection very seriously, and we’ll continue to focus on using Google’s global technology platform to give you powerful and easy-to-use capabilities to solve your most pressing storage challenges.
To learn more about Google Cloud’s family of storage and data protection products, register for our October 6th webinar: What's New with Storage at Google Cloud, and attend Google Cloud Next ‘21.



