A Cloud Run service was slow, here’s how we fixed it
Valentin Deleplace
Developer Advocate
During a stress test, an app became slow with high response times, to the point where it was almost unresponsive. Let’s find out why!
I helped Nexuzhealth debug a performance issue in their Go app on Cloud Run. Nexuzhealth is a Belgian healthcare IT company that makes medical record management better and more efficient for everyone. This makes a great difference for patients who receive care from multiple providers.
Running a stress test upfront really paid off, as they successfully detected the anomaly and now they had an opportunity to fix it before hitting production. The root cause was not obvious, so we started to investigate together. My name is Valentin Deleplace, and I was happy to help a customer succeed with serverless on Google Cloud.
Reproducing the issue was straightforward: every time we launched the load test with a few hundred requests, we consistently observed degraded response times. The app uses autoscaling, and whenever a new server instance was starting, the service became slow and unresponsive for dozens of seconds. The requests were handled much slower than expected. What was really going on here?
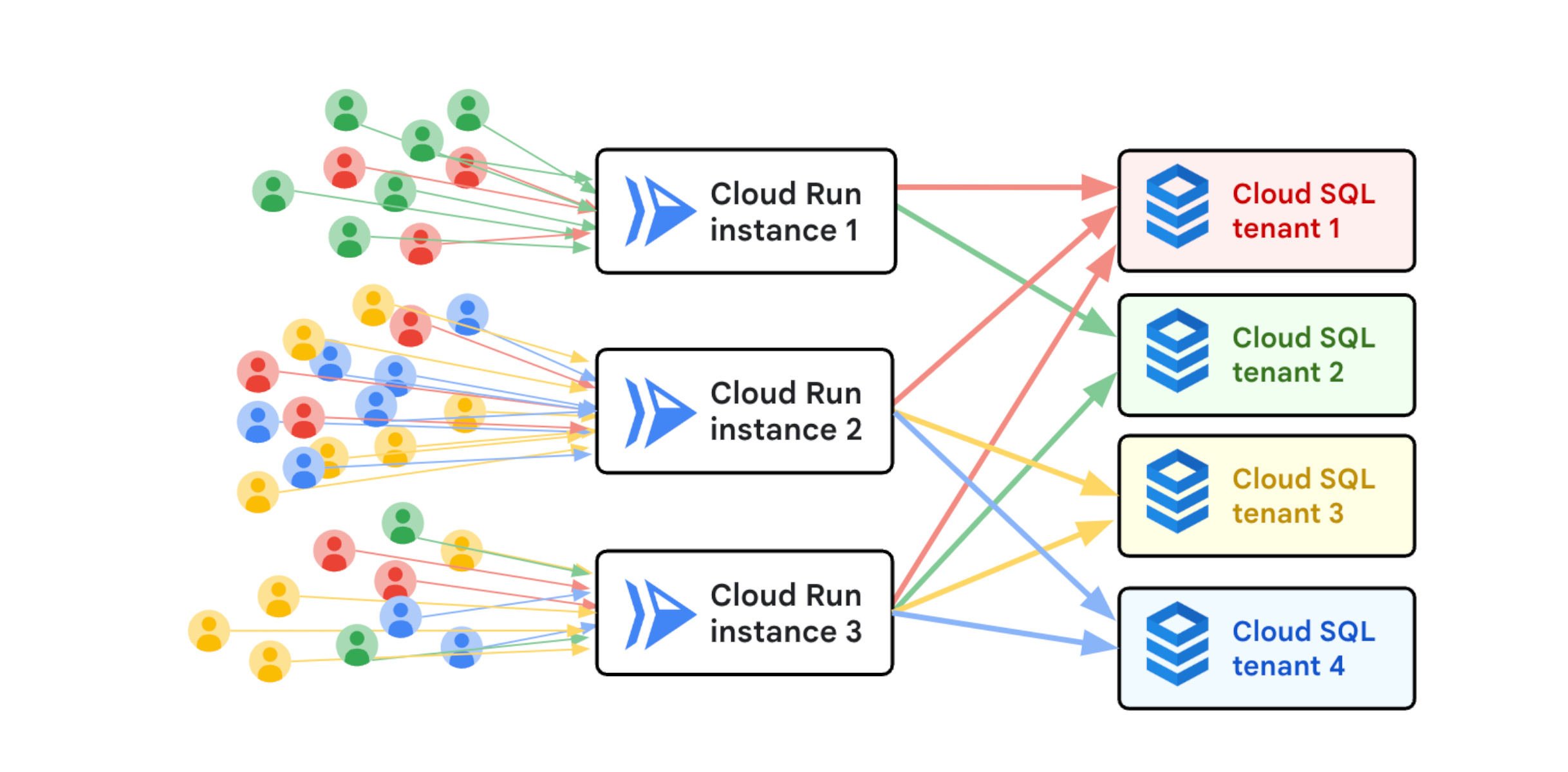
To investigate the performance problem, we had server logs and metrics, and we had the application source code. The server logs contained all the requests with timestamps, and some information about connecting to the appropriate database for each request. We discovered that the app was spending a lot of time establishing connections to various databases. The database instance could be different for each request because of multi-tenancy.
The same Nexuzhealth app is used to access data from many tenants, who include medical laboratories and pharmacies. Each tenant’s data is strongly isolated from the other tenants, in its own database, as shown here:
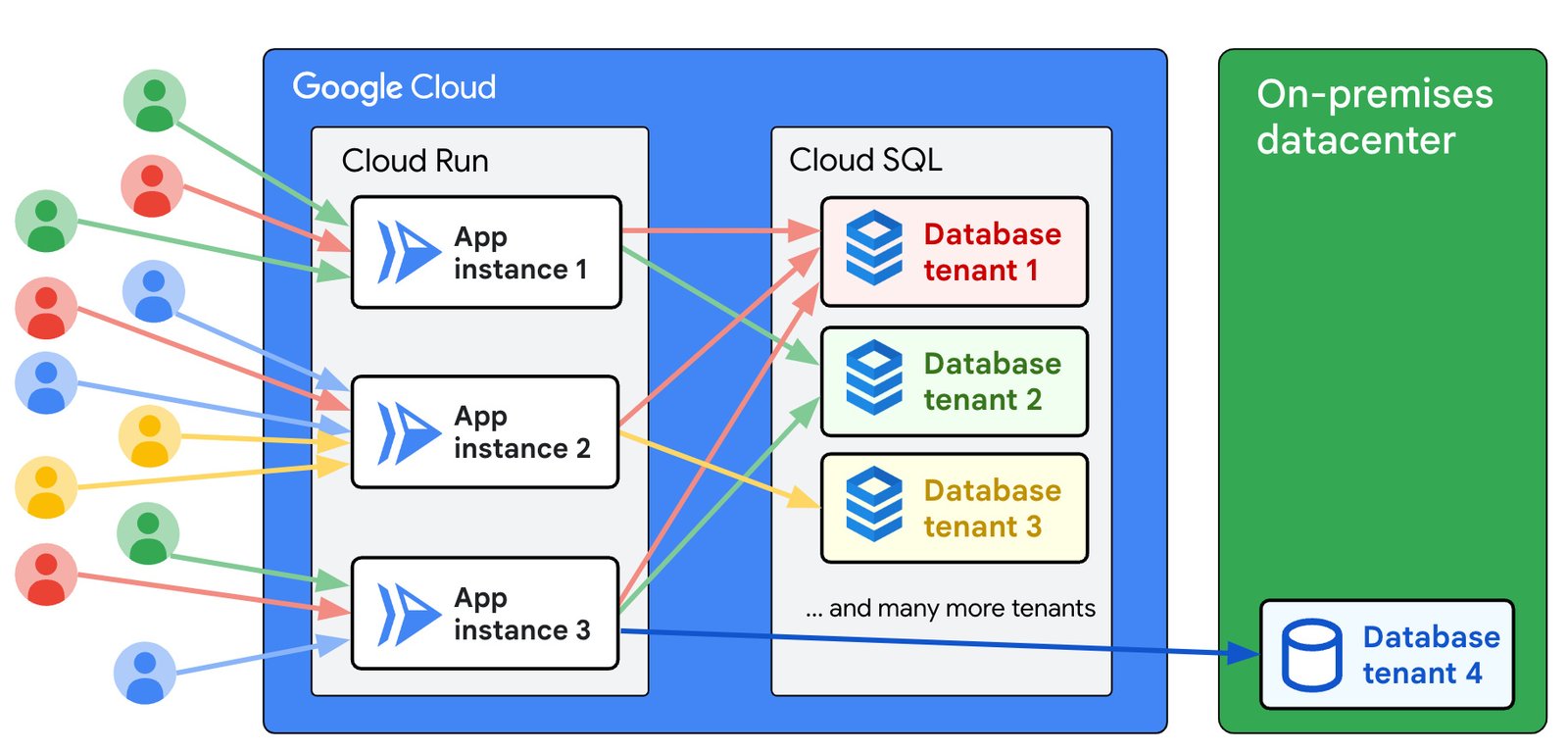
A multi-tenant application
Cloud Run is a fully-managed platform that starts containers on-demand to handle incoming traffic. The app instances need to connect to many database instances.
We reviewed the source code for areas where the request handler decides to establish a new database connection, or to reuse an existing connection stored in the local instance state.

For each user request, the code checks if the current app instance is already connected to the appropriate tenant database. If not, it creates a new connection. This is called lazy initialization.
When an application is starting, it faces a choice: should it connect to the database immediately (eager initialization), or wait for the first incoming user request (lazy initialization)? This question is important when your app uses autoscaling in Cloud Run or in Google Kubernetes Engine (GKE), because new instances will be frequently started.
In general I prefer eager initialization, because it improves responsiveness. When the first request is processed, the database is already connected. This saves a few hundreds of milliseconds in response time for that first request.
For the Nexuzhealth case with multi-tenancy, lazy initialization is more appropriate. It makes sense for the server to connect to the database on-demand, and save on startup latency which is important for autoscaling speed.
We expected the connection to each tenant database to be created only once by every app instance, and then be reused in subsequent requests for the same tenant. We didn’t see any errors or abnormal messages in the logs.
With this algorithm, the app works correctly but has very bad performance whenever a new instance is started. What’s going on? Let’s take a closer look at the code snippet again.
The dbmap data structure is shared by many threads that handle requests. When dealing with shared state in an app instance that handles many requests concurrently, we must ensure proper synchronization to avoid data races. This code uses an RW Lock. But there are two problems with the pseudo code above.
First, the slowest operation is createConnection() which may take over 200ms. This operation is executed while holding the RW lock in write mode, which means that at most one database connection can be created concurrently by the server. That might be suboptimal, but it was not the root cause of the performance issue.
Second, and more importantly, there is a TOCTOU problem in the code above: between reading the map and creating the connection, the connection may have been already created by another request. This is a race condition!
Race conditions can be rare and difficult to reproduce. In this case the problem was occurring every time, because of an unfortunate succession of events:
- The application is serving traffic.
- More traffic arrives, increasing the load of the server instances.
- The autoscaler triggers the creation of a new instance.
- As soon as the instance is ready to handle HTTP requests, many requests are immediately routed to the new instance. They sound like a thundering herd!
- Several requests read the empty map, and create a db connection.
- Only one single request acquires the lock in write mode, and needs roughly 200ms to create a database connection before releasing the lock again.
- During that time, all other requests are blocked, waiting to acquire the lock.
- When a second (or subsequent) request finally gets the lock in write mode, it is unaware that the map has changed (it already checked that the map was empty), and it creates its own new, redundant connection.
All the requests were doing a long operation, and were effectively waiting on each other, which explains the high latencies we observed. In the worst case, the app may be opening so many connections that the database server would start refusing them.
Solution
A possible solution was to check the map again just after acquiring the lock in write mode, which is an acceptable form of double-checked locking.
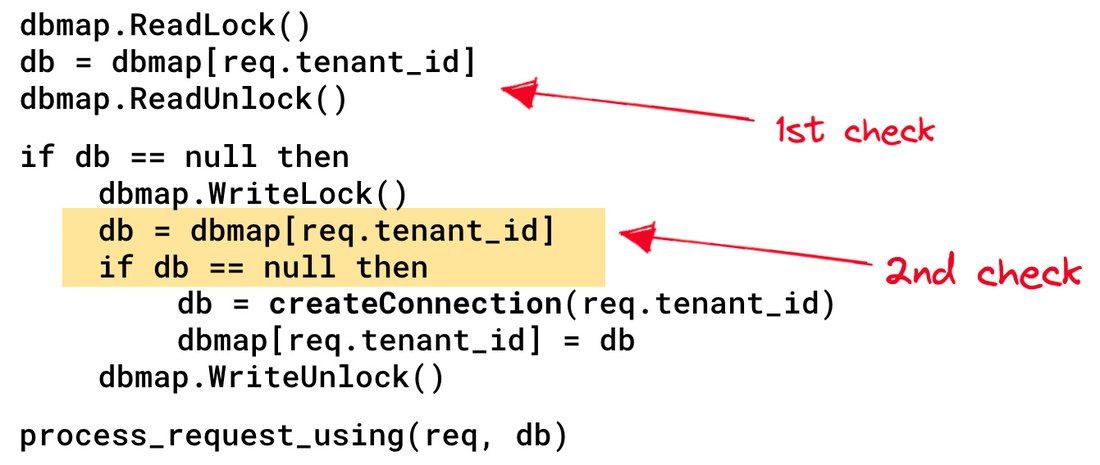
With this small change (only 2 extra lines of code), two requests for the same tenant never overwrite the tenant’s database connection. When we decided to try the double-check pattern, the performance dramatically improved!
We may also come up with more advanced patterns to create the connection of several tenants concurrently, further improving the performance of freshly started instances. Take a look at this simulation written in Go.
To learn more about optimizing the performance of your app in Cloud Run, check the section Optimize performance of the development guide.



