BBC: Keeping up with a busy news day with an end-to-end serverless architecture

Neil Craig
Lead Architect, British Broadcasting Company
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialEditors note: Today's post is from Neil Craig at the British Broadcasting Corporation (BBC), the national broadcaster of the United Kingdom. Neil is part of the BBC’s Digital Distribution team which is responsible for building the services such as the public-facing www bbc.co.uk and .com websites and ensuring they are able to scale and operate reliably.
The BBC’s public-facing websites inform, educate, and entertain over 498 million adults per week across the world. Because breaking news is so unpredictable, we need a core content delivery platform that can easily scale in response to surges in traffic, which can be quite unpredictable.
To this end, we recently rebuilt our log-processing infrastructure on a Google Cloud serverless platform. We’ve found that the new system, based on Cloud Storage, Eventarc, Cloud Run and BigQuery, enables us to provide a reliable and stable service without us having to worry about scaling up during busy times. We’re also able to save license fee payers money by operating the service more cost effectively than our previous architecture. Not having to manually manage the scale of major components of the stack has freed up our time, allowing us to spend it on using, rather than creating the data.
A log in time
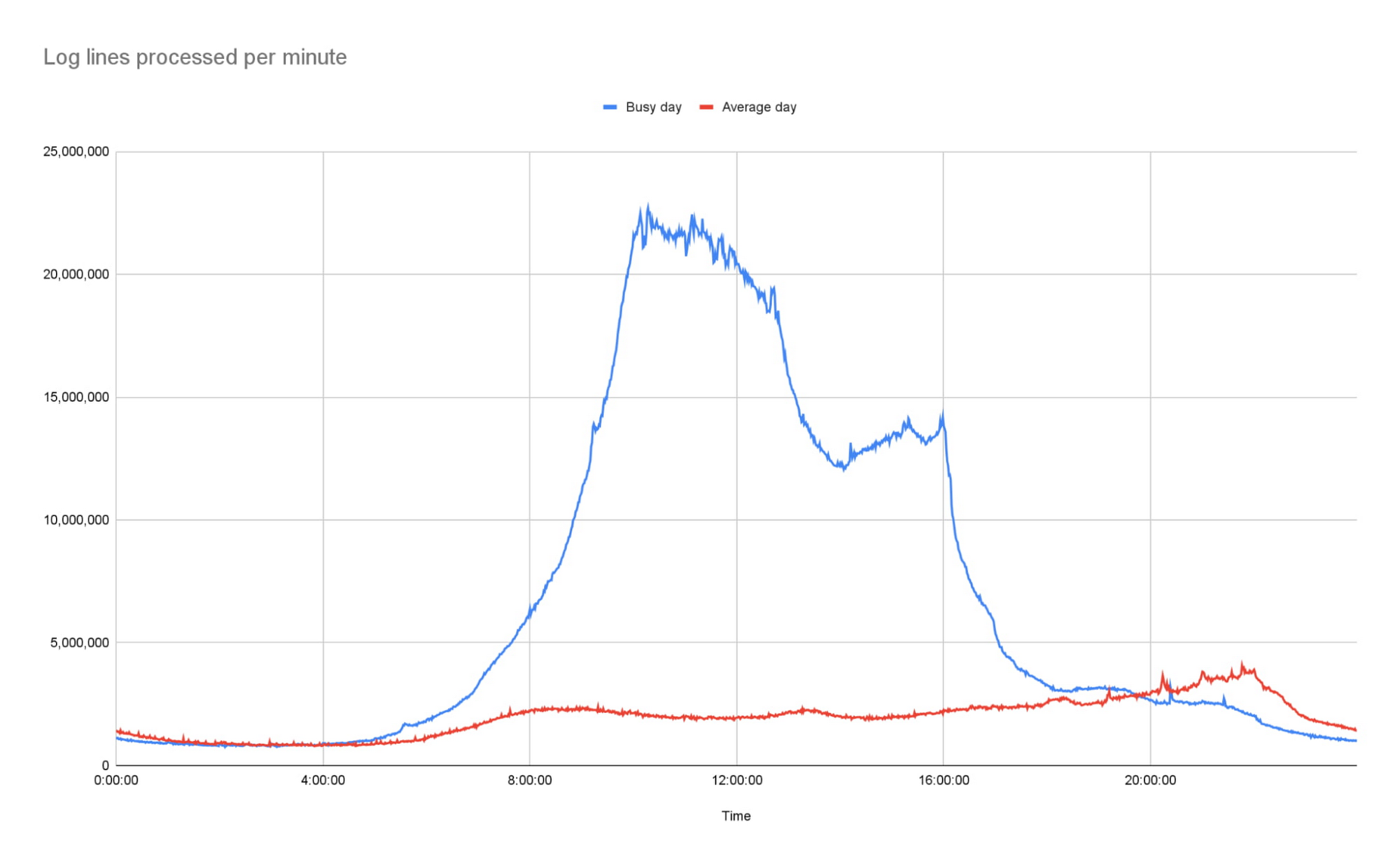
To operate the site and ensure our services run smoothly we continually monitor Traffic Manager and CDN access logs. Our websites generate more than 3B log lines per day, and handle large data bursts during major news events; on a busy day our system supports over 26B log lines in a single day.
As initially designed, we stored log data in a Cloud Storage bucket. But every time we needed to access that data, we had to download terabytes of logs down to a virtual machine (VM) with a large amount of attached storage, and use the ‘grep’ tool to search and analyze them. From beginning to end, this took us several hours. On heavy news days, the time lag made it difficult for the engineering team to do their jobs.
We needed a more efficient way to make this log data available, so we designed and deployed a new system that deals with logs and reacts to spikes more efficiently as they arrive, improving the timeliness of critical information significantly.
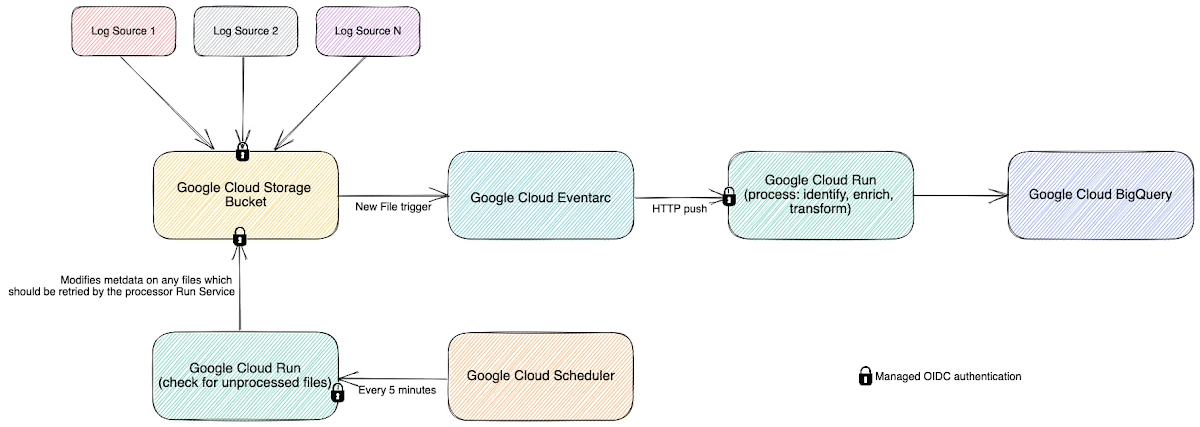
In this new system, we still leverage Cloud Storage buckets, but on arrival, each log generates an event using EventArc. That event triggers Cloud Run to validate, transform and enrich various pieces of information about the log file such as filename, prefix, and type, then processes it and outputs the processed data as a stream into BigQuery. This event-driven design allows us to process files quickly and frequently — processing a single log file typically takes less than a second. Most of the files that we feed into the system are small, fewer than 100 Megabytes, but for larger files, we automatically split those into multiple files and Cloud Run automatically creates additional parallel instances very quickly, helping the system scale almost instantly.
The nature of running a global website which provides news coverage means we see frequent, unpredictable large spikes of traffic. We learn from these and optimize our systems where necessary so we’re confident in the system’s ability to handle significant traffic. For example, around the time of the announcement of the Queen's passing in September, we saw some huge traffic spikes. During the largest, within one minute, we went from running 150 - 200 container instances to over 1000…. and the infrastructure just worked. Because we engineered the log processing system to rely on the elasticity of a serverless architecture, we knew from the get-go that it would be able to handle this type of scaling.
Around the time of the announcement of the Queen's passing in September, we saw some huge traffic spikes. During the largest, within one minute, we went from running 150 - 200 container instances to over 1000…. and the infrastructure just worked
Our initial concern about choosing serverless was cost. It turns out that using Cloud Run is significantly more cost-effective than running the number of VMs we would need for a system that could survive reasonable traffic spikes with a similar level of confidence.
Switching to Cloud Run also allows us to use our time more efficiently, as we no longer need to spend time managing and monitoring VM scaling or resource usage. We picked Cloud Run intentionally because we wanted a system that could scale well without manual intervention. As the digital distribution team, our job is not to do ops work on the underlying components of this system — we leave that to the specialist ops teams at Google.
Another conscious choice we made whilst rebuilding the system was to use the built-in service-to-service authentication in Google Cloud. Rather than implementing and maintaining the authentication mechanism ourselves, we add some simple configuration which instructs the client side to create and send a OIDC token for a service account we define and the server side to authenticate and authorize the client. Another example is pushing events into Cloud Run, where we can configure Cloud Run authorization to only accept events from specific EventArc triggers, so it is fully private.
Going forward, the new system has allowed us to make better use of our data safely. For example, BigQuery’s per-column permissions allow us to open up access to our logs to other engineering teams around the organization, without having to worry about sharing PII that's restricted to approved users.
The goal of our team is to empower all teams within the BBC to get the content they want on the web when they want it, make it reliable, secure, and make sure it can scale. Google Cloud serverless products helped us to achieve these goals with relatively little effort and require significantly less management than previous generations of technology.



