Monitor your NVIDIA GPUs on Compute Engine with Ops Agent
Lujie Duan
Software Engineer
Suffian Khan
Software Engineer, AI+Accelerators, Google Cloud
Organizations using AI and ML for applications such as product recommendations, scientific computing, and gaming often turn to NVIDIA GPUs on Google Cloud for the necessary compute performance. To understand their workload’s behavior and optimize the ML development process, they need to monitor the GPU performance metrics. To help, we’re excited to announce that Ops Agent now collects metrics from NVIDIA GPUs on Compute Engine VMs.
Cloud Ops Agent is the Google-recommended telemetry solution for Compute Engine that offers a curated experience for monitoring VM instances. With essential metrics from the NVIDIA Management Library (NVML) and advanced profiling metrics from the NVIDIA Data Center GPU Manager (DCGM), you can now get improved visibility into your NVIDIA GPUs and accelerated workloads.
With Ops Agent, you can:
Visualize the health of your GPU fleet with GPU metrics and out-of-the-box dashboards
Optimize costs by identifying underutilized GPUs and consolidating workloads
Plan scaling by looking at trends to decide when to expand GPU capacity or upgrade existing GPUs
Identify which GPU processes (the ML models) are consuming utilization and memory
Use DCGM profiling metrics to identify bottlenecks and performance issues within the GPU
Alert on metrics from your GPUs
Get essential GPU metrics right out of the box
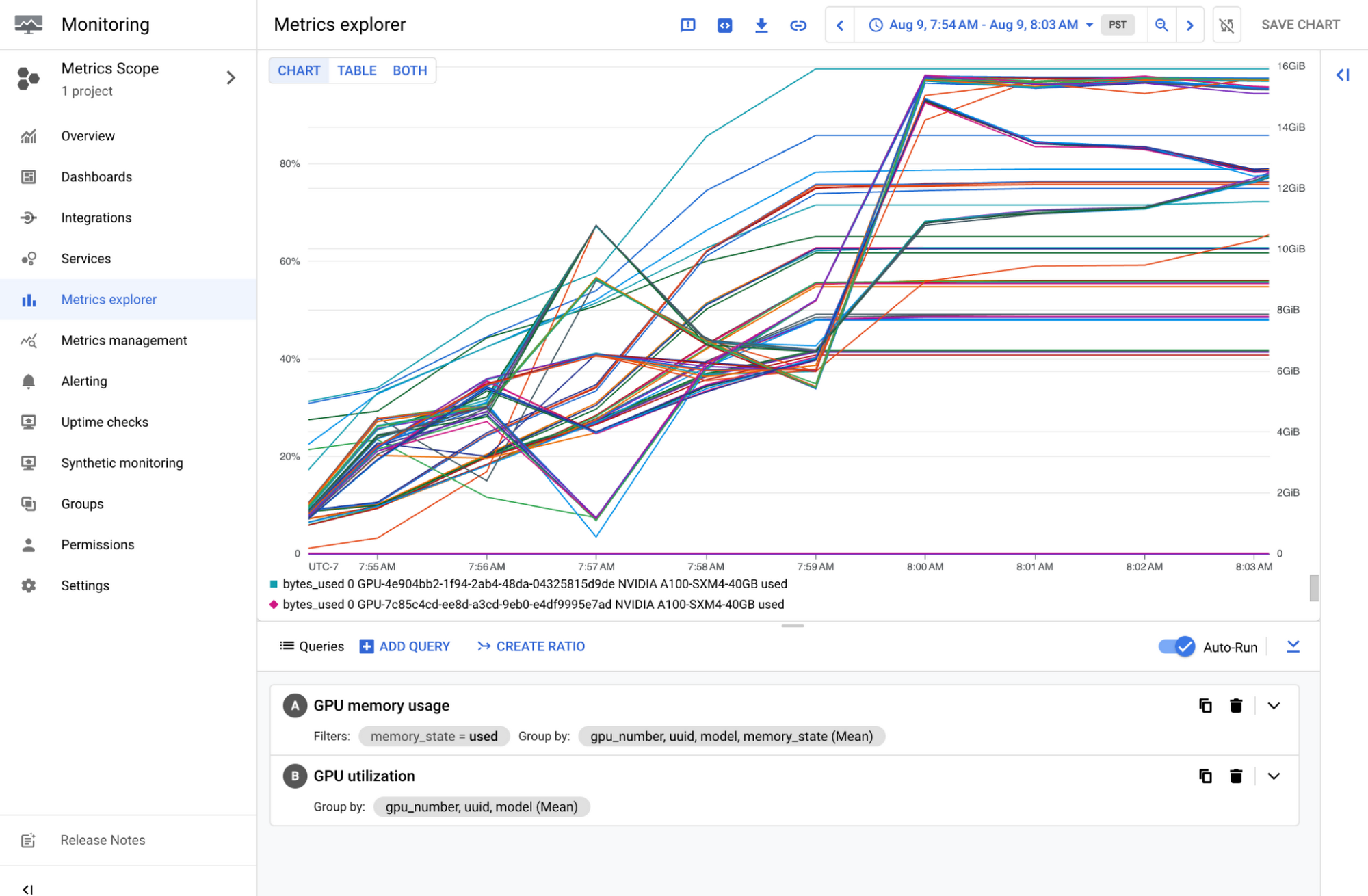
If you use NVIDIA GPUs, you’re probably familiar with the nvidia-smi command, which provides an overview of all GPU devices and the processes running on them. Leveraging the same underlying API in NVML, Ops Agent can collect those essential metrics without extra configuration. This includes metrics for:
GPU utilization
GPU memory usage
Process maximum GPU memory usage
Process lifetime GPU utilization
The process metrics track what workloads are running on the GPUs.
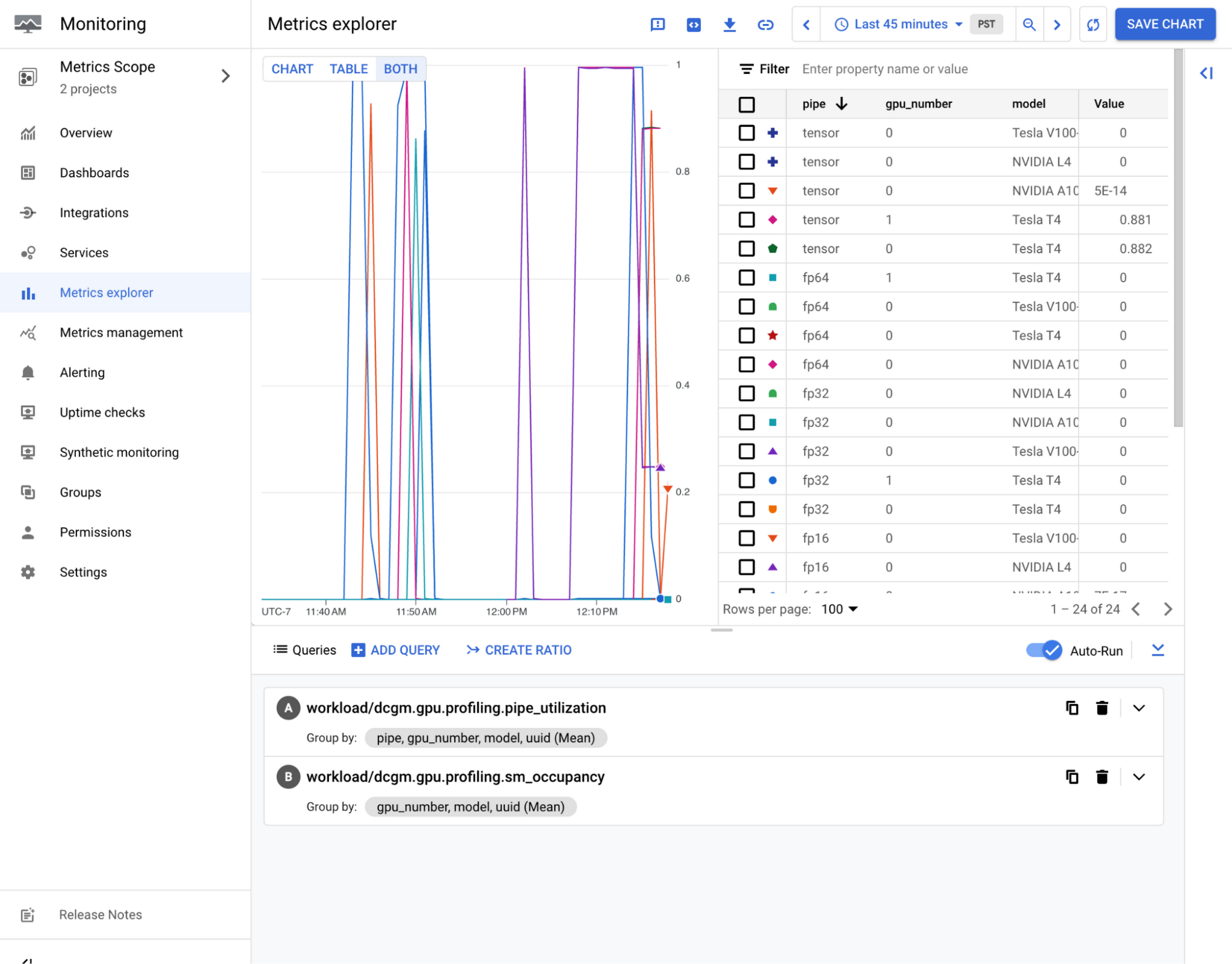
Collect advanced GPU metrics with DCGM
NVIDIA’s DCGM is a suite of tools to manage and monitor NVIDIA GPUs at scale. It offers an API for advanced profiling-level metrics of different hardware components, including streaming processors and interconnections such as NVLink and more. We have curated a list of these advanced metrics with the Ops Agent DCGM integration.
See the documentation for instructions on how to configure Ops Agent to use the DCGM integration.
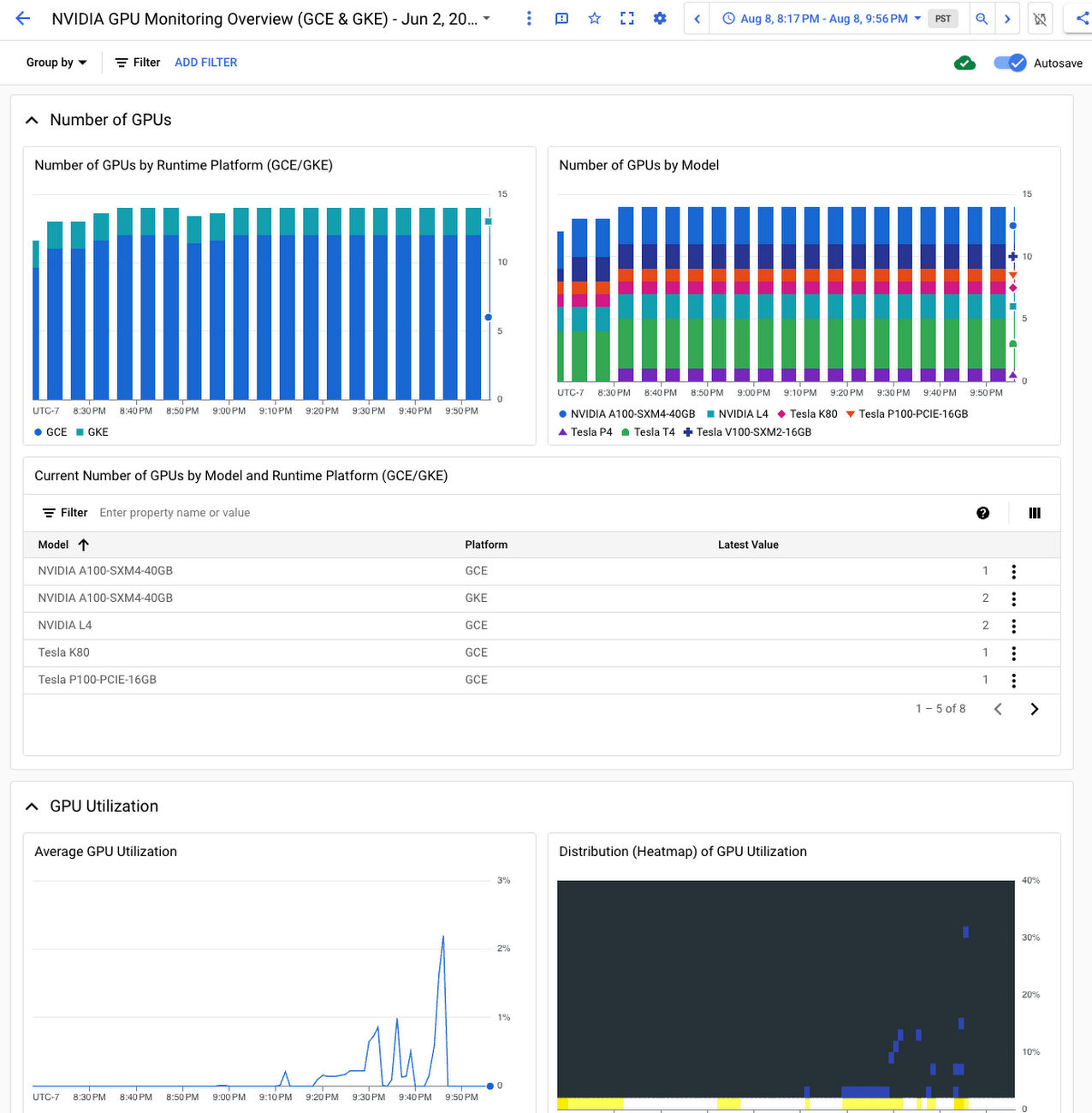
Visualize the health of your GPUs
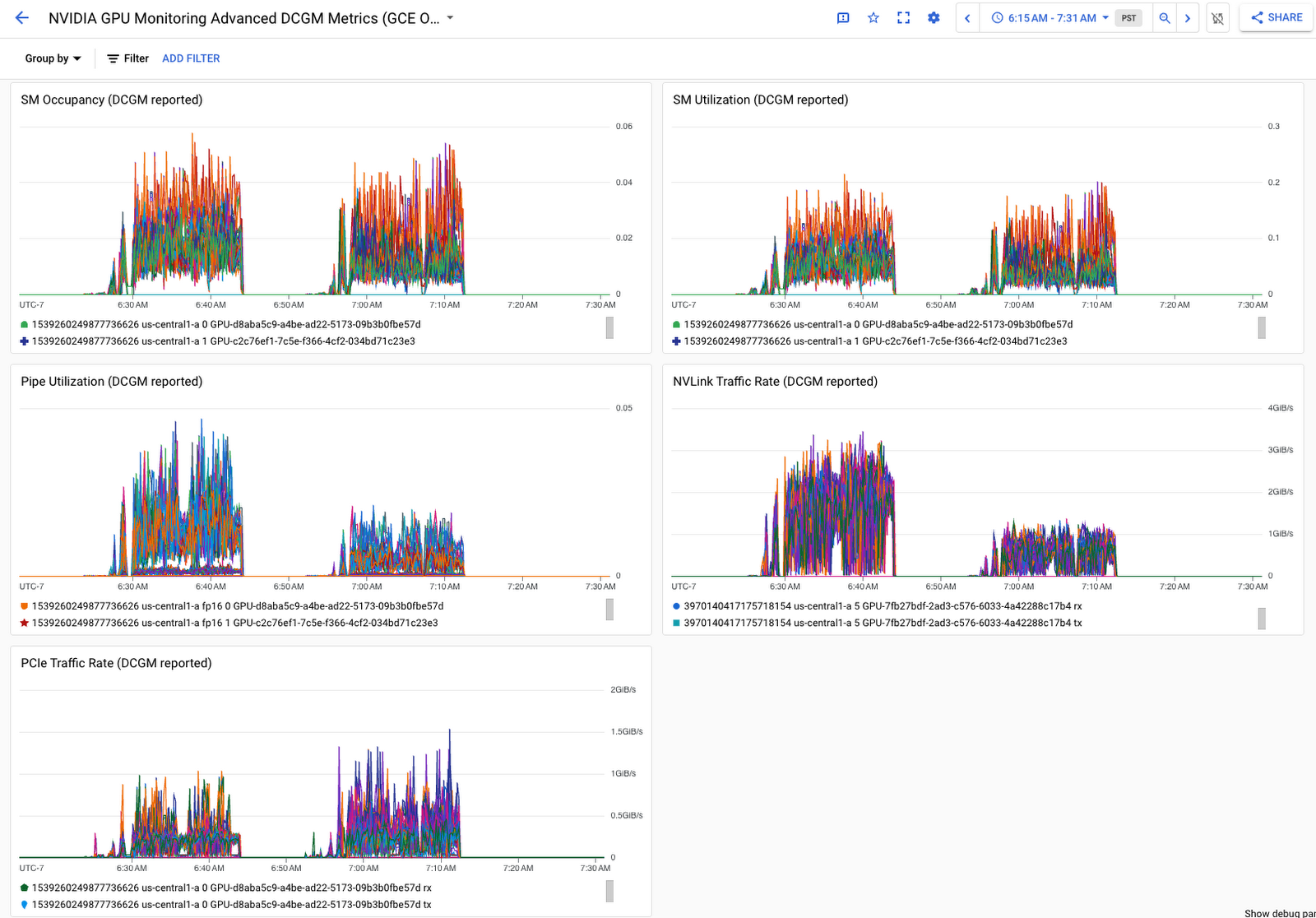
Together with the other offerings in Google Cloud's operations suite, you can easily query and visualize the collected GPU metrics from Ops Agent. Use our Metrics Explorer query builder or PromQL to construct queries, create custom charts, and add them to dashboards. Our NVIDIA GPU Monitoring dashboard provides a single pane of glass across your GPU fleet using GPU metrics collected from both GKE GPU nodes and Compute Engine GPU VMs. See the documentation on how to import this dashboard to your project. For the Cloud Monitoring DCGM integration, the DCGM dashboard is automatically installed to your project once DCGM metrics collection begins, delivering a focused view of the GPU profiling metrics.
One unified agent for VM monitoring, logging, and trace
Ops Agent is a feature-rich, unified telemetry agent with an intuitive configuration interface that lets you do more than just gain visibility into your GPUs:
Automatically collect host metrics such as CPU, memory, and process metrics
Automatically collect system logs such as syslog from Linux VMs and Windows Event Log from Windows VMs
Collect Prometheus metrics and OpenTelemetry Protocol (OTLP) metrics and traces from your workloads
Use the logging files receiver to ingest log files from your machine learning workloads to Cloud Logging
Use metrics processors to change the collection interval of your NVML and DCGM metrics or filter out any unneeded metrics. You can use metrics processors with NVML and DCGM metrics to filter and only keep the metrics you need, and easily change the collection interval of those metrics via the configuration file.
And with just one agent to manage, you can focus more on taking advantage of your GPU VMs.
Get started today
Interested in trying out Ops Agent when you create a VM through the Google Cloud console? We recently added a one-click option to add an Ops Agent when creating a new VM. This lets you try out Ops Agent with its default configuration before deciding how to manage your VMs and Ops Agents at scale.
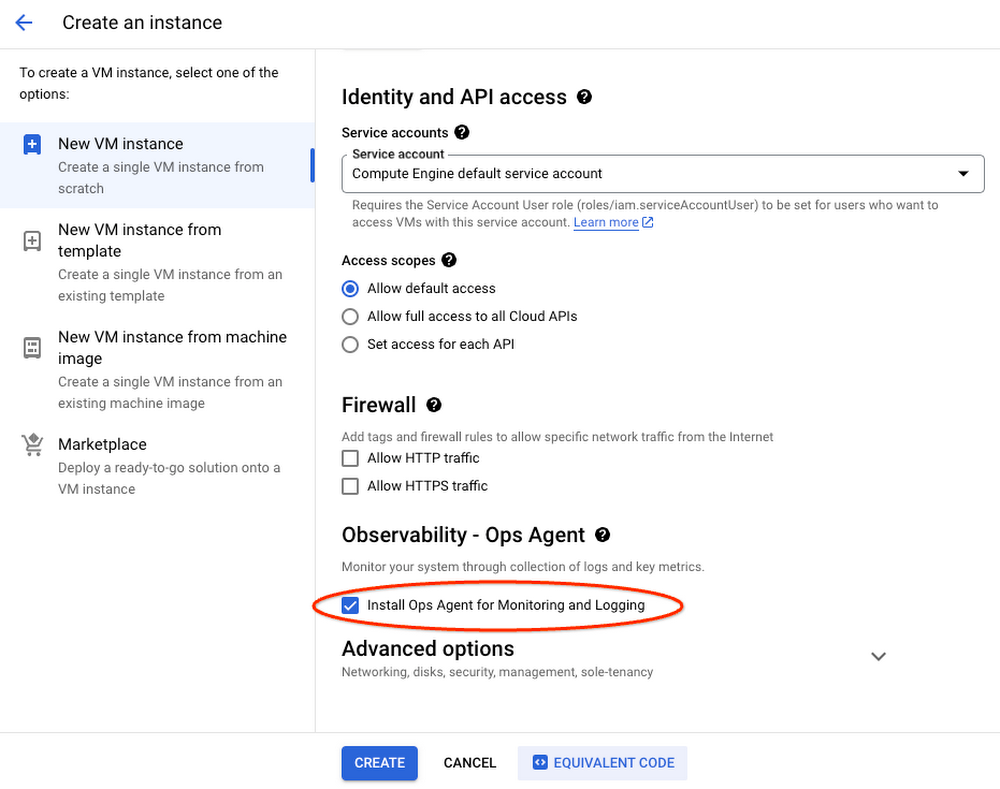
Check out the documentation on how to install and configure Ops Agent to monitor your GPU instances.



