Effective alerting in Google Cloud
Aron Eidelman
Developer Relations Engineer, Security Advocate
Alisa Goldstein
Product Manager
Engineering organizations need to be able to quickly and easily identify and resolve technical issues, but this need often takes a backseat compared to other priorities. With so many things to track, it can be challenging to know which ones need alerts. It is possible to set up too many alerts, create too much noise, and lose relevance when faced with real problems. Because of this, we need to clarify why we are creating an alert in two respects:
the relevance of what we’re monitoring to our business goals
the intended outcome once we notify someone there’s an issue
Understanding the relevance of what we’re monitoring can help us support triage in advance. When an issue occurs, we should have enough context to gauge its impact on users, potential cost, and what other problems it can take priority over. Relevance also helps us identify which signals warrant setting objectives. For example, latency is incredibly relevant in a customer-facing application that serves real-time data — yet irrelevant in a weekly cron job to clean up old files across systems. Relevance based on context helps us answer why, what, and when to alert.
The outcomes we intend from an alert notification vary widely, from immediate response to situational awareness. We should not be waking up our on-call engineers for minor issues that automation can already fix. We should also not be tucking away all of our alerts in emails since the more critical issues could slip by. We are determining the outcomes we want and the severity of impact, which can help us figure out who to alert and how.
Why should I create alerts for only some things?
When I create an alert for something, the assumption is that someone can and should act if notified.
Think of alerts you might experience in everyday life:
A flash flood warning on our phone
A text message about a declined credit card transaction
An email about a “login from a new device”
Each of these alerts could exist on a website or in a log, but we’re getting notified directly about each one. We often also get instructions about what to do:
Avoid roads, stay at home, and prepare an emergency kit
Agree that you intended to make the transaction and try again or report it as fraud
Trust the new device, or block access and immediately change your password
In some cases, even if we feel the alert isn’t relevant or are already aware of an issue, we still see the value of having the alert on in general. And even if we need to do some deeper digging, e.g., looking up the store’s name where the transaction took place or verifying the device matches what we’re using, the alert is a good starting point.
The zombie strategy of alerting, where too many metrics have alerts, potentially leads to a situation where the critical issues do not stand out. The saying goes, “If everything is important, nothing is important.”
Imagine getting a flash flood warning for every flash flood on Earth, not just the ones in your area. Imagine you get a text message not only for transactions, but for every time your bank offers a new type of credit card that might be interesting to you. How about an email every time you log in, even from the same device? These would condition you to ignore the more relevant warnings or otherwise distract you with noise.
We have a starting point: we should have alerts for things insofar as we can fix, influence, or control them, and insofar as not knowing about the alert could be worse for us. Still, that leaves a large set of possibilities that we need to trim down, starting with what to alert on.
What should I alert on?
No matter how much we automate, the constant area of focus is on relevance to users. In Why Focus on Symptoms, Not Causes, we explored why user-facing symptoms are a better area of focus for alerting than causes.
We should alert on things that are actionable and relevant to users. The SRE Handbook provides examples of service-level indicators that matter to users based on what they expect from your system. A few SLIs of note:
Availability. 500s, unintentional 400s, hanging requests, redirects to malicious sites–all count. Whether it’s the entire site or a small third-party component, anything that disrupts the critical user journey should be considered “unavailability.”
Latency. Fast (as long as it’s humans that are waiting).
Integrity/durability. The data should always be safe. Even if the data is temporarily unavailable, it should be correct when it comes back.
To set a discreet objective for each SLI, hence an “SLO,” you are assuming a threshold where the user starts to notice a degradation in service, or starts to feel that they are not getting what they were promised. To standardize the process of setting SLOs, you need to model user journeys and grade the importance of each interaction.
Starting from “symptoms” your users can feel, you may occasionally discover that there are still “causes” in your system that you need to alert on–a leading indicator deep within your stack that, while its behavior may be invisible to your users, can still impact them down the road.
Ideally, you’ll move to a state where you can automate responses to any of these issues. A great way to frame your goals for alerting is to start with the question: “What would it take for us to only alert on SLOs?” The gap analysis that follows will reveal where a system is too brittle, or where an organizational process falls short by requiring too many manual operations to respond.
What if I don’t have time to set SLOs?
Setting SLOs or doing a deep analysis of critical metrics takes time and organizational maturity, especially if a service is already complex. To help find a starting place for alerts and dashboards, Cloud Monitoring has an Integrations Portal with over 50 observability bundles. The bundles include the top metrics, sample alert policies, and sample dashboards to get started with popular Google Cloud and third-party services.
From this starting point, a team can configure the alert trigger to suit their needs, and use this starting point to extend alerting down the road.
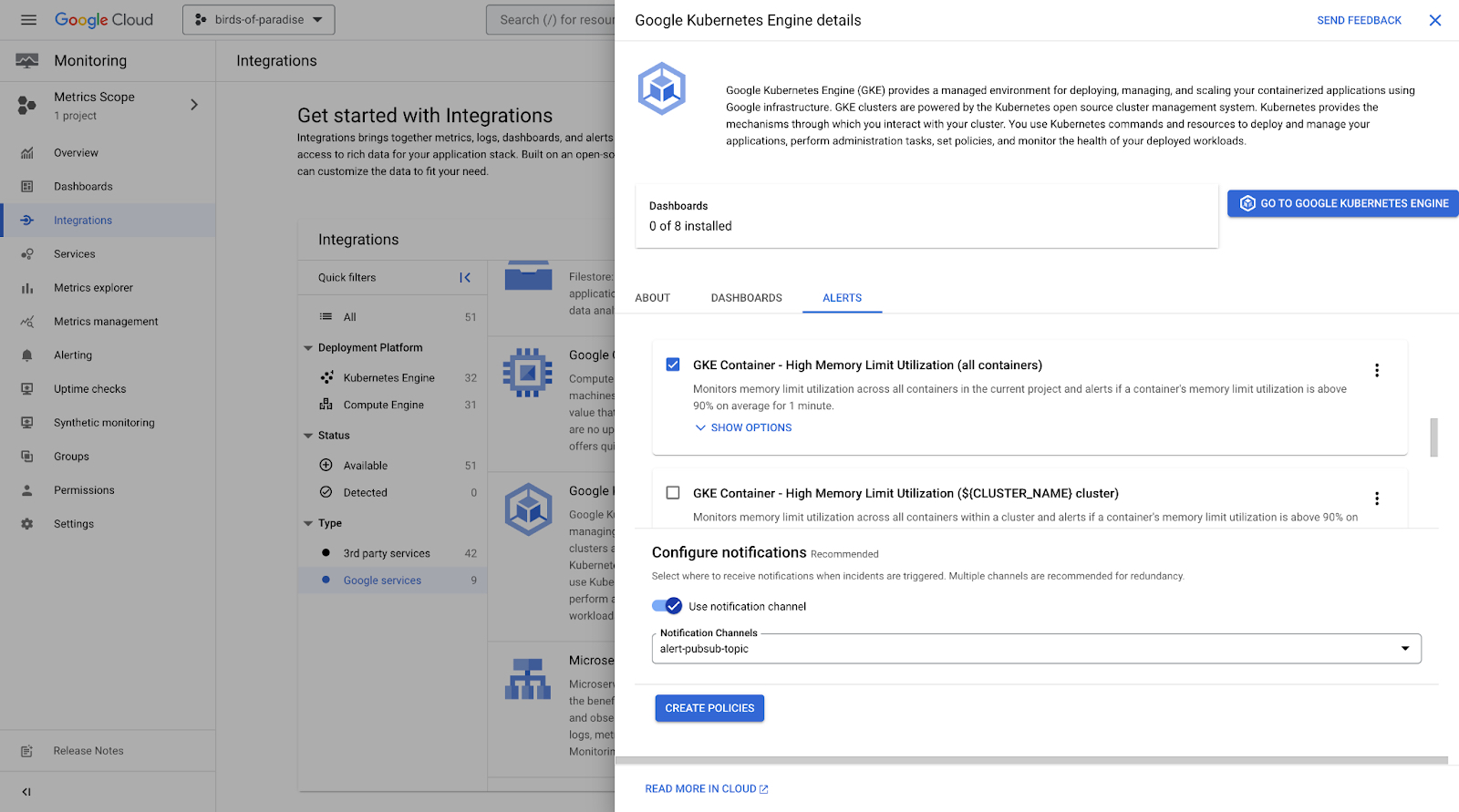
An essential rule of thumb to keep in mind is that alerts are only the “start” of an action or an investigation; they do not form the entirety of your strategy. Not all metrics should have a corresponding alert. If a system grows and becomes more automated, it would be normal to monitor more and alert on less.
Metric-based and Log-based Alerts in Google Cloud
Now that we have a sense of the criteria for picking top-level indicators, how do we actually collect them from our system? What form do they take in Google Cloud?
Metric-based alerts are triggered when a metric crosses a threshold. For example, you could create a metric-based alert that triggers when the CPU usage of a particular instance exceeds 80%. Metric-based alerts also can apply to metrics derived from logs, such as the number of times an error message appeared.
Log-based alerts, on the other hand, are triggered when a specific message appears even once in a log. For example, you could create a log-based alert that triggers when the message "Error: Database connection failed" appears in the logs of a particular service.
After finding the most relevant indicators in metrics and logs, it is necessary to determine the thresholds to trigger alerts.
At what point should I trigger an alert?
Not all issues have the same impact, and often, the impact changes over time or intensity. For this reason, teams need to be able to pick and adjust thresholds for when to trigger an alert, and may choose to create multiple policies for the same signal based on varying degrees of severity.
The duration and breadth of an issue affects the impact. For this reason, alert policies should be configured to match “how widespread” or “how long” a team determines an issue would be impactful. (Incidentally, this is exactly the type of estimation that goes into designing and tuning SLOs.)
For example, if you're alerting on CPU utilization on your instances, do you want to get alerted for every single instance that crosses the 80% utilization, or if the average utilization in a given zone crosses above 80%? The former would trigger an alert for every single VM, leading to possibly hundreds of separate alerts. The latter will lead to one alert for a widespread issue. To consolidate the number of alerts, add a “group by” to your alert policy; see step 3.d in the documentation.
Suppose there is a spike in 500 errors for a few seconds. In this case, the anomaly may be worth looking into — but that is less severe than when error rates persist for several minutes. Setting policies based on duration window helps indicate impact over time. From there, if you want a “warning” alert policy for a slight duration of 1 minute, and a “critical” alert policy for anything longer than 5 minutes, you can create two separate policies, each with the defined duration window, and apply different severity levels to each one.
Sometimes, an alert serves as a leading indicator, an early warning for a situation that would be much more complicated to act on once it arrives. For example, in monitoring the quota consumption of a cloud service, it’s necessary to know well in advance if a service is approaching maximum usage so that a customer can manually request a limit increase, which can take time to approve and cannot be automated.
If an issue is upcoming or ongoing, it needs direct intervention, whereas an issue that has already happened, it may require investigation. Thinking in advance about the urgency of intervention helps to set the right thresholds for prioritization, and can avoid too many small noisy issues from overtaking more pressing ones.
Who should I notify, and how?
Even in the most robust, automated system, it may still be necessary to send alerts to people. In those situations, the more context people have about an issue, the better. When creating an alert policy, you can use the Documentation section to add your internal playbooks and Google Cloud landing pages, and other links for your on-caller to begin an investigation, and add relevant labels for context.
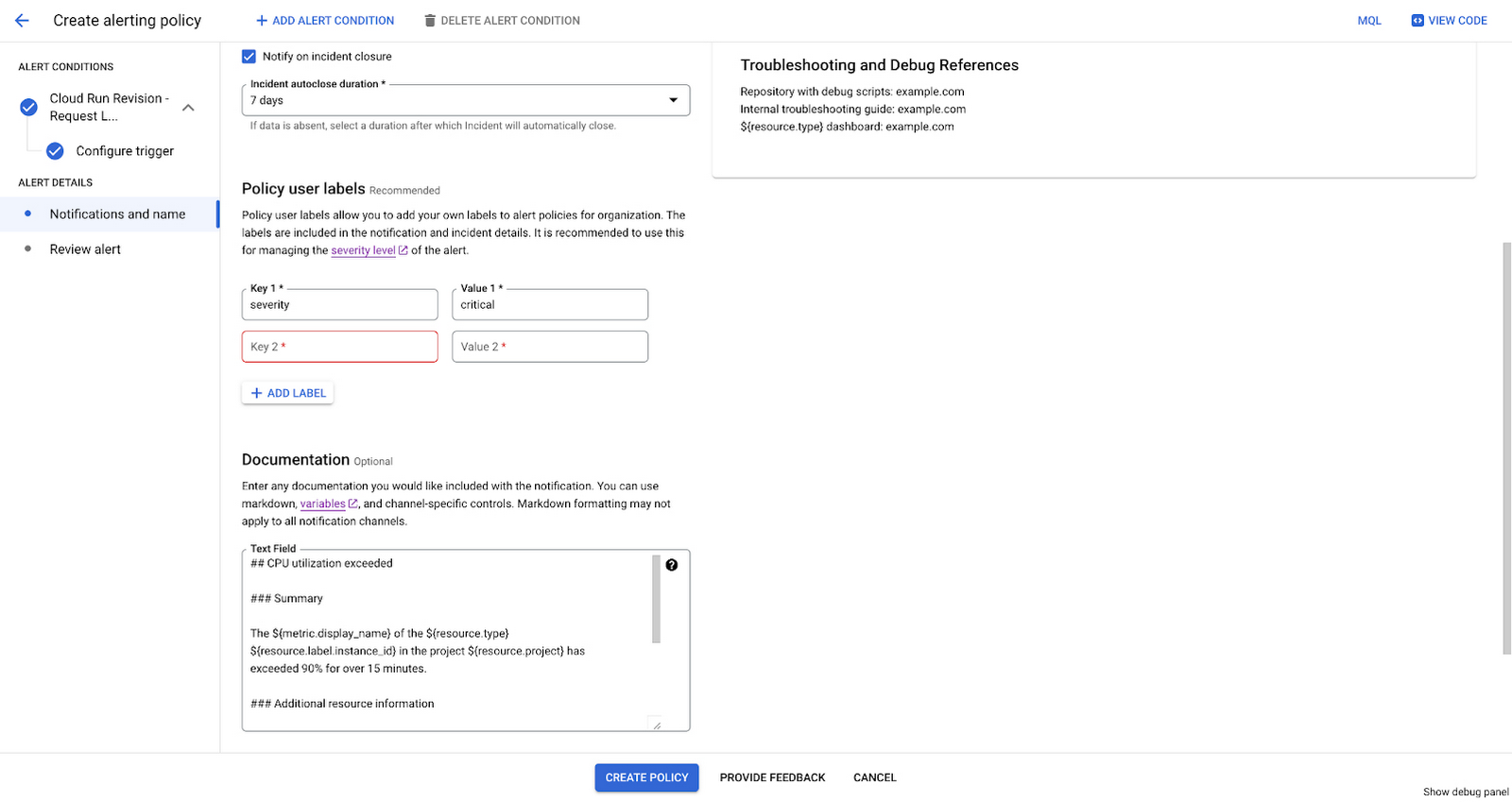
Once you have identified the people who need to know about an issue, you can decide how to notify them. In addition to using notification channels, Google Cloud offers Webhooks to send notifications to any public endpoint and Pub/Sub for any private endpoint for third party integrations. integrations with 3rd party tools.
For example, if the problem is urgent, you may need to notify a person directly, using SMS or a third-party paging tool. If the issue is important but less urgent, you can use a third-party tool to create a ticket that enters a queue. While using different channels may seem painfully simple, a common problem is using only one notification channel regardless of the urgency or severity level. If a team gets urgent notifications all the time, even for minor issues, they may get stressed out or desensitized, which in turn distracts them from the priority.
If alerts go to a low-priority channel, like a group email (which tends to be the default for cloud quota consumption), people may only see them after it’s too late. Only notify people who need to know that there is a problem, and leave it to their discretion to inform others. It may take some planning, but the goal is to avoid spamming people with irrelevant notifications. Different channels enable prioritization and appropriate visibility.
If the on-call person is the only person who can resolve an urgent issue, you should page them. There are plenty of urgent situations where the person on-call can’t handle the resolution on their own, so paging them is just the first step in an urgent escalation. (See a separate discussion and examples of incident management here.) If the issue isn’t critical, the alert should generate a ticket in the queue. The on-call person can still work on it–just not as an “interrupt.”
Concluding Guidelines
From establishing the relevance and intended outcomes of alerts, we can use quick rules of thumb to help us get the most out of alerts by keeping a high signal-to-noise ratio.
What to alert on:
Alerts should be actionable for Ops teams and relevant to end users.
For a mature Ops team, move to alerting on SLOs
To get started with Monitoring, see the Out of the Box Packages of alerts, dashboards, and metrics on the Integrations Page.
Alerts are the “start” of an action or an investigation; they may only represent a small portion of what you monitor.
Confirm the intended granularity of your alert policy. At what level do you consider a system impacted? Per violating Instance or on the average of all instances?
When to trigger an alert:
Determine if the alert is a leading or lagging indicator of a problem. Consider that impact changes over time.
Pick thresholds that reflect key points of change. Are my users experiencing something bad past this point? Is there enough time for my team to intervene?
If needed, divide thresholds into different severity levels for the same indicator. Pick thresholds based on assumptions about impact, response time needed, and how much risk is mitigated and accepted (e.g. error budgets for SLOs).
Who to alert, and how:
Only notify people you intend to act in response, and trust them to inform more people if needed.
Add playbooks and labels in the Documentation section to help your on-call team start their investigation
Using a specific notification channel or third-party tool, directly notify the person on-call if the situation requires an immediate response.
For less urgent issues, use a different channel or a third-party ticketing system instead of a direct notification to mitigate alert fatigue.
Get Started Today
To get started with alerting in your project, visit Alerting in the Google Cloud Console.
For introductory guides on how to set up alerts, see:
* Alerts:Uptime Checks to Pub/Sub Topics
* Alerts:Log-Based Errors to Pub/Sub Topics
If the guidelines in this article helped you create effective alerts or you have any questions, please join us at the next Reliability Engineering Discussion.



