Transform data to secure it: Use Cloud DLP
Anton Chuvakin
Security Advisor, Office of the CISO
Scott Ellis
Senior Product Manager
When you want to protect data in-motion, at rest or in use, you usually think about data discovery, data loss detection and prevention. Few would immediately consider transforming or modifying data in order to protect it.
But doing so can be a powerful and relatively easy tactic to prevent data loss. Our data security vision includes transforming data to secure it, and that's why our DLP product includes powerful data transformation capabilities.
So what are some data modification techniques that you can use to protect your data and the use cases for them?
Delete sensitive elements
Let’s start with a simple example: one of the best ways to protect payment card data and comply with PCI DSS is to simply delete it. Deleting sensitive data as soon as it’s collected (or better yet, never collecting it in the first place) saves resources on encryption, data access control and removes - not merely reduces - the risk of data exposure or theft.
More generally, deleting the data is one way to practice data minimization. Having less data that attracts the attackers is both a security best practice (one of the few that is as true in the 1980s as in 2020s) and a compliance requirement (for example, it serves as one of the core principles of GDPR)
Naturally, there are plenty of types of sensitive data that you can’t simply delete, and for which this strategy will not work, like business secrets or patient information at a hospital. But for many cases, transforming data to protect it satisfies the triad of security, compliance and privacy use cases.
In many cases, data retains its full value even when sensitive or regulated elements are removed. Customer support chat logs work just as well after an accidentally shared payment card number is removed. A doctor can make a diagnosis without seeing a Social Security Number (SSN) or Medical Record Number (MRN). Transaction trend analysis works just as well when bank account numbers are not included. For many contexts, the sensitive, personal or regulated parts don't matter at all.
Another area this works well is when a communication’s purpose is satisfied even with data removed. For example, a support rep can help a customer use an app without knowing that customer’s first name and last name.
As another example, our DLP system can clean up the datasets used to train an AI, so that the AI systems can learn without being exposed to any personal or sensitive data. Even first and last names can be automatically removed from a stream of data before it’s used to train an AI. Does your DLP do that?
In practice, this tactic can be applied to both structured (databases) and unstructured (email, chats, image captures, voice recordings) data. Removing “toxic” elements that are a target for attackers or subject to regulations reduces the risk, and preserves the business value of a dataset.
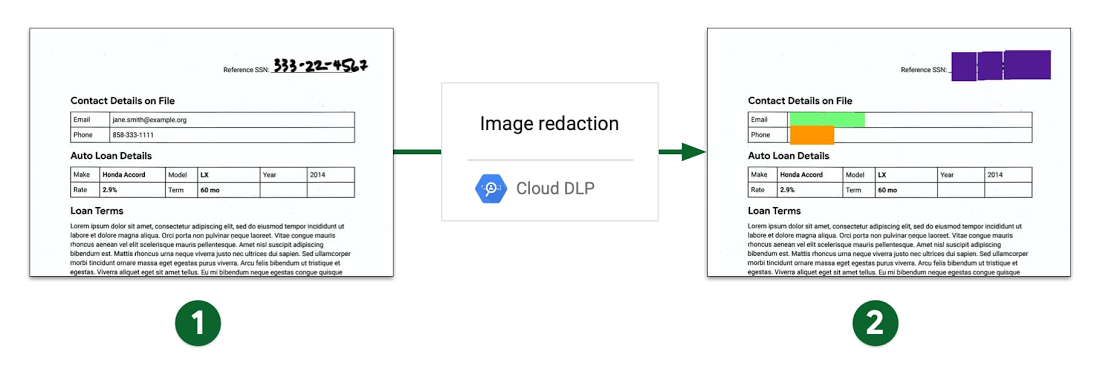
Transforming data as part of DLP goes beyond just deleting it. Various forms of data masking (both static and dynamic) are key to this approach. DLP can mean simply removing sensitive data from view, like obscuring what is shown to a call center employee. Notably, Cloud DLP works on stored or streamed data including unstructured text, structured tabular data, and even images. Paired with services like Speech-to-Text, Cloud DLP can even be used to redact audio data or transcripts.
Ultimately, the goal of any DLP strategy is to reduce the risk of sensitive data falling into the wrong hands. This is subtly different and broader than merely securing the data. If we can reduce the risk of holding the data, we in turn reduce the risk of losing it.
Replace sensitive elements with safe equivalents
Sometimes we can’t remove even small parts of sensitive data, but we can replace them with safer elements through tokenization. This is also a feature of Google Cloud DLP.
One of the advantages of tokenization is it can be reversible. Tokenization both reduces risk and helps ensure compliance with PCI DSS or other regulations—depending on the data being replaced. We can tokenize sensitive elements of data in storage or during display in order to reduce its risk. An insurance company may collect and use customer driver’s license numbers for record validation, and replace those numbers with a token when displayed elsewhere.
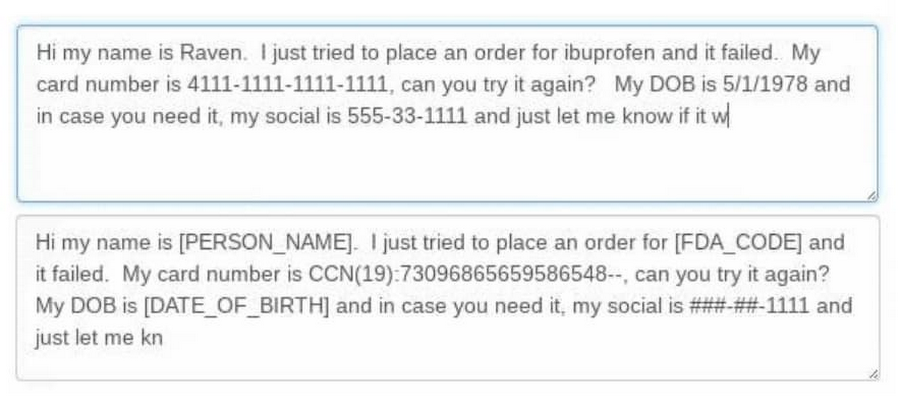
Another situation in which tokenization is particularly helpful is when two datasets need to be joined for analysis, and the best place to join them is a sensitive piece of data like an SSN. For instance, when a patient records database needs to be joined to a lab results database, or loan applications to financial records, we can tokenize the sensitive columns of both datasets using the same algorithm and parameters, and they can be joined without exposing any sensitive data.
Take fraud analysis as another example. Our case study shows that DLP can be used to remove international mobile subscriber identity (IMSI) numbers from the data stored in BigQuery. The data can be restored later, such as when fraud is confirmed and the investigation is ongoing. Note the staggering volumes of data being processed.
Now, some readers may point out that tokenization and DLP are traditionally considered different technologies. Cloud DLP is a broader system that covers both of these functions, as well as several others in one scalable, cloud-native solution. This allows us to solve for the greater goal of reducing risk while retaining the business value of a dataset.
Transform personal data
The risk of losing data is not only that criminals may steal and use it to defraud your company. There’s also the risk of privacy violations, off-policy use and other situations that come from the exposure of personal data. The loss of personal data is a twofold risk; both that of security and of privacy.
This makes transformation of data for DLP a worthwhile tactic for both privacy and security purposes. For example, an organization may be sharing data with a partner to run a trend analysis of their mutual customers. Generalizing demographics such as age, zip code, and job title can help reduce the risk of these partial identifiers from linking to a specific individual. This is useful for both citizen data collected by government agencies and healthcare research done by the Universities, for example.
Similarly, a user may share transactional data that includes dates that someone could use to triangulate their location, like travel dates, purchase dates, or calendar information. Cloud DLP can prevent this misuse with a date shifting technique that shifts dates per “customer” so that behavioral analysis can still be done, but the actual dates are blurred. Again, this is not a feature of any traditional DLP system.
Note that many of these methods are not reversible, and irrevocably change or destroy elements of a dataset. Yet they preserve the value of that dataset for specific business use cases, while reducing the risk inherent in that data. This makes using DLP a worthy consideration for teams looking to reduce both security and privacy risk, while retaining the ability to derive value from a dataset, without having to waste compute resources on encryption and granular access control. The constant balancing act between risk and utility becomes significantly easier when employing this approach.
Google Cloud DLP can help you employ all of these strategies. Read more about the future of DLP in Not just compliance: reimagining DLP for today’s cloud-centric world.
If you are Google Cloud customer, go here to get started with DLP.



{kind=link}