Using BigDL for deep learning with Apache Spark and Google Cloud Dataproc
Ding Ding
Intel Software Architect
Karthik Palaniappan
Software Engineer for Cloud Dataproc
BigDL is a distributed deep learning library developed and open-sourced by Intel Corp to bring native deep learning support to Apache Spark. By leveraging the distributed execution capabilities in Apache Spark, BigDL can help you take advantage of large-scale distributed training in deep learning.
BigDL is implemented as a library on top of Apache Spark, as shown below. It can be seamlessly integrated with other Spark libraries (e.g., Spark SQL and Dataframes, Spark ML pipelines, Spark Streaming, Structured Streaming). With BigDL, users can write their deep learning applications as standard Spark programs in either Scala or Python and directly run them on top of Cloud Dataproc clusters.
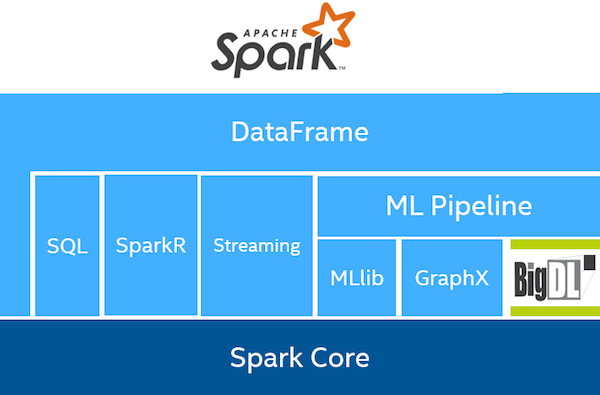
In this blog post, we’ll show you how to train models on Cloud Dataproc using BigDL’s Scala and Python APIs in Apache Zeppelin.
Deploying BigDL on Cloud Dataproc
You can use use the BigDL and Apache Zeppelin initialization actions to create a new Cloud Dataproc cluster with BigDL and Apache Zeppelin pre-installed. In order to do so, run the commands using gcloud, a command line utility included in the Google Cloud SDK.Note: the below instructions have been tested on Linux and Mac OS. There are some known issues with ‘ssh’ command-line options on Windows version of Google Cloud SDK.
By default, the BigDL initialization action downloads the latest compatible BigDL release (BigDL 0.4.0, Spark 2.2.0, and Scala 2.11.8 at the time of this publication). To download a different version of BigDL or one targeted to a different version of Spark/Scala, refer to the instructions in initialization action’s README.
Now you can run existing BigDL examples or develop your own deep learning applications on Cloud Dataproc! More information can be found on how to run BigDL on Cloud Dataproc and in the BigDL documentation.
Prepare MNIST data
Before we connect to Zeppelin, let’s download the MNIST dataset locally. MNIST is a small dataset of handwritten digits that is popular for machine learning examples, mainly because it requires minimal preprocessing and formatting.Then use gsutil to upload the files to your Cloud Storage bucket. gsutil is another command line utility that comes with the Cloud SDK.
Connect to Apache Zeppelin
In one terminal, create an SSH tunnel so you can connect to the notebook in a browser. This command will hang without printing any output.If your corporate firewall blocks outbound ssh, you will need to disconnect from your corporate network to run the following commands.
In another terminal, run a browser that uses the proxy server you just created. The instructions vary by operating system:
Mac:
Linux:
Windows:
Now you can connect to Zeppelin on your cluster by typing “localhost:8080” in the new browser window.
Click “Create new note” to get started. All the code in this blog should be run in the note you create.
Lenet example with BigDL Scala API
We will build a Lenet5 model to classify the MNIST digits.1. BigDL initialization
Let's start our experiment by importing some necessary packages and initializing the engine.
2. Set hyperparameters
You may need to tune these hyperparameters depending on your dataset and cluster size.
3. Load MNIST dataset
Read the binary file into a ByteRecord, which contains a byte array to represent the features and a label representing which digit (0-9) the image contains. You can read about the MNIST feature and label file formats here.
Make sure to replace “YOUR-BUCKET” with the name of the Cloud Storage bucket containing your MNIST data.
Pre-processes the data by normalizing the image pixel values for better neural network performance.
More information about BigDL’s `DataSet` class can be found in the API documentation.
4. Set up the model
5. Train the model
Run an Optimizer that minimizes our model’s loss on the training data. It will take around ten minutes to finish on a default two-worker cluster.
6. Test the model
Let’s use a Validator and the trainedModel to test the accuracy of the model on validation dataset.
You will achieve a respectable 99% accuracy.
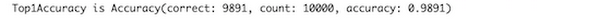
Autoencoder example with BigDL Python API
In this tutorial, we are going to use an autoencoder to learn how to compress handwritten digit images from the MNIST dataset into a lower dimensional representation. Then, we’ll reconstruct the original image from the representation.The autoencoder model attempts to minimize differences between an original input image and its reconstructed form. While the conversion is fairly lossy, it is still good enough for some practical applications, such as data denoising and dimensionality reduction for data visualization.
1. BigDL initialization
Again, let's start by importing the necessary packages and initializing the engine:
2. Load MNIST Dataset
Define the get_mnist method. It will convert the image data into Spark RDD and normalize the image pixel value.
Similar to the Scala example, we need to normalize the image pixel values for better neural network performance.
3. Model Setup
This is a very simple model with one hidden layer in the encoder. The size of the hidden layer (32) is the number of features in the compressed image. Since our input image had 784 features, the compressed images are about 4% of their original size.
Note that we can use such a simple model because the MNIST dataset is very simple.
4. Train the model
Run an optimizer that minimizes the differences between the input and reconstructed images. This will take several minutes.
5. Prediction on Test Dataset
We are going to use 10 examples to demonstrate that our trained autoencoder produces reasonable reconstructed images. We will compress and reconstruct the original images, then take 10 to compare with the original inputs.
You will see that the dataset has been reasonably reconstructed. The first line contains 10 of the original images, and the second line contains their reconstructed versions.

In this blog post, we demonstrated how users can easily build deep learning applications in a distributed fashion on Cloud Dataproc using familiar tools such as Spark and Zeppelin. The high scalability, high performance, and ease of use of BigDL make it easy to analyze large datasets using deep learning.
To learn more about the BigDL project, please check out the BigDL website, and for some interesting applications, please check out these BigDL talks. Lastly, we’ve made more tutorials available here.



