Traveloka’s journey to stream analytics on Google Cloud
Rendy Bambang Jr.
Data Engineering Lead, Traveloka
Agung Pratama
Data Engineer, Traveloka
Traveloka is a travel technology company based in Jakarta, Indonesia, currently operating in six countries. Founded in 2012 by former Silicon Valley engineers, its goal is to revolutionize human mobility.
One of the most strategic parts of our business is a streaming data processing pipeline that powers a number of use cases, including fraud detection, personalization, ads optimization, cross selling, A/B testing, and promotion eligibility. That pipeline is also used by our business analysts for monitoring and understanding business metrics, both for historical analysis and in real time.
In this post, we’ll describe how Traveloka recently migrated this pipeline from a legacy architecture to a multi-cloud solution that includes the Google Cloud Platform (GCP) data analytics platform.
Legacy architecture
Previously, our pipeline relied on Apache Kafka (for user events ingestion), sharded MongoDB (for an operational data store), and sharded MemSQL (for real-time analytic queries). In this approach, data from Kafka was processed by our Java consumer and stored with user IDs as primary keys in MongoDB. For analytics, events data was consumed from Kafka and stored in MemSQL where it could be accessed with BI tools for doing real-time analytics.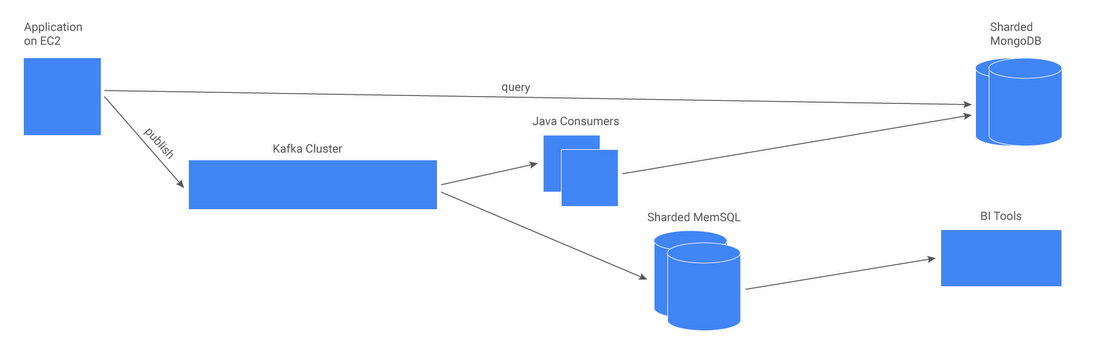
As Traveloka grew over time, several problems emerged, including:
- When issues occurred, debugging them in our Kafka cluster proved to be difficult and time-consuming.
- Our custom-built consumers didn’t scale well as we had to manually assign a Kafka partition to each specific consumer.
- Adding more nodes to MongoDB required a lengthy rebalancing process, and we were rapidly running out of disk space.
- We were only able to store 14 days of data in MemSQL due to memory limitations. Furthermore, sometimes queries resulted in out-of-memory errors.
- Low end-to-end data latency within a guaranteed SLA
- Fully-managed infrastructure to free engineers to help solve business problems (and spend much less time on maintenance and fighting fires), including:
- Resilience/99.9% end-to-end system availability
- Auto-scaling of storage and compute
Overview of the new multi-cloud architecture
We did our homework on technology that could support these requirements for our use case. In the end, we opted for a cross-cloud environment (AWS-GCP) including Google Cloud Pub/Sub (for events data ingestion), AWS DynamoDB (for operational data store), Google Cloud Dataflow (for stream processing), and Google BigQuery (for our data warehouse). (Note: Although Google Cloud Datastore was our preferred operational DB, the fact that it is not yet available in Singapore necessitated the use of DynamoDB.)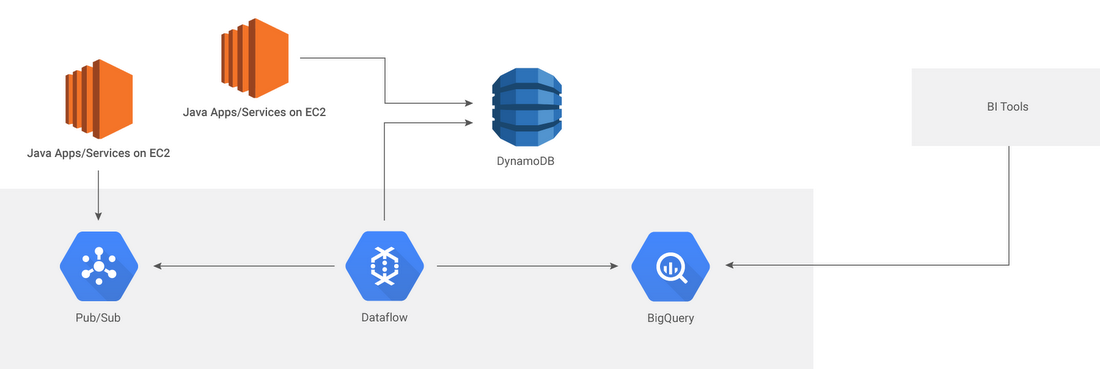
Next, we’ll provide some more details about our new pipeline.
Events ingestion (Cloud Pub/Sub)
User events that occur on our services now go through Cloud Pub/Sub. But before that step, we ensure the data complies with a defined schema — which is very important since inconsistent data (for example, unknown changes on datatype) can disrupt subscribers.Cloud Pub/Sub is very convenient for us because unlike our previous architecture, which required capacity planning for events ingestion, we can rely on its autoscaling capability to handle volume and throughput changes without any work on our part.
Data processing (Cloud Dataflow)
Cloud Dataflow is a fully-managed GCP service for processing data in streaming or batch modes with equal reliability and expressiveness. Its ability to spawn new pipeline workers (and to autoscale) without any user intervention is a big advantage for us, especially when have to backfill a pipeline in order to process historical data. For example, we’ve seen Cloud Dataflow spin up dozens of workers over the course of 30 minutes, with 40-50k data/second throughout (with throttling by the downstream operational datastore). In most cases, end-to-end latency is less than three seconds.Cloud Dataflow’s unified programming model (aka Apache Beam) for batch and streaming processing is also very useful. To switch between modes, all we have to do is change the pipeline’s source and sink:
- For batch (historical data backfilling): Cloud Storage to Cloud Storage (staging phase) + Cloud Storage to DynamoDB
- For streaming (real-time analysis): Cloud Pub/Sub to DynamoDB and Cloud Pub/Sub to BigQuery
Real-time data warehouse (BigQuery)
As part of the GCP streaming analytics solution, BigQuery’s support for streaming data is a major advantage for us to support our real-time analytics use case. Furthermore, we no longer worry about storing 14 days of historical data because BigQuery stores all of it for us, with required compute resources auto-scaling on demand as we need it. (Most of our analytics queries are time-based, so using_PARTITIONTIME is fast and cost-effective for us.)



