Now live in Tokyo: Using TensorFlow to predict taxi demand
Kaz Sato
Developer Advocate, Cloud AI
Yuki Oyabu
Machine Learning Specialist, Google Cloud
Have you ever been stuck waiting for transportation—especially in poor weather—outside of a restaurant or an event venue? NTT DOCOMO, Japan’s largest mobile service provider, has launched a demand forecasting service for taxi operators, starting in February, 2018. The service collects real-time people density from mobile phones and runs data analytics with a deep learning model on TensorFlow to predict how many possible riders could be waiting in each block or street in the next 30 minutes, with 93-95% accuracy.
Today, over 2,500 taxis in Tokyo and other major Japanese cities use the service to 1) shorten the average wait time of each rider, 2) quickly respond to sudden change of demands, and 3) reduce the performance gap between experienced drivers and novice drivers. These benefits are delivering a notable revenue boost for taxi operators.

Taxi drivers can see the real-time demand prediction from the smart taxi demand prediction service
How it works
The system uses the following data as input for the demand forecast.- Connection density statistics from NTT DOCOMO’s mobile network
- Taxi location and activity from each vehicle
- Weather data (similar to real-time NOAA global surface summary data)

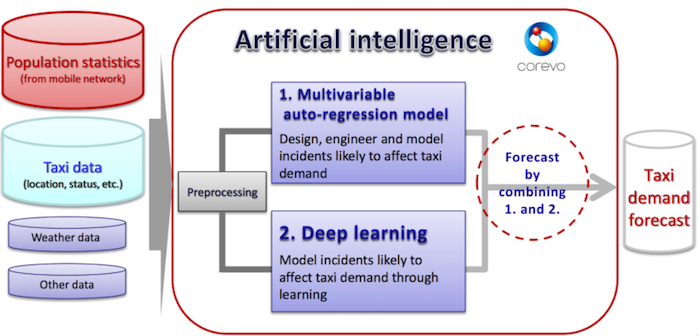
After preprocessing, these data are converted into an input vector with about 120 dimensions. NTT DOCOMO’s data scientists analyze the input vector with two machine learning models:
- A deep learning model
- A contrasting statistical analysis model (for specific geographical areas that deviate from the “deep” model)
The prediction contains estimated numbers of possible riders in the next 30 minutes for each 500m x 500m cell. There are about 3,000 cells in the Tokyo service region. These numbers are shown as hotspot markers on the map display mounted in each taxi.
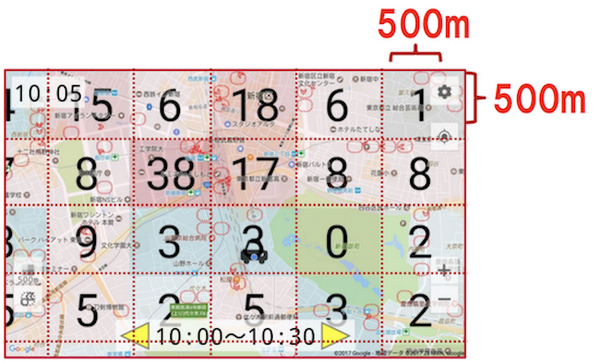
The ML model predicts the number of riders in each zone on the grid

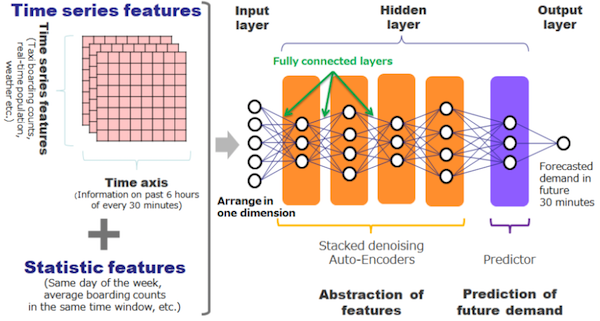
A deep learning model to predict taxi demand
Let’s take a look at the deep model the service uses. The input vector with 120 dimensions contains the historical record of the population statistics, taxi activities, and weather data, combined with calculated statistics such as average number of riders in the same time-of-day or day-of-week.Many data scientists use deep models such as RNN (recurrent neural network) or LSTM (long short-term memory) for time-series analytics for this type of application. But NTT DOCOMO chose a different approach, a stacked denoising auto-encoder, after trying out various different models.
Why select an auto-encoder? Shin Ishiguro, NTT DOCOMO Data Scientist explains, “The biggest challenge in forecasting taxi demand was how to remove noise from the input vector. So we found the denoising autoencoder works pretty well at picking up important signals.”
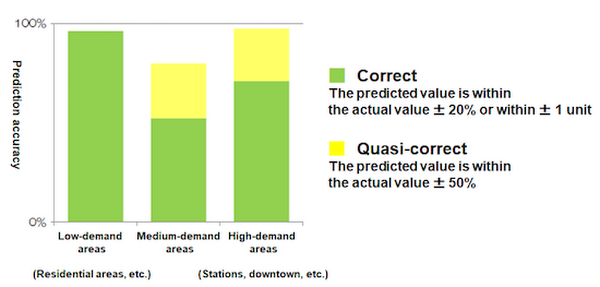
By combining the prediction from the deep model with one from the statistical model, the service reports to achieve 93-95% accuracy overall.
Many taxi operators are already quite happy, because they’ve noticed an increase in their earnings already. Satoshi Kawasaki, leader of the software development team explains, “Usually, taxi drivers just drive around main streets based on past experience. But with the forecasting system, drivers can also respond to unexpected change of demands for things like public events or other externalities. The service is also quite handy when drivers get to area they don’t know well. Novice drivers without much experience can also use the tool for filling the performance gap between them and expert drivers.”
Growing on and with Google Cloud
Shin explains, “The most challenging part of development is hyperparameter tuning. Currently, we take 20 minutes to generate one model, after which iterate this step 1,000 times to find the best combination of hyperparameters using a random search method. This process consumes a large amount of computational resources.”So recently, NTT DOCOMO began an in-depth evaluation of Cloud AI Platform to address these challenges. “With Cloud AI Platform, you don’t have to be both an expert data scientist and an expert infrastructure engineer to build a large-scale, distributed training environment. Also, we really want to try HyperTune, which uses a much smarter algorithm for the hyperparameter tuning. These features may save a significant amount of my time for service development, deployment, and operation.”
When you next visit Tokyo, if you never have to wait for a taxi, you just might have a TensorFlow running on Cloud AI Platform to thank! And as the dataset of historical training data grows, the more accurate this demand prediction model will become, based on current inputs.
Note: if you’re interested in understanding how NTT DOCOMO anonymously collects real-time population density information, check out this paper.




