Learn TensorFlow and deep learning, without a Ph.D.
Martin Görner
Google Cloud Developer Advocate
This 3-hour course (video + slides) offers developers a quick introduction to deep-learning fundamentals, with some TensorFlow thrown into the bargain.
Deep learning (aka neural networks) is a popular approach to building machine-learning models that is capturing developer imagination. If you want to acquire deep-learning skills but lack the time, I feel your pain.
In university, I had a math teacher who would yell at me, “Mr. Görner, integrals are taught in kindergarten!” I get the same feeling today, when I read most free online resources dedicated to deep learning. My kindergarten education was apparently severely lacking in “dropout lullabies,” “cross-entropy riddles,” and “relu-gru-rnn-lstm monster stories.” Yet, these fundamental concepts are taken for granted by many, if not most, authors of online educational resources about deep learning.
To help more developers embrace deep-learning techniques, without the need to earn a Ph.D., I have attempted to flatten the learning curve by building a short crash-course (3 hours total). The course is focused on a few basic network architectures, including dense, convolutional and recurrent networks, and training techniques such as dropout or batch normalization. (This course was initially presented at the Devoxx conference in Antwerp, Belgium, in November 2016.) By watching the recordings of the course and viewing the annotated slides, you can learn how to solve a couple of typical problems with neural networks and also pick up enough vocabulary and concepts to continue your deep learning self-education — for example, by exploring TensorFlow resources. (TensorFlow is Google’s internally developed framework for deep learning, which has been growing in popularity since it was released as open source in 2015.)
Dive into the presentations
If you have 1 hour: watch this presentation while following the slide deck. This installment covers dense and convolutional networks and is also available as a self-paced codelabIf you have 3 hours (recommended; recurrent networks are worth it!): watch this presentation. You'll need both slide decks, Part 1 and Part 2.
If you prefer bite-sized portions: Explore the table of contents below.



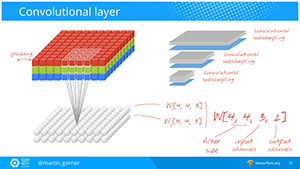


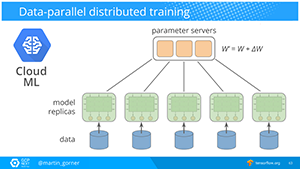
Next steps
- See Martin present this tutorial in person at Google Cloud NEXT '17 on March 8 (in San Francisco)
- Code a neural network yourself with the self-paced codelab
- Read TensorFlow “getting started” docs
- Explore other TensorFlow tutorials
- Join the conversation via the tensorflow tag at StackOverflow
- Learn about Google Cloud Machine Learning




