Keys to faster sampling in Cloud Dataflow
Rafael Fernandez
Technical Program Manager
Editor’s Note: Ben Chambers made the majority of the contributions to this post and white paper prior to moving on to other opportunities. He was a long-time Googler, and remains a strong contributor to the Apache Beam project.
Many of our customers and developers need to take meaningful samples of large collections prior to—or as part of—their main large scale processing needs. There are many well known approaches for sampling, with varying statistical properties. A direct implementation of such sampling approaches may not be the most optimal for scaling. I am pleased to share with you a new whitepaper: Keys to Faster Sampling in Dataflow. In this whitepaper, we show you how to improve the performance of a useful operation—selecting a sample of elements—on Cloud Dataflow. The ability to select such a sample is useful on its own, but the paper also highlights techniques that are generally applicable to other algorithms you might want to use with Cloud Dataflow.
The whitepaper walks you through building a composite transform for producing a stratified sample that preserves the distribution of a specific property in the data, and illustrates how composite transforms allow developers to package this functionality and reuse it by building on the improved global sampling while creating the stratified sampling.
As an example of the discussions in the paper, here is a sensitivity analysis for a data set and a choice of fixed size for all sampling buckets:
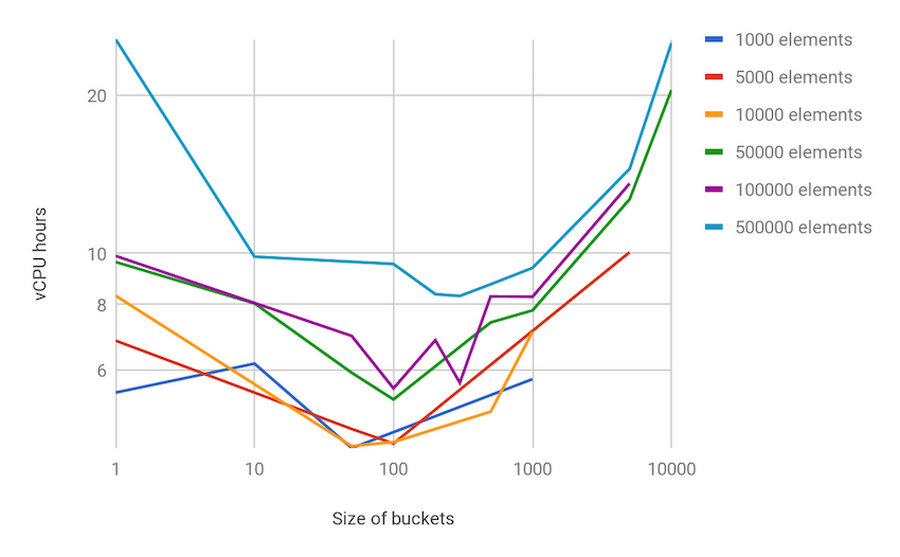
We show experimental results on Cloud Dataflow, with autoscaling enabled, processing a synthetic dataset with a high-volume (10 billion) of relatively small (100-byte) elements, which is similar to processing log messages or event logs. We look at producing a sample of 1,000 to 500,000 elements (1MB to 500MB). All of the pipelines are executed in Cloud Dataflow using autoscaling with a maximum of 128 workers.
Please find the white paper linked here.



