How Tokopedia modernized its data warehouse and analytics processes with BigQuery and Cloud Dataflow
Maria Tjahjadi
Data Warehouse Lead, Tokopedia Data Team
At Tokopedia, our aim is to help individuals and business owners across Indonesia open and manage their own online stores, while providing a safer, more convenient online shopping experience for users. We’re excited that this aim has made Tokopedia the leading online marketplace in Indonesia, and it’s also generated a lot of data, in a multitude of formats!
As Data Warehouse Lead, my job is to first, lead optimization and migration of the existing data warehouse to Google Cloud Platform, and second, to enhance the analytic data architecture and governance. Our data journey began with a free edition of Relational Database Management System as our first database. After a period of significant growth, we migrated to PostgreSQL to increase both size and performance. As our growth skyrocketed, we came to yet another decision point—we found we were using a lot of resources and personnel just to clean the database in order to free up capacity for the following day.
As we thought about our next steps, system performance guided our decision-making process. In our previous system, some complex queries could run for more than five hours! Not only that, but our users were requiring an increasing number of reports—to the point where new reports were being requested on a daily basis and grown to 10x more reports than we used to 6 months ago. We’d end up with duplicate (or similar) tables and reports, which could hurt performance.
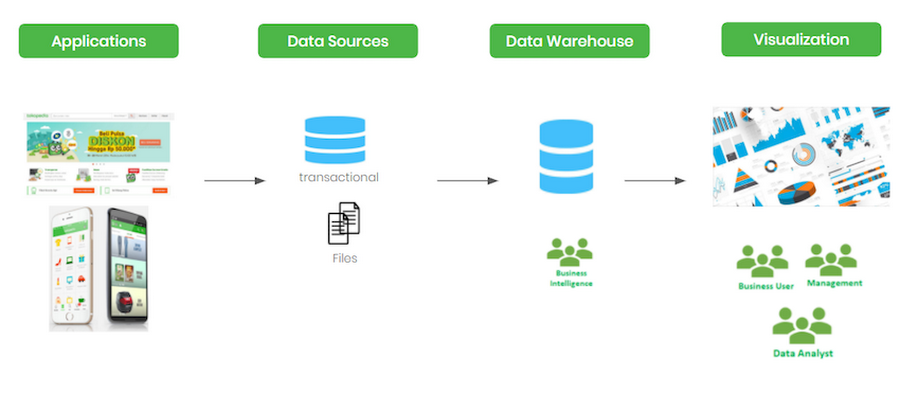
Our old architecture
Our "traditional" data warehouse architecture was straightforward. From various sources, data was loaded into the data warehouse and then directly mapped to the visualization tool. In 2017, when we began our migration project, we identified several issues we needed to overcome:- Scalability: The size of our data warehouse had grown rapidly, as had the number of sources we were ingesting. This growth of over 5x our original size had stretched our data warehouse’s capabilities.
- Integration: A large amount of our data existed within Google BigQuery, but we struggled to ingest it into PostgreSQL. We had to extract data via a CSV and load it in.
- Performance: Not only had our data grown, but so had the need for multi tenancy. With user growth of about 10x, our data warehouse performance had slowed to an unacceptable rate.
- Technology: We needed several tools to load data, we ended up with non integrated data ingestions tool which is difficult to maintain. We also wanted to work with unstructured data, and couldn’t. Data silos meant we lacked an integrated data analytics platform.
Results of implementing BigQuery
From an architecture perspective, we use Google BigQuery, in combination with Cloud Dataflow for data processing, and Apache Airflow for scheduling. Our needs dictate that some jobs run once a day through batch processing, while others are done in real time.. The unique combination of both batch and streaming capabilities provided by Dataflow provide a simplicity we haven’t seen in solutions from other vendors. We’ve been able integrate the data in just one schema in a staging layer.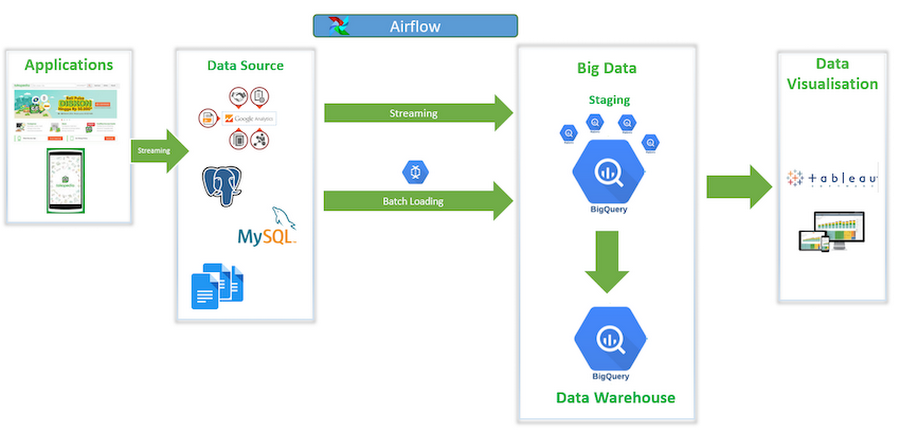
Tokopedia's big data architecture
Our data warehouse has two layers:
- The data in staging layer will be from all data sources like, PostgreSQL, Google Analytics, Google Sheets, and MySQL. It is only one-on-one loading from all data sources, while Google Sheet will use seamless integration to Google BigQuery. Our team uses Scala with a Scio library to run the data flow, and to load data from the source to BigQuery staging.
- The data warehouse layer is created by transforming several source tables, join, aggregate, and do filter. We use SQL to write the transformation from BigQuery staging to the data warehouse. After the tables are ready, the business intelligence team creates the reporting on top of it. Also, in this layer, we prepare denormalized tables so our data analyst team can perform analysis through Google BigQuery.
We encountered some challenges during the migration process, including:
- Lack of a data warehouse team
- Limited BigQuery and Google Cloud Platform experience
- Minimal coding experience, more familiarity with SQL than data engineering
- Huge dataset to be migrated
- Formed an “official” data warehouse team
- Leveraged the expertise of the Google Cloud team
- Undertook online trainings and internal sharing sessions
- Collaborated with data engineer team to leverage their programming skills
- Applied an agile approach during the migration process
- Documented all steps
- Research helped us define which programming languages that will be used to load the data into Google BigQuery. For our case, we have several options, Python, Scala, Java, Talend, Apache Beam with Java or Python SDK.
- In addition to research, we also run benchmarks, to determine which programming language supports our performance and functionality needs, for development activities, either in a development or a production environment. We benchmark not only from technology perspective, but also from a skills and experience perspective.
- Being agile is important, not only in terms of a project management perspective, but also for team dynamics. There were times when we needed to change our approach, because it was impacting current development. Also, data warehouse migration is a huge task. To make it achievable, we had to split the development into several phases.
- By assigning a dedicated team to do migration, we could manage the tasks properly, with homegrown knowledge-sharing inside the team.
- Defining a standard is important. We have a lot of developers, so review processes would be impossible without standardization.
- Documentation is key. Since we were migrating from PostgreSQL, we needed to translate PostgreSQL-specific functions to BigQuery functions, such as
age(),to_hex(),ntile(),generate_series(), etc. We are documenting these mappings collaboratively so that we can minimize the time it takes other development teammates to search for answers.
- Development up to 500 analytics jobs in 2 months, with typically more than 100 jobs scheduled daily. And we’ve done all of this with a team of six dedicated engineers
- Experimentation with different programming languages, including Python, Java, and Scala
- Overall improvement of our team’s analytical experience of using Google Cloud Platform, especially thanks to Dataflow and BigQuery




