How to avoid a self-inflicted DDoS Attack—CRE life lessons
Dave Rensin
Director, Customer Reliability Engineering, Google Cloud
Adrian Hilton
Customer Reliability Engineer, SRE
Editor’s note: Left unchecked, poor software architecture decisions are the most common cause of application downtime. Over the years, Google Site Reliability Engineering has learned to spot code that could lead to outages, and strives to identify it before it goes into production as part of its production readiness review. With the introduction of Customer Reliability Engineering, we’re taking the same best practices we’ve developed for internal systems, and extending them to customers building applications on Google Cloud. This is the first post in a series written by CREs to highlight real-world problems — and the steps we take to avoid them.
Distributed Denial of Service (DDoS) attacks aren’t anything new on the internet, but thanks to a recent high profile event, they’ve been making fresh headlines. We think it’s a convenient moment to remind our readers that the biggest threat to your application isn’t from some shadowy third party, but from your own code!
What follows is a discussion of one of the most common software architecture design fails — the self-inflicted DDoS — and three methods you can use to avoid it in your own application.
Even distributions that aren’t
There’s a famous saying (variously attributed to Mark Twain, Will Rogers, and others) that goes:It ain’t what we don’t know that hurts us so much as the things we know that just ain’t so.
Software developers make all sorts of simplifying assumptions about user interactions, especially about system load. One of the more pernicious (and sometimes fatal) simplifications is “I have lots of users all over the world. For simplicity, I’m going to assume their load will be evenly distributed.”
To be sure, this often turns out to be close enough to true to be useful. The problem is that it’s a steady state or static assumption. It presupposes that things don’t vary much over time. That’s where things start to go off the rails.
Consider this very common pattern: Suppose you’ve written a mobile app that periodically fetches information from your backend. Because the information isn’t super time sensitive, you write the client to sync every 15 minutes. Of course, you don’t want a momentary hiccup in network coverage to force you to wait an extra 15 minutes for the information, so you also write your app to retry every 60 seconds in the event of an error.
Because you're an experienced and careful software developer, your system consistently maintains 99.9% availability. For most systems that’s perfectly acceptable performance but it also means in any given 30-day month your system can be unavailable for up to 43.2 minutes.
So. Let’s talk about what happens when that’s the case. What happens if your system is unavailable for just one minute?
When your backends come back online you get (a) the traffic you would normally expect for the current minute, plus (b) any traffic from the one-minute retry interval. In other words, you now have 2X your expected traffic. Worse still, your load is no longer evenly distributed because 2/15ths of your users are now locked together into the same sync schedule. Thus, in this state, for any given 15-minute period you'll experience normal load for 13 minutes, no load for one minute and 2X load for one minute.
Of course, service disruptions usually last longer than just one minute. If you experience a 15-minute error (still well within your 99.9% availability) then all of your load will be locked together until after your backends recover. You'll need to provision at least 15X of your normal capacity to keep from falling over. Retries will also often “stack” at your load balancers and your backends will respond more slowly to each request as their load increases. As a result, you might easily see 20X your normal traffic (or more) while your backends heal. In the worst case, the increased load might cause your servers to run out of memory or other resources and crash again.
Congratulations, you’ve been DDoS’d by your own app!
The great thing about known problems is that they usually have known solutions. Here are three things you can do to avoid this trap.
#1 Try exponential backoff
When you use a fixed retry interval (in this case, one minute) you pretty well guarantee that you'll stack retry requests at your load balancer and cause your backends to become overloaded once they come back up. One of the best ways around this is to use exponential backoff.In its most common form, exponential backoff simply means that you double the retry interval up to a certain limit to lower the number of overall requests queued up for your backends. In our example, after the first one-minute retry fails, wait two minutes. If that fails, wait four minutes and keep doubling that interval until you get to whatever you’ve decided is a reasonable cap (since the normal sync interval is 15 minutes you might decide to cap the retry backoff at 16 minutes).
Of course, backing off of retries will help your overall load at recovery but won’t do much to keep your clients from retrying in sync. To solve that problem, you need jitter.
#2 Add a little jitter
Jitter is the random interval you add (or subtract) to the next retry interval to prevent clients from locking together during a prolonged outage. The usual pattern is to pick a random number between +/- a fixed percentage, say 30%, and add it to the next retry interval.In our example, if the next backoff interval is supposed to be 4 minutes, then wait between +/- 30% of that interval. Thirty percent of 4 minutes is 1.2 minutes, so select a random value between 2.8 minutes and 5.2 minutes to wait.
Here at Google we’ve observed the impact of a lack of jitter in our own services. We once built a system where clients started off polling at random times but we later observed that they had a strong tendency to become more synchronized during short service outages or degraded operation.
Eventually we saw very uneven load across a poll interval — with most clients polling the service at the same time — resulting in peak load that was easily 3X the average. Here’s a graph from the postmortem from an outage in the aforementioned system. In this case the clients were polling at a fixed 5-minute interval, but over many months became synchronized:
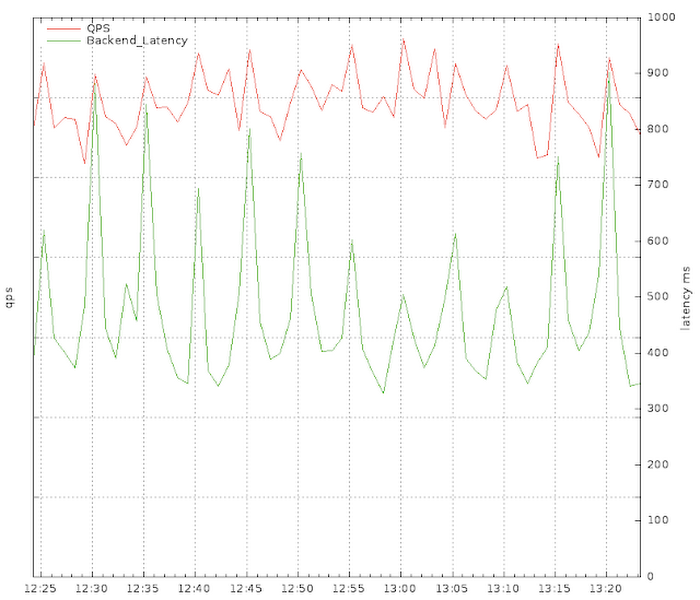
Observe how the traffic (red) comes in periodic spikes, correlating with 2x the average backend latency (green) as the servers become overloaded. That was a sure sign that we needed to employ jitter. This monitoring view is also significantly under-counting the traffic peaks because of its sample interval. Once we added a random factor of +/- 1 minute (20%) to each retry the latency, traffic flattened out almost immediately, with the periodicity disappearing:
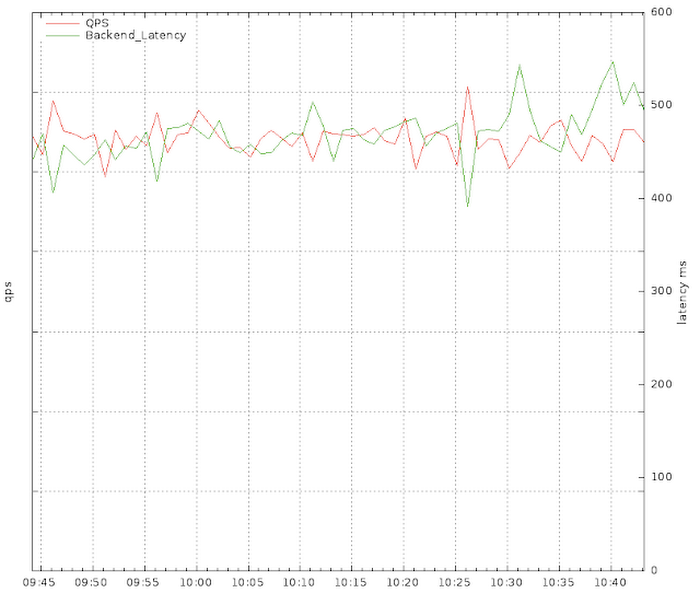
and the backends were no longer overloaded. Of course, we couldn’t do this immediately — we had to build and push a new code release to our clients with this new behavior, so we had to live with this overload for a while.
At this point, we should also point out that in the real world, usage is almost never evenly distributed — even when the users are. Nearly all systems of any scale experience peaks and troughs corresponding with the work and sleep habits of their users. Lots of people simply turn off their phones or computers when they go to sleep. That means that you'll see a spike in traffic as those devices come back online when people wake up.
For this reason it’s also a really good idea to add a little jitter (perhaps 10%) to regular sync intervals, in addition to your retries. This is especially important for first syncs after an application starts. This will help to smooth out daily cyclical traffic spikes and keep systems from becoming overloaded.
#3 Implement retry marking
A large fleet of backends doesn’t recover from an outage all at once. That means that as a system begins to come back online, its overall capacity ramps up slowly. You don’t want to jeopardize that recovery by trying to serve all of your waiting clients at once. Even if you implement both exponential backoff and jitter you still need to prioritize your requests as you heal.An easy and effective technique to do this is to have your clients mark each attempt with a retry number. A value of zero means that the request is a regular sync. A value of one indicates the first retry and so on. With this in place, the backends can prioritize which requests to service and which to ignore as things get back to normal. For example, you might decide that higher retry numbers indicate users who are further out-of-sync and service them first. Another approach is to cap the overall retry load to a fixed percentage, say 10%, and service all the regular syncs and only 10% of the retries.
How you choose to handle retries is entirely up to your business needs. The important thing is that by marking them you have the ability to make intelligent decisions as a service recovers.
You can also monitor the health of your recovery by watching the retry number metrics. If you’re recovering from a six-minute outage, you might see that the oldest retries have a retry sequence number of 3. As you recover, you would expect to see the number of 3s drop sharply, followed by the 2s, and so on. If you don’t see that (or see the retry sequence numbers increase), you know you still have a problem. This would not be obvious by simply watching the overall number of retries.




