Trash talk: How moving Apigee Sense to GCP reduced our “data litter” and decreased our costs
Sridhar Rajagopalan
Software Engineer
In the year-plus since Apigee joined the Google Cloud family, we’ve had the opportunity to deploy several of our services to Google Cloud Platform (GCP). Most recently, we completely moved Apigee Sense to GCP to use its advanced machine learning capabilities. Along the way, we also experienced some important performance improvements as judged by a drop in what we call “data litter.” In this post, we explain what data litter is, and our perspective on how various GCP services keep it at bay. Through this account, you may come to recognize your own application, and come to see data litter as an important metric to consider.
What is data litter?
First, let’s take a look at Apigee Sense and its application characteristics. At its core, Apigee Sense protects APIs running on Apigee Edge from attacks and unwanted exploitation. Those attacks are usually performed by automated processes, or "bots," which run without the permission of the API owner. Sense is built around a four-element "CAVA" cycle: collect, analyze, visualize and act. It enhances human vigilance with statistical machine learning algorithms.We collect a lot of traffic data as a by-product of billions of API calls that pass through Apigee Edge daily. The output end of each of the four elements in the CAVA cycle is stored in a database system. Therefore, the costs, performance and scalability of data management and data analysis toolchains are of great interest to us.
When optimizing an analytics application, there are several things that demand particular attention: latency, quality, throughput and cost.
- Latency is the delay between when something happens and when we become aware of it. In the case of security, we define it as the delay between when a bot attacks and when we notice that the attack.
- The quality of our algorithmic smarts is measured by true and false positives and negatives.
- Throughput measures the average rate at which data arrives into the analytics application.
- Cost, of course, measures the average rate at which dollars (or other currency) leave your wallet.
Sources of data litter
Generally speaking, there are three main sources of data litter in an analytical application like Apigee Sense.- Timeliness of analysis: It’s the nature of a data-driven analysis engine like Sense to attempt to make a decision with all the data available to it when the decision needs to be made. A delayed decision is of little value in foiling an ongoing bot attack. Therefore, when there's little data available to make decisions, the engine makes a less-informed decision and moves on. Any data that arrives subsequently is discarded because it is no longer useful, as the decision has already been made. The result? Data litter.
- Elasticity of data processing: If data arrives too quickly for the analysis engine to consume, it piles up and causes "data back pressure." There are two remedies. First, to increase the size (and cost) of the analysis engine, or, alternately, to drop some data to relieve the pressure. Because you can’t scale up an analysis engine instantly, or because it is cost-prohibitive, we build a pressure release valve into the pipeline, causing data litter.
- Scalability of the consumption chain: If the target database is down, or unable to consume the results at the rate at which they're produced, you might as well stop the pipeline and discard the incoming data. It's pointless to analyze data when there's no way to use or store the results of the analysis. This too causes data litter.
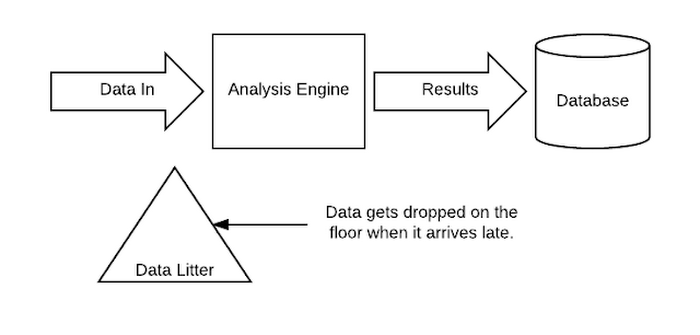
The easiest way to deal with the first kind of data litter is to slow down the pipeline by increasing latency. The easiest way to address the second kind is to throw money at the problem and run the analysis engine on a larger cluster. And the final problem is best addressed by adding more or bigger hardware to the database. Whichever path we take, we either increase latency and lose relevance, or lose money.
Moving to GCP
At Apigee, we track data litter with the data coverage metric, which is, roughly speaking, the inverse measure of how much of data gets dropped or otherwise doesn’t contribute to the analysis. When we moved the Sense analytics chain to GCP, the data coverage metric went from below 80% to roughly 99.8% for one of our toughest customer use cases. Put another way, our data litter decreased from over 20%, or one in five, to approximately one in five hundred. That’s a decrease of a factor of approximately 100, or two orders of magnitude!The chart below shows the fraction of data available and used for decision making before and after our move to GCP. The chart shows the numbers for four different APIs, representing a subset of Sense customers.
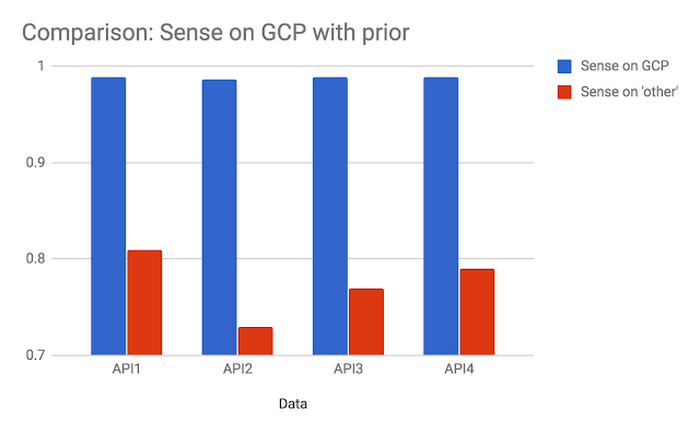
These improvements were measured even while the cost of the deployed system, as well its the pipeline latency, were simultaneously tightened. Meanwhile, our throughput and algorithms stayed the same, and latencies and cost both dropped. Since the release a couple of months ago, these savings, along with the availability and performance benefits of the system, have persisted, while our customer base and the processed traffic has grown. So we're getting more reliable answers more quickly than we did before and paying less than we did for almost the exact same use case. Wow!
Where did the data litter go?
There were two problems that accounted for the bulk of the data litter in the Sense pipeline. These were the elasticity of data processing and the scalability of the transactional store.To alert customers of an attack as quickly as possible, we designed our system with adequate latency to avoid systematic data litter. In our environment, two features of the GCP platform contributed most significantly to the reduction of unplanned data litter.:
- System elasticity. The data rate coming into the system is never uniform, and is especially high when there is an ongoing attack. The system is most under pressure when it is of highest value and needs to have enough elasticity to be able to deal with spikes without being provisioned significantly above the median data rates. Without this, the pressure release valve needs to be constantly engaged.
- Transactional processing power. The transactional load on the database at the end of the chain peaks during an attack. It also determines the performance characteristics of the user experience and of protective enforcement, both of which add to the workload when an API is under attack. Therefore, transactional loads need to be able to comfortably scale to meet the demands of the system near its limits.
We also moved our target database to BigQuery. BigQuery distributes and scales cost-effectively and without hiccups well beyond our needs, and indeed, beyond most reasonable IT budgets. This completely eliminated the back pressure issue from the end of the chain.
Because two of the three sources of data litter are now gone, our team is able to focus on improving the timeliness of our analysis—ensuring that we move data from where it's gathered through the analysis engine and make more intelligent and more relevant decisions with lower latency. This is what Sense was intended to do.
By moving Apigee Sense to GCP, we feel that we’ve taken back the control of our destiny. I'm sure that our customers will notice the benefits not just in terms of a more reliable service, but also in the velocity with which we are able to ship new capabilities to them.



