Google shares software network load balancer design powering GCP networking
Danielle E. Eisenbud
Technical Lead, Maglev
Paul Newson
SRE Mission Controller
At NSDI ‘16, we're revealing the details of Maglev1, our software network load balancer that enables Google Compute Engine load balancing to serve a million requests per second with no pre-warming.
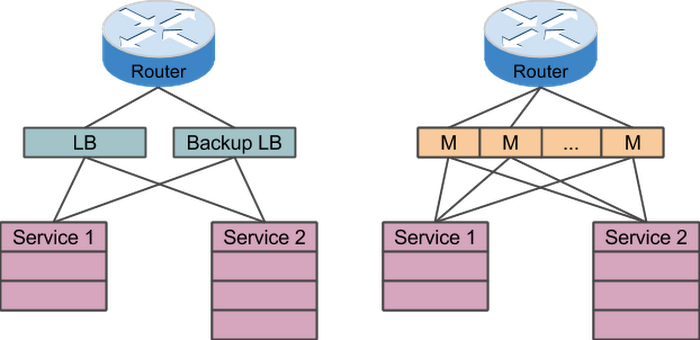
Google has a long history of building our own networking gear, and perhaps unsurprisingly, we build our own network load balancers as well, which have been handling most of the traffic to Google services since 2008. Unlike the custom Jupiter fabrics that carry traffic around Google’s data centers, Maglev load balancers run on ordinary servers — the same hardware that the services themselves use.
Hardware load balancers are often deployed in an active-passive configuration to provide failover, wasting at least half of the load balancing capacity. Maglev load balancers don't run in active-passive configuration. Instead, they use Equal-Cost Multi-Path routing (ECMP) to spread incoming packets across all Maglevs, which then use consistent hashing techniques to forward packets to the correct service backend servers, no matter which Maglev receives a particular packet. All Maglevs in a cluster are active, performing useful work. Should one Maglev become unavailable, the other Maglevs can carry the extra traffic. This N+1 redundancy is more cost effective than the active-passive configuration of traditional hardware load balancers, because fewer resources are intentionally sitting idle at all times.
Google’s highly flexible cluster management technology, called Borg, makes it possible for Google engineers to move service workloads between clusters as needed to take advantage of unused capacity, or other operational considerations. On Google Cloud Platform, our customers have similar flexibility to move their workloads between zones and regions. This means that the mix of services running in any particular cluster changes over time, which can also lead to changing demand for load balancing capacity.
With Maglev, it's easy to add or remove load balancing capacity, since Maglev is simply another way to use the same servers that are already in the cluster. Recently, the industry has been moving toward Network Function Virtualization (NFV), providing network functionality using ordinary servers. Google has invested a significant amount of effort over a number of years to make NFV work well in our infrastructure. As Maglev shows, NFV makes it easier to add and remove networking capacity, but having the ability to deploy NFV technology also makes it possible to add new networking services without adding new, custom hardware.
How does this benefit you, as a user of GCP? You may recall we were able to scale from zero to one million requests per second with no pre-warming or other provisioning steps. This is possible because Google clusters, via Maglev, are already handling traffic at Google scale. There's enough headroom available to add another million requests per second without bringing up new Maglevs. It just increases the utilization of the existing Maglevs.
Of course, when utilization of the Maglevs exceeds a threshold, more Maglevs are needed. Since the Maglevs are deployed on the same server hardware that's already present in the cluster, it's easy for us to add that capacity. As a developer on Cloud Platform, you don’t need to worry about load balancing capacity. Google’s Maglevs, and our team of Site Reliability Engineers who manage them, have that covered for you. You can focus on building an awesome experience for your users, knowing that when your traffic ramps up, we’ve got your back.
1 D. E. Eisenbud, C. Yi, C. Contavalli, C. Smith, R. Kononov, E. Mann-Hielscher, A. Cilingiroglu, B. Cheyney, W. Shang, and J. D. Hosein. Maglev: A Fast and Reliable Software Network Load Balancer, 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), 2016↩



