Easier integration with Apache Spark and Hadoop via Google Cloud Dataproc Job IDs and Labels
Dennis Huo
Software Engineer, Google Cloud
James Malone
Product Manager, Google Cloud
While APIs and SDKs are extremely useful for integrating cloud services with applications, little-known features and design patterns can often increase the utility of these tools even further. For example, Google Cloud Dataproc, the GCP service for running Apache Spark and Apache Hadoop clusters in a simpler, more cost-efficient way, provides two APIs, one REST and one RPC API. Moreover, Cloud Dataproc is integrated with the Google Cloud SDK for command-line scripting and provides a number of automatically-generated SDKs such as Java and Python artifacts. However, many users are unaware that the user-specified Job IDs feature and a design pattern based on Cloud Dataproc labels can be equally helpful for development. In this blog post, we’ll provide some best practices for using them to integrate your apps with the service in a highly productive way.
User-specified Job IDs
Cloud Dataproc provides a mechanism to send Spark, Apache Pig, Apache Hive and Hadoop work to a running cluster. Using the REST API as an example, the request body for a job submission is relatively simple:As you can see, the request only contains a Job object. If you look at the Job object, you'll notice that it contains a JobReference object:
This is important because the JobReference determines how a job is assigned an ID. If you look at a JobReference you'll notice there's an optional jobID field. If this field is blank, Cloud Dataproc will automatically assign the job a new GUID. You can, however, specify your own ID, provided you follow the naming rules in the documentation, instead of accepting the GUID Cloud Dataproc assigns.
This is a potentially powerful and less-known mechanism for integrating with Cloud Dataproc. By specifying a user-supplied ID, you avoid the need to store and track an arbitrary ID generated by a foreign system. Instead, you can use whatever primary key is generated by your application for submission, tracking and reporting. You can avoid this “store job GUID” step entirely.
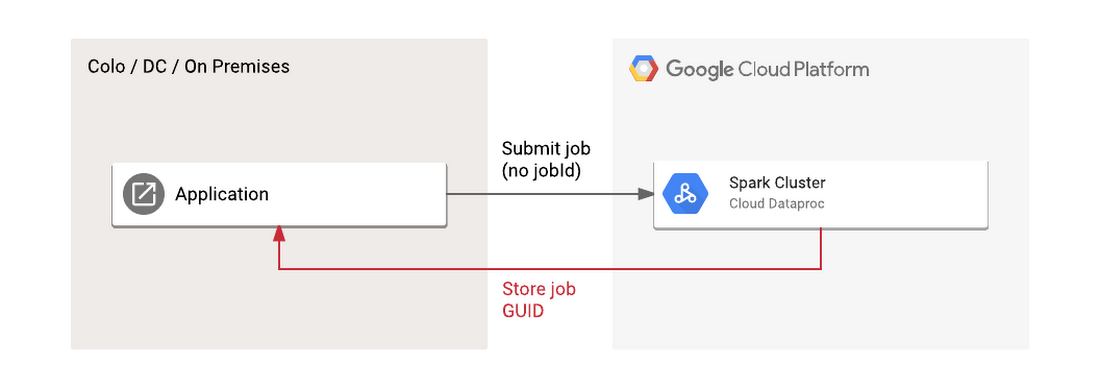
For example, consider a case where you have an application that periodically submits Spark jobs to a running Cloud Dataproc cluster based on a customer request. If you accept the auto-generated GUID, you'll need to store that information somewhere, likely back in the system which submitted the job. In contrast, if you submit the job with a user-specified ID you can use whatever primary key is used by the sending system.
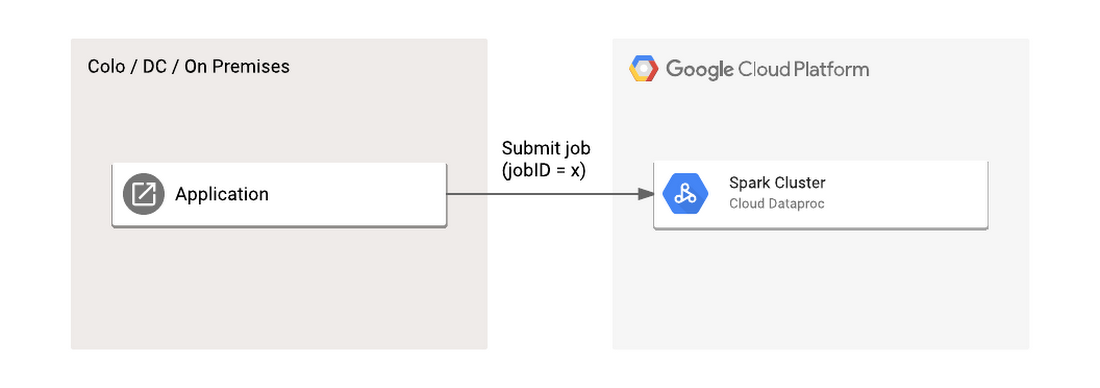
Beyond simplifying your control flow for keeping track of job IDs, it's also considered a general best-practice guideline to specify your own job IDs where possible to ensure clean error-handling and idempotency of low-level retries potentially issued by your client library or intermediate proxy services if applicable. This same principle applies to other related data processing services, such as Google BigQuery.
User-specified label load balancing
Cloud Dataproc, like many Google Cloud services, supports user-specified labels. Labels are key:value pairs that you can associate with Cloud Dataproc clusters and jobs. While there are many uses of labels, such as filtering resources, determining costs and separating dev/prod environments, one particularly interesting use of labels is load balancing.There are many reasons you might want to load balance between multiple Cloud Dataproc clusters. For example, you might want to A/B test different configurations or software packages and stay load-balanced between them, or you might want to add and remove clusters to a pool based on cost or the need to upgrade clusters. Furthermore, while it's often most effective to use fully ephemeral clusters per job, there may be situations where you find it more convenient to have some "always-on" pool of clusters that are reused for many jobs. User-specified labels provide an efficient mechanism for load balancing across such a pool of clusters while retaining the benefits of cloud elasticity
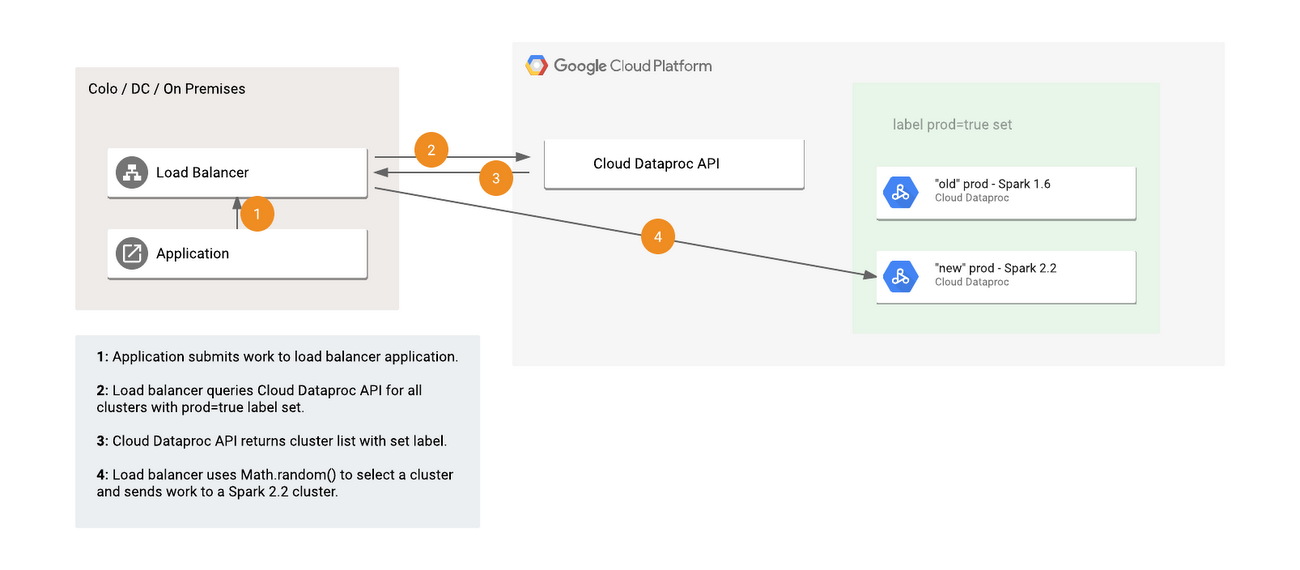
As an example, suppose you want to upgrade the version of Spark used in your application without any downtime and need a reusable process for upgrading. In this case, you can use a control flow for submitting your jobs that:
- Asks Cloud Dataproc for a list of all clusters with a specified label, such as “prod=true”
- Picks one of the returned clusters for job submission, either based on business logic (such as preferring the oldest or newest cluster in the pool depending on the workload) or random selection
- Submits the job to that cluster
In the response, you'll get a list of all clusters that have this label set.
In this example, all of your running clusters that should accept production work will have the label “prod=true” added to them. If you want to add a new cluster with an upgraded version of spark, therefore, you only need to add a new cluster with the label “prod=true” attached. Likewise, you can drain (finish all pending work) and remove a cluster by simply:
- Removing the “prod=true” label
- Waiting for all work to finish
- Deleting the cluster
Once your project grows and you begin to manage multiple separate types of recurring workloads which may benefit from drastically different cluster types, this same design pattern easily extends to adding more dimensions of labels. For example, you might run two separate pools of clusters, adding a label “workload=daily-logs-aggregator” to one pool and “workload=spark-recommendation-engine” to the other, while still using the “prod=true” label to delineate currently active versus draining clusters.
As an added benefit, Cloud Dataproc propagates user labels through to the underlying Google Compute Engine infrastructure and billing systems, allowing you to attribute your costs to particular Cloud Dataproc clusters and labels through your exported billing data.
As this example load-balancing application shows, labels provide a powerful mechanism to integrate with and manage work on Cloud Dataproc clusters.



