Distributed TensorFlow and the hidden layers of engineering work
Brad Svee
Staff Cloud Solutions Architect
With all the buzz around Machine Learning as of late, it’s no surprise that companies are starting to experiment with their own ML models, and a lot of them are choosing TensorFlow. Because TensorFlow is open source, you can run it locally to quickly create prototypes and deploy fail-fast experiments that help you get your proof-of-concept working at a small scale. Then, when you’re ready, you can take TensorFlow, your data, and the same code and push it up into Google Cloud to take advantage of multiple CPUs, GPUs or soon even some TPUs.
When you get to the point where you’re ready to take your ML work to the next level, you will have to make some choices about how to set up your infrastructure. In general, many of these choices will impact how much time you spend on operational engineering work versus ML engineering work. To help, we’ve published a pair of solution tutorials to show you how you can create and run a distributed TensorFlow cluster on Google Compute Engine and run the same code to train the same model on Google Cloud Machine Learning Engine. The solutions use MNIST as the model, which isn’t necessarily the most exciting example to work with, but does allow us to emphasize the engineering aspects of the solutions.
We’ve already talked about the open-source nature of TensorFlow, allowing you to run it on your laptop, on a server in your private data center, or even a Raspberry PI. TensorFlow can also run in a distributed cluster, allowing you divide your training workloads across multiple machines, which can save you a significant amount of time waiting for results. The first solution shows you how to set up a group of Compute Engine instances running TensorFlow, as in Figure 1, by creating a reusable custom image, and executing an initiation script with Cloud Shell. There are quite a few steps involved in creating the environment and getting it to function properly. Even though they aren’t complex steps, they are operational engineering steps, and will take time away from your actual ML development.
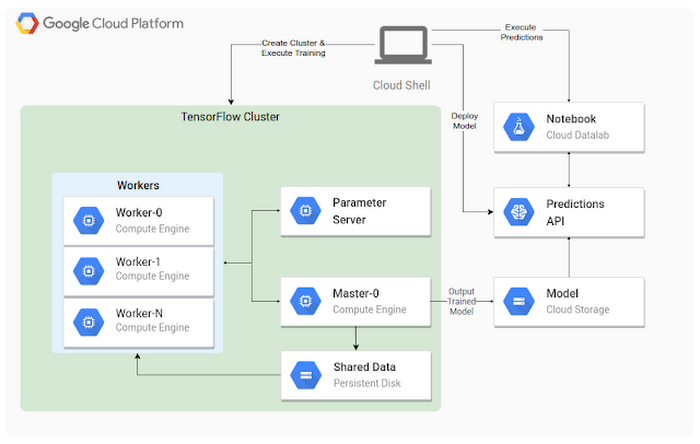
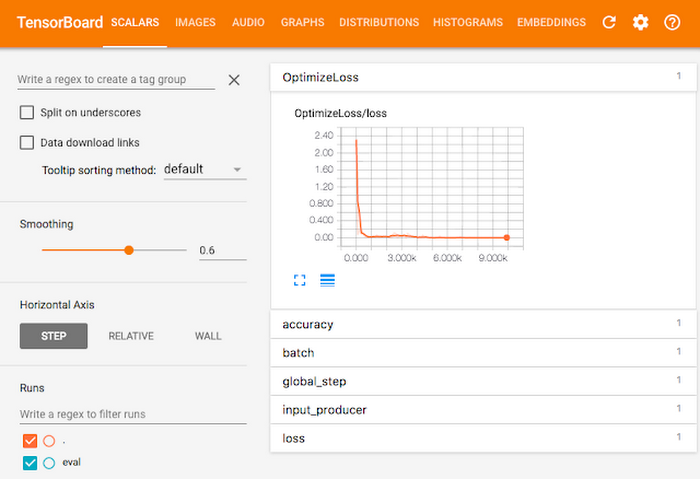
The second solution uses the same code with Cloud ML Engine, and with one command you’ll automatically provision the compute resources needed to train your model. This solution also delves into some of the general details of neural networks and distributed training. It also gives you a chance to try out TensorBoard to visualize your training and resulting model as seen in Figure 2. The time you save provisioning compute resources can be spent analyzing your ML work more deeply.
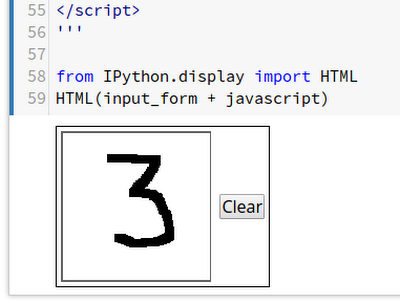
Regardless of how you train your model, the whole point is you want to use it to make predictions. Traditionally, this is where the most engineering work has to be done. In the case where you want to build a web-service to run your predictions, at a minimum, you’ll have to provision, configure and secure some web servers, load balancers, monitoring agents, and create some kind of versioning process. In both of these solutions, you’ll use the Cloud ML Engine prediction service to effectively offload all of those operational tasks to host your model in a reliable, scalable, and secure environment. Once you set up your model for predictions, you’ll quickly spin up a Cloud Datalab instance and download a simple notebook to execute and test the predictions. In this notebook you’ll draw a number with your mouse or trackpad, as in Figure 3, which will get converted to the appropriate image matrix format that matches the MNIST data format. The notebook will send your image to your new prediction API and tell you which number it detected as in Figure 4.
This brings up one last and critical point about the engineering efforts required to host your model for predictions, which is not deeply expanded upon in these solutions, but is something that Cloud ML Engine and Cloud Dataflow can easily address for you. When working with pre-built machine learning models that work on standard datasets, it can be easy to lose track of the fact that machine learning model training, deployment, and prediction are often at the end of a series of data pipelines. In the real world, it’s unlikely that your datasets will be pristine and collected specifically for the purpose of learning from the data.
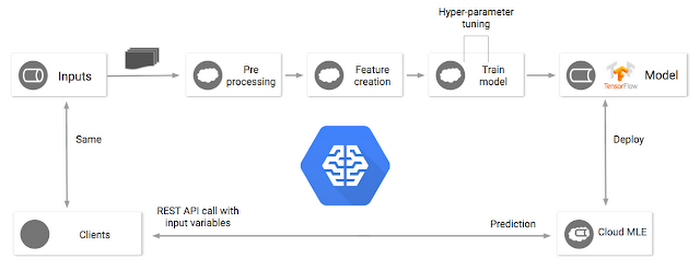
Rather, you’ll usually have to preprocess the data before you can feed it into your TensorFlow model. Common preprocessing steps include de-duplication, scaling/transforming data values, creating vocabularies, and handling unusual situations. The TensorFlow model is then trained on the clean, processed data.
At prediction time, it is the same raw data that will be received from the client. Yet, your TensorFlow model has been trained with de-duplicated, transformed, and cleaned-up data with specific vocabulary mappings. Because your prediction infrastructure might not be written in Python, there is a significant amount of engineering work necessary to build libraries to carry out these tasks with exacting consistency in whatever language or system you use. Many times there is too much inconsistency in how the preprocessing is done before training versus how it’s done before prediction. Even the smallest amount of inconsistency can cause your predictions to behave poorly or unexpectedly. By using Cloud Dataflow to do the preprocessing and Cloud ML Engine to carry out the predictions, it’s possible to minimize or completely avoid this additional engineering work. This is because Cloud Dataflow can apply the same preprocessing transformation code to both historical data during training and real-time data during prediction.



