Comparing regression and classification on US elections data with TensorFlow Estimators
Sara Robinson
Developer Advocate, Google Cloud Platform
The first question I ask when solving a machine learning problem is: what am I trying to predict? This helps me choose the right algorithm to use for the job. Do I want to use input data to predict a numerical value, or do I want to classify my input data into one or more categories? If I’m predicting a value (given historical data, predict the temperature in a given location), I’ll use a regression algorithm. If I’m predicting a category (given a news article, determine whether it should be categorized as politics, business, or tech), I’ll use a classification algorithm. In this example we’ll show binary classification. You can also use a classification algorithm to solve multi-class classification problems when you have more than two classes you want to predict.
To get a better understanding of regression versus classification in TensorFlow, I wanted to try both using the same dataset. In this post, we’ll explore regression and classification using this Elections 2016 dataset from Kaggle. Note that because demographic data changes over time, this model might not work on predicting the results of a future election. We're simply using this dataset to compare two types of models on the same dataset.
The inspiration for this post came from this great intro to TensorFlow Estimators and Datasets.
Analyzing the dataset
The dataset includes 3,112 rows for nearly every county in the US. Each row contains demographic data on the county’s population, race, gender, and the percentage of the county that voted for each candidate in the 2012 and 2016 elections. I downloaded a comma-separated values (CSV) file of the of the data and uploaded it to BigQuery to determine which columns to choose as features. Features refers to the data we’ll feed into our model. The output or prediction is called the label.I wanted to predict the way each county voted in 2016. There are two ways to do this, depending on whether I decide to use regression or classification:
- Regression: predict the percentage of the population who voted for Clinton or Trump in each county. The output would be a floating point value ranging from 0 to 1.
- Classification: predict which candidate the county voted for. The output would be binary classes of either 0 or 1, corresponding to Clinton or Trump.
The type of model you should use largely depends on the problem you’re solving. Let’s say I want to predict which way each county will vote in the next election—I should probably go with classification. But what if I want to target potential swing counties, where the majority candidate got only 40% to 60% of the vote? If we look at two counties that voted for the same candidate but one had 51% of the vote and the other had 95%, the classification model will give the same output for both. If we care about these differences, we’ll want to use a regression model.
Since the dataset already provides the percentage of each county voting for Clinton or Trump, I’ll start by solving this as a regression problem. To do that I’ve selected 7 data points to use as features, and I’ll use the percentage of each county that voted for Clinton as my label:
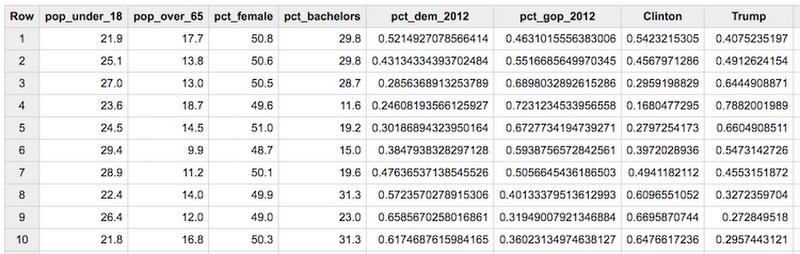
After extracting the features and labels I’ll use in my model, I downloaded the output of the query as a CSV and split it into training and test files. I used 2,500 examples for training and reserved 500 for testing.
Building a regression model with TensorFlow Estimators
We’ll first solve this prediction task by building a regression model to predict the percentage of a county voting for a particular candidate. To do this we’ll use theLinearRegressor provided by the TensorFlow Estimator class. If you aren’t familiar with Estimators, they provide a high level way to create ML models with TensorFlow. You can choose from pre-built Estimators like the LinearRegressor I’ll be using, or if you need more control over how your model works under the hood, you can build a custom estimator.To use an Estimator, I define a function that returns my features and labels packaged in the correct format to feed into the model. There are many ways to define input functions; in this example I’m going to use the new Datasets API, which provides a more performant way to create input pipelines introduced in TensorFlow 1.4. Before defining my input function, I’ll create a variable to store my feature names:
In decode_csv, I convert each line of the csv to a dictionary of features (the first 7 values) and labels (the last value in a row). Each value in my csv is a float, which I tell TensorFlow by passing it [0.] when I call tf.decode_csv.
Then I create my dataset from data in memory using the TextLineDataset class:
All that’s left to do before I create my Estimator is defining my feature columns. Feature columns in TensorFlow describe the structure of the input data we’ll feed into the model. Each of my features are floats, so I can initialize my list of feature columns with one line of code:
These feature columns are the only argument I need to pass when creating my LinearRegressor:
I can now use my Estimator to run training, evaluation, and prediction.
Before we move on, let’s take a moment to appreciate the value of TF Estimators—think about all the code we’re not writing! The LinearRegressor Estimator sets up the internals of our entire machine learning model for us: building a new TensorFlow graph, defining the regression function our model will use, assigning weights and biases, and saving model checkpoints throughout training. All we need to do is write one line of code to make use of everything the Estimator provides.
Note that we haven’t yet connected our model to our training and test data files. Using input columns, we’ve simply defined the structure and type of our features. The Estimator itself doesn’t care about our training or test data, we only need to pass it to the train and evaluate methods. To do that, we’ll use our input function to tell TensorFlow which piece of data to associate with each feature.
With my Estimator ready to go, I can run training with only one line of code. I’ll pass 10 in as the repeat_count—this means the model will iterate over my entire dataset 10 times, updating the weights and biases in the model each time to minimize error:
We use lambda above to call the input function with our desired arguments (more on that in this blog post). When training runs you should see a loss (or error) value after each iteration. This can be useful but we care more about the evaluation loss since this will test our model on data it hasn’t seen before:
After running evaluation, you should see a loss of around .01. This seems low but we need a better way to see exactly how well our model is performing. For regression models, we can’t rely on a more straightforward measure like accuracy (i.e. 95 out of 100 examples were classified correctly). Does a predicted value of .23 when the actual percentage was .25 count as a “correct” prediction from our model? That’s up to us, and is dependent on the problem we’re trying to solve.
To see how our model performs on actual data, let’s generate some predictions on a few examples in our test set. Here are the 7 features for 3 examples in our test dataset. See the comment below for the actual values for each example:
We’ll write a new test_input_fn to convert this raw feature data into a Dataset and create a variable with the prediction results:
We can then print the prediction results and compare them to the actual percentages from the prediction_input code block above:
All of our model’s predictions for these 3 examples are within 1% of their actual value. Check out a notebook with the full regression model on GitHub.
Converting our model to a LinearClassifier
Now that we’ve solved this as a regression problem, let’s switch gears and try it with a classification model. The great thing about TensorFlow Estimators is that we barely have to change any of our code to use an entirely new type of model. Because we’re now want our model to output labeled classes (0 for Trump, 1 for Hillary), I wrote a preprocessing script that checks whether the label value in our previous dataset (% for Hillary) is less than 0.50. If it is, we set the label to 0 and if not we set it to 1.With our training and test data now formatted correctly for classification, the only line we have to change is the one where we create the Estimator:
Again, this is pretty crazy! The entire underlying model I’m using is changing, but I only need to swap out the model type in one line of code to get it working. When I run evaluation on my LinearClassifier, I get more values back than just loss:
accuracy is more useful with this type of model than loss. Here it tells me that the model is classifying 96% of my test examples correctly.
Using the same raw prediction_input from above, let’s see how our classifier performs on test data. We’ll use the same test_input_function as we did with our regression model, but the format of our prediction results is different. Instead of getting the value of the prediction, our classifier outputs a softmax probability vector indicating the probability that the inputs correspond with each class. In each array below, the first value indicates the probability that a county voted for Trump and the second value indicates the probability that county voted for Hillary:
On these 3 examples, our classifier model generated the correct predictions for each one. Check out a notebook with the full classification model on GitHub.
What’s next?
As we’ve seen, choosing to use a regression or classification model largely depends on the machine learning problem you’re solving. Luckily, TensorFlow Estimators make it easy to switch between models with minimal code changes. To see all the code and datasets discussed in this post, check out the GitHub repo.Want to start building regression and classification models with your own data? Dive into the documentation for LinearRegressor and LinearClassifier. For data inspiration, check out Kaggle or the BigQuery Public Datasets. Have questions or ideas for future posts? Find me on Twitter @SRobTweets.



