Optimizing RAG retrieval: Test, tune, succeed
Hugo Selbie
Staff Customer & Partner Solutions Engineer, Google
Tom Pakeman
Customer Partner & Solutions Engineer
Retrieval-augmented generation (RAG) supercharges large language models (LLMs) by connecting them to real-time, proprietary, and specialized data. This helps LLMs deliver more accurate, relevant, and contextually aware responses, minimizing hallucinations and building trust in AI applications.
But RAG can be a double-edged sword: while the concept is straightforward – find relevant information and feed it to the LLM – its implementation is difficult to master. Done incorrectly, it can impact user trust in your AI's reliability. The culprit is often a lack of thorough evaluation. RAG systems that are not thoroughly evaluated lead to ‘silent failures’ which can undermine the reliability and trustworthiness of the system as a whole.
In this blog post, we'll equip you with a series of best practices to identify issues within your RAG system and fix them with a transparent, automated evaluation framework.
Step 1. Create a testing framework
Testing a RAG system consists of running a set of queries against the tool and evaluating the output. A key prerequisite for rapid testing and iteration is to decide on a set of metrics as the definition of success, and calculate them in a rigorous, automated, and repeatable fashion. Below are some guidelines:
-
Assemble a test dataset of high-quality questions
-
Ensure that your test set covers a broad subset of the underlying data, and includes variations in phrasing and question complexity that match real-world use cases.
-
Pro tip: It’s a good idea to consult with stakeholders and end users here to ensure the quality and relevance of this dataset.
-
Assemble a ‘golden’ reference dataset of desired outputs to use in evaluation
-
Although some metrics can be calculated without a reference dataset, having a set of known-good outputs allows us to produce a more comprehensive and nuanced range of evaluation metrics.
-
Only change one variable at a time between test runs
-
There are many features of a RAG pipeline that can make a difference – by changing them one at a time, we can be sure that a change in evaluation scores is attributable to a single feature alone.
-
Similarly, we must ensure that between test runs we do not change the evaluation questions being used, the reference answers, or any system-wide parameters and settings.
The basic process here is to change one aspect of the RAG system, run the battery of tests, adapt the feature, run the exact same battery of tests again and then see how the test results have changed. Once you are satisfied that a feature cannot be improved, freeze the configuration and move on to testing a separate part of the process.
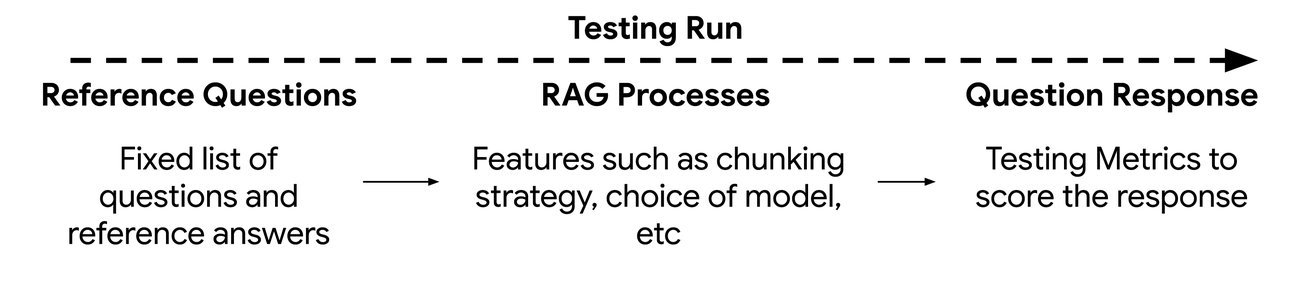
This testing framework can be visualized as three components:
-
Reference questions and answers:
-
The set of queries to be evaluated. Depending on which metrics are being calculated we may include corresponding reference answers.
-
RAG processes
-
The retrieval and summarization techniques being changing and evaluated
-
Question outputs
-
The evaluation outputs as scored by the testing framework
Choosing appropriate metrics
Establishing the best metrics to assess your system involves trial and error. Predefined testing frameworks exist that have been designed to speed up the process by providing prebuilt metrics that can also be adapted to your specific use case. This allows you to quickly generate baseline scores for the evaluation and refinement of your RAG system. From this baseline, you can then systematically modify retrieval and generation capabilities and measure any improvements.
Common RAG evaluation frameworks include:
Ragas
Ragas is an open-source tool for evaluating RAG systems. It measures key aspects like factual accuracy, answer relevance, and how well retrieved content matches the question. Ragas also helps generate test data, making it easier for developers to improve RAG systems for accuracy and usefulness.
Vertex AI gen AI evaluation service
The Vertex AI gen AI evaluation service helps users test and compare generative models or applications based on custom metrics. It supports model selection, prompt engineering, and fine-tuning and allows users to define metrics, prepare data, run evaluations, and review results. The service works with Google's models, third-party models, and open models across various languages, using both model-based and computation-based assessment methods.
Example metrics
Model-based metrics utilize a proprietary Google model to assess the output of a candidate model. Functioning as an evaluator, this model scores responses based on predefined criteria.
-
Pointwise metrics: The judge model assigns a numerical score (e.g., on a scale of 0-5) to the candidate model's output, indicating its alignment with the evaluation criteria. A higher score signifies a better fit.
-
Pairwise metrics: The judge model compares the responses of two models and identifies the superior one. This approach is frequently employed to benchmark a candidate model against a baseline model.
Computation-based metrics: These metrics utilize mathematical formulas to compare the model's output against a ground truth or reference. Popular examples include ROUGE and BLEU.
Opinionated tiger team actions
-
Collaborate with stakeholders to develop a set of "golden" question inputs. These questions should accurately reflect the main use cases the RAG system is intended to address. It's crucial to include a diverse range of query types, such as simple, complex, multi-part, and misspelled queries to ensure comprehensive testing.
-
Make use of the Vertex AI generative AI evaluation framework. This framework allows developers to quickly implement multiple test metrics, and run multiple tests on a model’s performance with minimal setup. It offers a fast feedback loop, so improvements can be made rapidly.
-
Conduct a pointwise evaluation of the RAG retrieval system.
-
Generate model scores based on the following criteria:
-
Response groundedness: The extent to which the generated text aligns with the factual information retrieved from the source documents.
-
Verbosity: The length and detail of the response. While beneficial for providing comprehensive understanding, excessive verbosity may indicate difficulty in concisely and accurately answering the question. You may wish to tune this metric based on your use case.
-
Instruction following: The system's ability to generate text that accurately and comprehensively adheres to given instructions, ensuring the output is relevant and aligned with user intent.
-
Question answer quality as related to instructions: The ability of the RAG system to generate text that correctly answers a user's question with a high level of detail and coherence.
-
Store results in a shared location such as Vertex AI Experiments, which allows for simple comparisons over time.
Step 2. Root cause analysis and iterative testing
The goal of setting up a repeatable testing framework is ideally understanding the root cause of issues. RAG is fundamentally based on two components: (1) the retrieval accuracy of your nearest neighbor matches and (2) the context that you provide to the LLM that generates your responses.
Identifying and isolating these components individually allows you to determine the specific areas that may be causing problems and formulating testable hypotheses that can be performed as experiments and run in Vertex AI using the Gen AI evaluation framework.
Typically when performing a root cause analysis exercise, the user will execute a testing run as a baseline, modify the implementation of one of the RAG components, and re-execute the testing run. The delta between the output scores of the testing metrics is the influence of the RAG component that was altered. The goal in this phase is to modify and document the components carefully, aiming to optimize towards a maximum score for each of the chosen metrics. Often the temptation is to make multiple modifications between testing runs which can mask the impact of a specific process and whether it was successful in creating a measurable change in your RAG system.
Examples of RAG experiments to run
Example RAG components to experiment with:
-
What is the ideal number of neighbors for a document chunk that gets passed into an LLM to improve answer generation?
-
How does embedding model choice affect retrieval accuracy?
-
How do different chunking strategies affect quality? For example, adjusting variables like chunk size or overlap, or exploring strategies such as pre-processing chunks to summarize or paraphrase them with a language model.
-
When it comes to generation, simply comparing Model A vs. Model B or Prompt A vs. Prompt B is particularly useful for fine-tuning prompt design or adjusting model configurations, helping developers to optimize models and prompts for specific use cases.
-
What happens when you enrich documents with metadata like title, author, and tags for better retrieval signals?
Opinionated tiger team actions
-
Test model A vs model B for generation tasks (simple and can produce measurable results)
-
Test chunking strategies for retrieval within a single embedding model (400 chars, 600 chars, 1200 chars, Full document text)
-
Test pre-processing of long chunks to summarize them to smaller chunk sizes.
-
Test what data is passed to the LLM as context. For example, do we pass the matched chunks themselves, or use these as a lookup to find the source document and pass the whole document text to the LLM, making use of long context windows.
Step 3. Human evaluation
Although quantitative metrics created by your testing framework provide valuable data, qualitative feedback from real users is also crucial. Automated testing tools are efficient for scalability and rapid iteration, but they cannot replicate human judgment in ensuring high-quality output. Human testers can evaluate subtle aspects like the tone of responses, the clarity of explanations, and potential ambiguity. Combining qualitative and quantitative testing provides a more holistic understanding of your RAG system’s performance.
Human tests are typically run after you’ve achieved a solid level of baseline answer quality by optimizing evaluation metrics through the automated testing framework. You may wish to include human response evaluation as part of your broader user-testing motions for the system as a whole, such as performance, UX, etc. Similar to previous experiments, human testers can focus on specific system features following structured steps, or they can assess the overall application and provide comprehensive qualitative feedback.
Because human testing is time consuming and repetitive, it is essential to identify users who are engaged and willing to provide meaningful feedback.
Opinionated tiger team actions
-
Identify key personas based on the RAG system’s target users
-
Recruit a representative sample of participants that matches these personas to ensure realistic feedback.
-
If possible, include both technical and non-technical user groups for testing
-
Sit with the user (if possible) to ask follow-up questions and dig into the detail of their responses
Conclusion
To begin your own evaluation, explore Google Cloud’s generative AI evaluation service, where you can create both prebuilt and custom evaluation methodologies to enhance your RAG system.



