Build your own machine-learning-powered robot arm using TensorFlow and Google Cloud
Kaz Sato
Developer Advocate, Cloud AI
Norihiro Shimoda
Dept. Manager Infrastructure Development, BrainPad Inc.
At Google I/O 2017 and Cloud Next 2017, we exhibited a demo called Find Your Candy, a robot arm that listens for a voice request with your preferred flavor of candy, selects and picks up a piece of candy with that particular flavor from a table, and serves it to you:


Specifically, you can tell the robot what flavor you like, such as "chewy candy," "sweet chocolate" or "hard mint." The robot then processes your instructions via voice recognition and natural language processing, recommends a particular kind of candy and uses image recognition to recognize and select that recommendation. The entire demo is powered by deep-learning technology running on Cloud Machine Learning Engine (the fully-managed TensorFlow runtime from Google Cloud) and Cloud machine learning APIs.
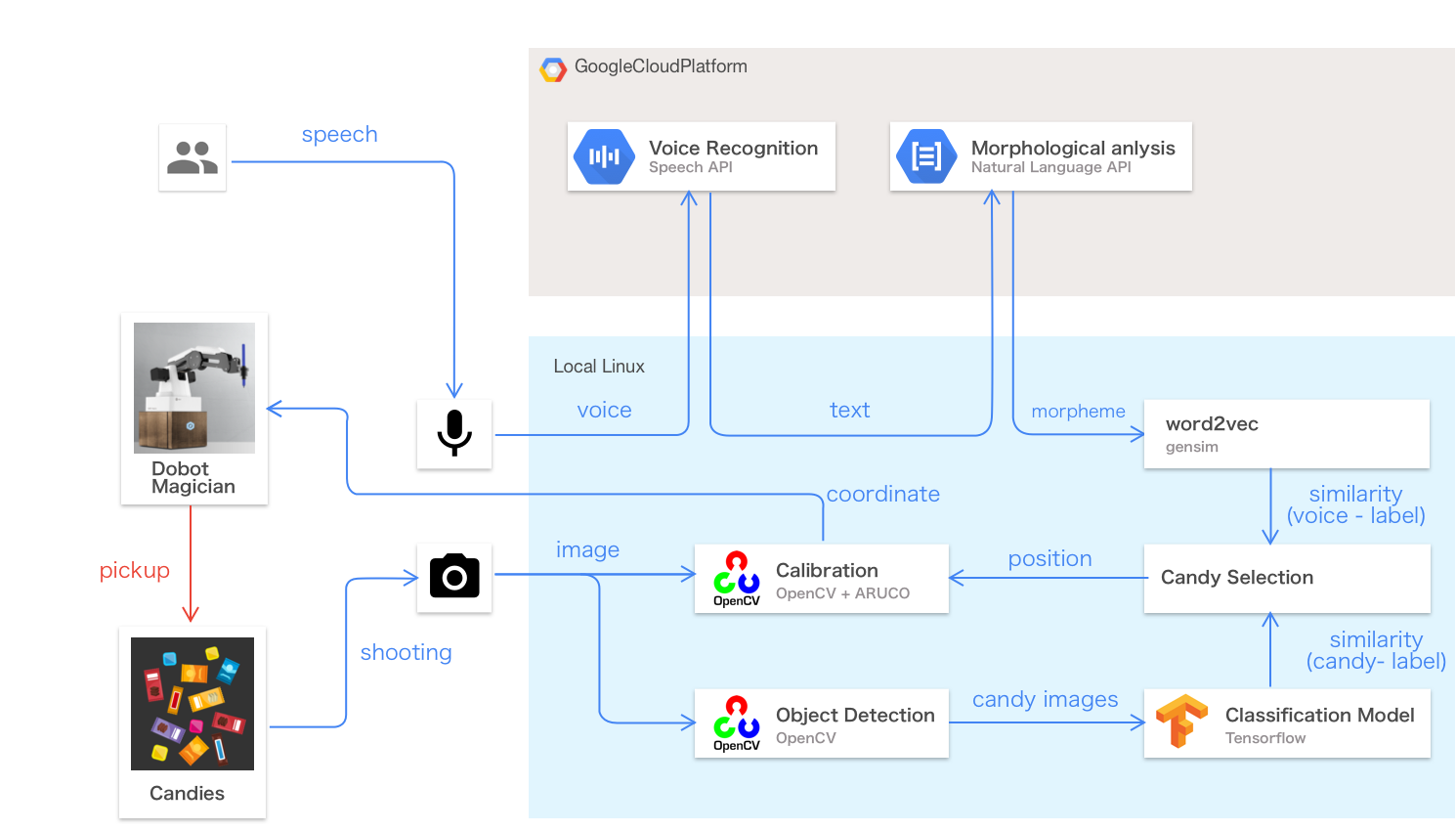
This demo is intended to serve as a microcosm of a real-world machine learning (ML) solution. For example, Kewpie, a major food manufacturer in Japan, used the same Google Cloud technology to build a successful Proof of Concept (PoC) for doing anomaly detection for diced potato in a factory. (See this video for more details).
We also designed the demo to be easily reproduced by developers, with the code published on GitHub. So if you buy the hardware (the robot arm, a Linux PC and other parts — costs around $2,500 total), you should be able to build the same demo, learning how to integrate multiple machine-learning technologies along the way (and having a lot of fun doing it)!
In the remainder of this post, we’ll describe how the demo works in detail and share some challenges we encountered when using it in the field.
Understanding your voice request
The demo starts with your voice request. The robot arm has a web UI app that uses Web Speech API, which uses the same deep learning-based speech recognition engine as Cloud Speech API only exposed as an API for web apps. The recognized text is sent to the Linux PC that serves as the controller, calling Cloud Natural Language API for extracting words and syntax in the sentence. For example, if you were to say "I like chewy mint candy," Cloud Natural Language API would return syntactic analysis results like the following.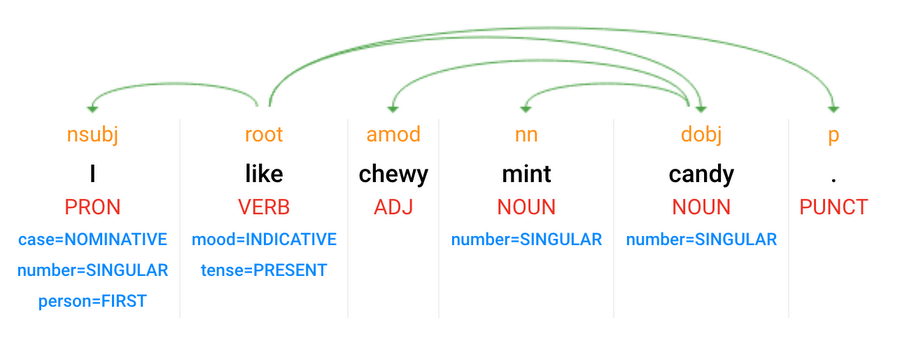
Using "word embeddings" for smarter recommendation
So now the robot arm can learn what kind of flavors you like, such as "chewy," "mint" and "candy." It could use these words directly to pick one of the candies from the table. But instead, even better, the robot runs the word2vec algorithm first to calculate word embeddings for each word in order to make a smarter candy recommendation.A word embedding is a technique to create a vector (an array with hundreds of numbers) that encapsulates the meaning of each word. You can see how it works by visiting the Embedding Projector demo and clicking on any dots in the cloud.
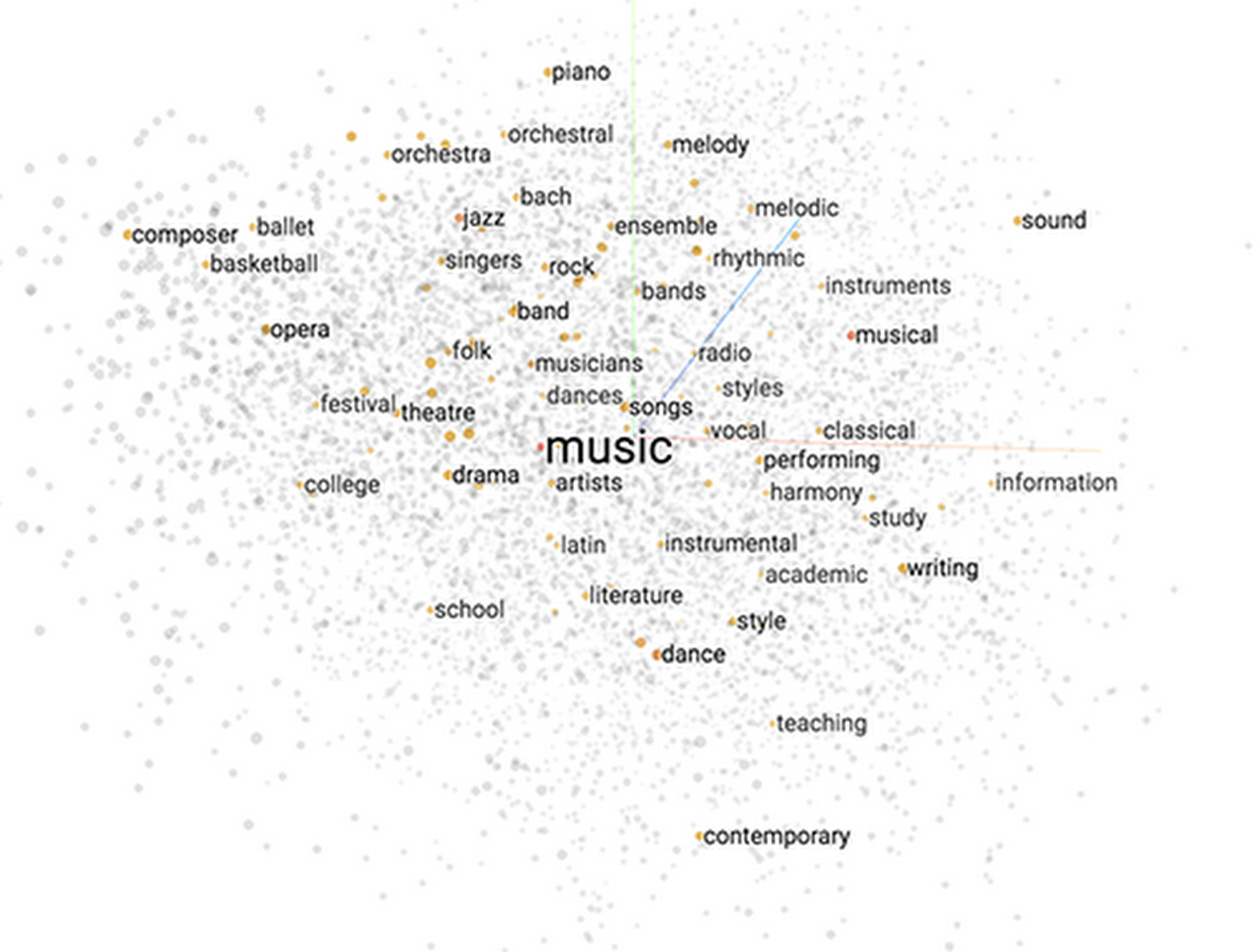
The words similar to "music," shown with Embedding Projector (click here to try it on your own)
As you can see in the demo, each vector has many other vectors close to it that have similar meanings. For the word "music," you'd see words like "songs," "artists" and "dances" closer to that word. This is another powerful application of ML for natural-language processing that adds intelligence to the demo. For example, if you say "creamy" or "spicy," the robot arm knows they have similar meanings to "milky" or "hot" respectively. (You can see the word embeddings analysis result on the Web UI of the robot.)

Instead of using the spoken words directly, using the word embeddings allows the robot to pick the best available candy on the table even if there's no direct match.
Teach the robot with transfer learning
Now it's time to have the robot pick up a candy with the words represented as word embeddings. At this point, you might wonder: "How can the robot know the flavor of each candy on the table?" The answer is: you need to run the robot arm in learning mode before operating it.During learning mode, you place the candies on the table along with labels describing their flavors:

The learning mode involves the following steps:
- The documents camera takes a photo of the candies and labels.
- The Linux PC sends it to Cloud Vision API to read the text on the labels.
- The Linux PC runs OpenCV to recognize the shape of each candy and cuts it out as a smaller image.
To avoid this problem, we use transfer learning, a popular technique to reduce the size of training data, to shorten training time significantly. With transfer learning, you use pre-trained models to extract feature vectors of each image. The vector has a bunch of numbers in it encapsulating image features, such as color, shape, pattern and texture of the image. It's similar to the vectors you get with word embeddings for each word.
In this technique, you train a small neural network model with a few hidden layers with the pairs of labels and feature vectors. In the demo's case, we apply a pre-trained Inception-v3 model to candy images, extract a feature vector with 2,048 dimensions from its last fully-connected layers and use it to train a small fully-connected neural network model on TensorFlow.
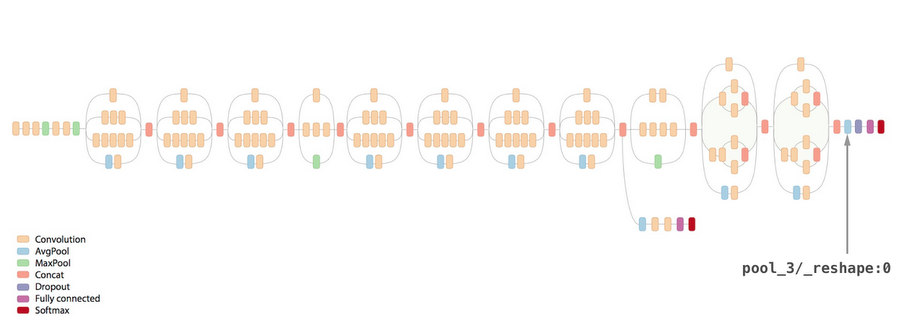
Using those techniques in combination with Cloud Machine Learning Engine, we reduced the number of required sample candies to a few for each label and shortened the training time to several minutes.
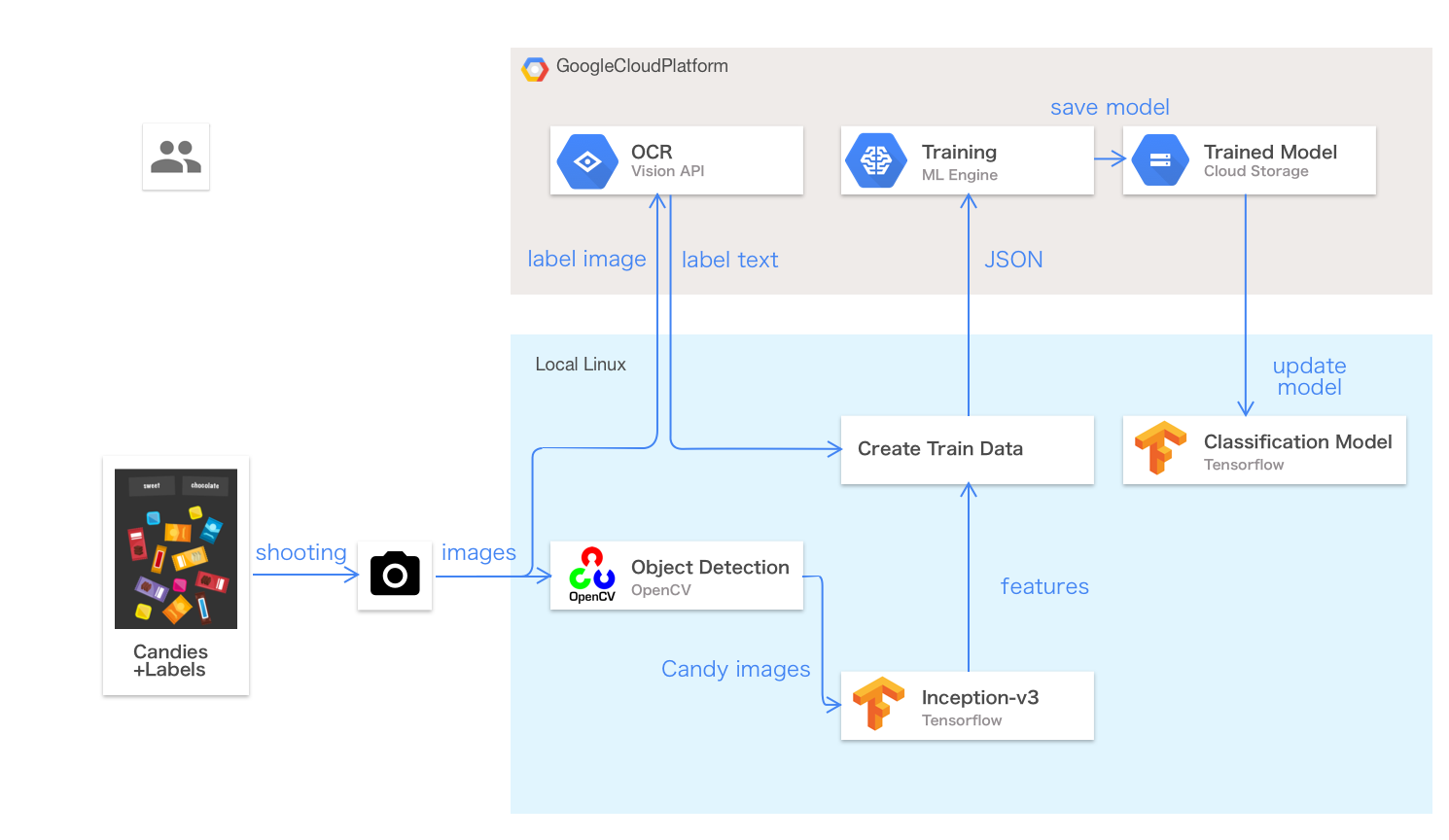
After training the image recognition model during learning mode, the robot's ready to run in serving mode. In serving mode, the robot matches the labels recognized with the model for captured images and matches the labels recommended by the word embeddings with voice commands.
That’s it, the robot arm is now open for business!
Acquiring hardware
As we explained previously, one goal of this demo was to make it affordable for developers to reproduce. For that reason we used Dobot Magician, a commodity robot arm product priced at around $1,500. You would only need to spend $1,000 more to buy the other hardware components, such as a Linux PC for the controller and a documents camera. (You can find the complete list of hardware components on the GitHub repo.) The robot arm exposes an API and we implemented a driver to control the arm with its serial communication protocol. Also, our software includes various tools for calibration, setup and debugging to ensure reliability and stability.Challenges on-site
When operating the demo for Google Cloud Next and Google I/O, we faced a few challenges from which you could learn in your own project:- Light reflection: some captured images included light reflection on the candy packages, which made high image-recognition accuracy difficult. To address this issue, you'd need to include a couple of packages of the same candy for the learning mode.
- Sunlight or spotlight: strong sunlight on the table prevented the demo from working properly.
- Environmental sound: the event venues were comparatively noisy, making voice recognition difficult. The demo is designed to rely on an internal microphone in a tablet, but we had to add an external microphone due to the noisy environment.
- Choosing easy-to-pick candies: the robot arm’s suction cup can pick up an object from the table fairly easily but it also limits what objects can be used (a flat, level face is required). So, we spent some time searching the grocery store for easy-to-pick snacks.
- Everybody loves learning mode: we didn't expect that people would want to use the learning mode, as it takes at least five minutes to run. In reality, many people quickly realized how fun it is to teach the robot arm what to do! So, we made the learning-mode experience much smoother.
Next steps
Thanks to the folks at BrainPad who collaborated with us to design and build this demo within a single month! That’s a big benefit of using TensorFlow and Cloud Machine Learning Engine: you have a huge range of choices from which to find the best partner for delivering a solution for production deployment.Explore this page to learn more about the range of Google Cloud products and services for machine learning.



