AutoML Vision in action: from ramen to branded goods
佐藤一憲
Google Cloud デベロッパーアドボケイト
Take a look at the three ramen bowls below. Can you believe that a machine learning (ML) model can identify the exact shop each bowl is made at, out of 41 ramen shops, with 95% accuracy? Data scientist Kenji Doi built an AI-enabled ramen expert classifier that can discern the minute details that make one shop’s bowl of ramen different from the next one’s.

Ramen Jiro is one of the most popular chain restaurant franchises for ramen fans in Japan, because of its generous portions of toppings, noodles, and soup served at low prices. They have 41 branches around Tokyo, and they serve the same basic menu at each shop.
As you can see in the photo, it's almost impossible for a human (especially if you're new to Ramen Jiro) to tell what shop each bowl is made at. They just look the same. You wouldn’t think you could identify which of the 41 shops made a particular bowl of soup just by looking at one of these photos.
Kenji wondered if deep learning could help with this problem. He collected 48,244 photos from the web of bowls of soup from Ramen Jiro locations. After removing photos that were not suitable for model training (such as duplicates, or photos without ramen bowls), he prepared about 1,170 photos x 41 shops = 48,000 photos with shop labels.
AutoML Vision achieved 94.5% accuracy
While Kenji was working on this, he learned that Google had just launched the alpha version of AutoML Vision.AutoML Vision lets users customize ML models with their own images, without having expertise with designing ML models. To get started, all you need to do is upload image files for training and make sure they’re properly labeled. Once you’ve finished training your customized model, you can easily deploy it on a scalable serving platform, in order to automatically scale your resources to meet demand. The whole process is designed for non data scientists and doesn’t require ML expertise.
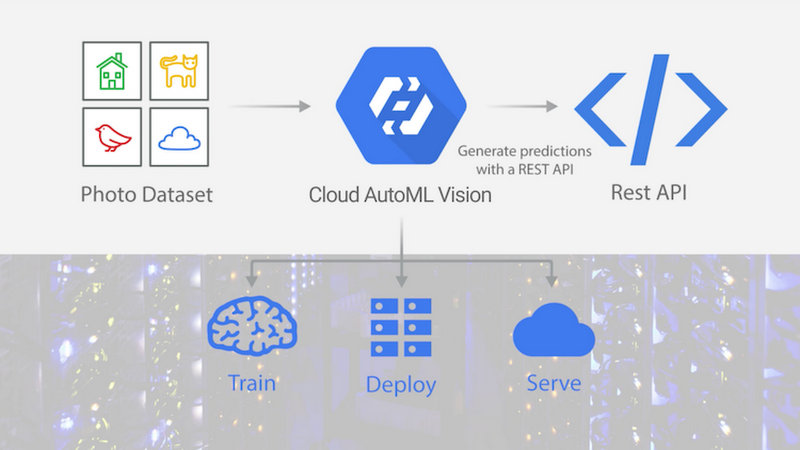
How AutoML Vision trains, deploys, and serves custom ML models
As soon as Kenji got access to the alpha version of AutoML Vision, he gave it a try. He found that when he trained a model with the ramen photos and shop labels, he got 94.5% accuracy (F1 score, with 94.8% precision and 94.5% recall) on predicting the shop just from the photos.
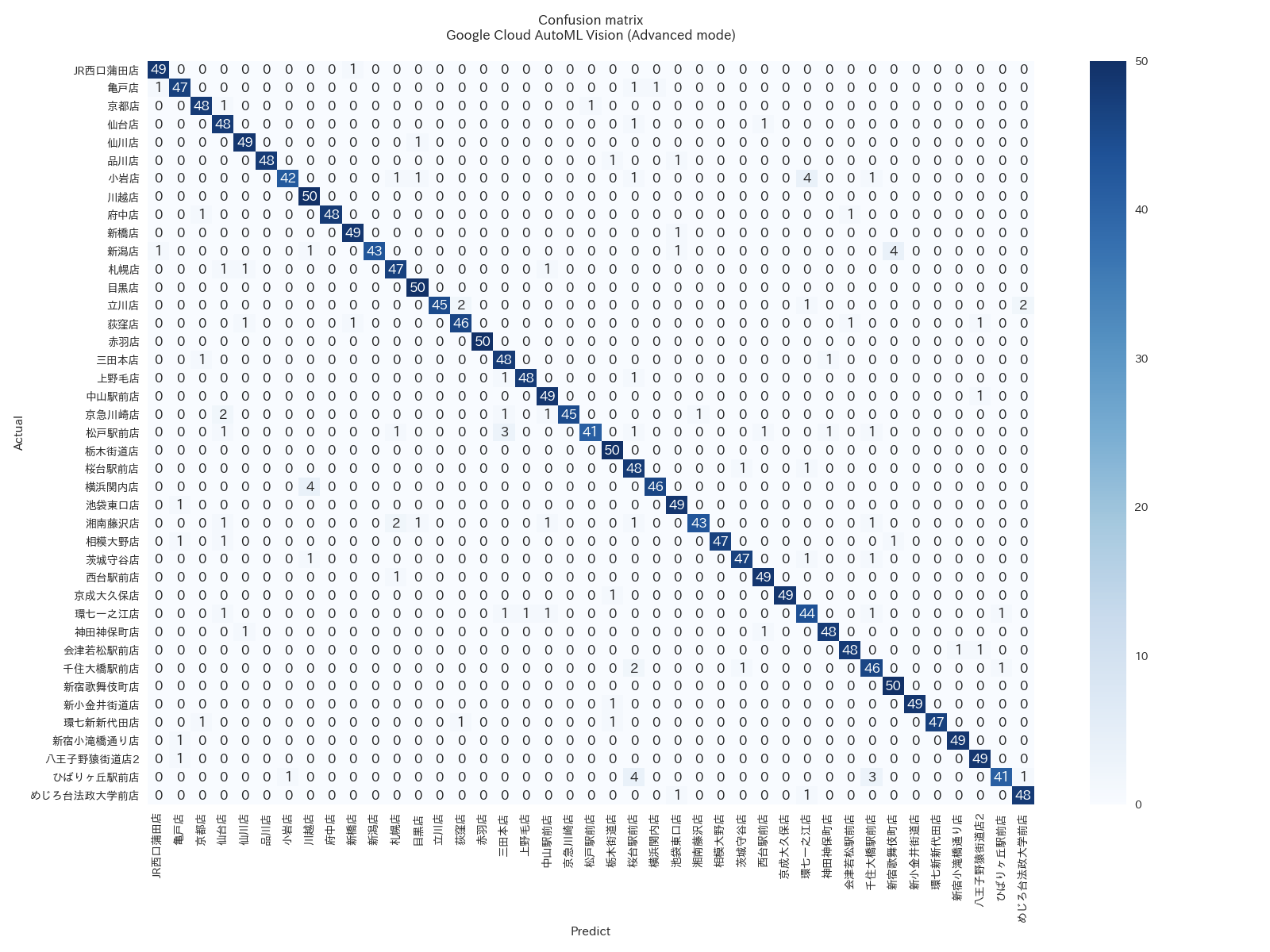
Row = actual shop, column = predicted shop
By looking at the confusion matrix above, you can see AutoML Vision incorrectly identified the restaurant location in only a couple of instances for each test case.
How is this possible? What are the differences in each photo AutoML is detecting? Kenji wondered how the ML model could identify the shop location with such a high degree of accuracy. At first he thought the model was looking at the color or shape of the bowl or table. But as you can see in the photos above, the model was highly accurate even when each shop used the same bowl and table design in their photos. Kenji’s new theory is that the model is accurate enough to distinguish very subtle differences between cuts of the meat, or the way toppings are served. He plans on continuing to experiment with AutoML to see if his theories are true.
Automating the craft of data science
Before he tried AutoML Vision, Kenji spent quite some time building his own ML model for his ramen classification project. He has carefully chosen a right model (it turned out to be an ensemble model of Inception, ResNet and SE-ResNeXt), built a data augmentation setup, and went through the time consuming hyperparameter tuning process (changing learning rate, etc.) using his best knowledge as a data scientist.But, with AutoML Vision, Kenji found the only thing he needed to do was upload the images and click the Train button. That's it. Through AutoML Vision, he was able to train an ML model without any undue excess effort.

An example of a labeled image set. With AutoML Vision, all you need to do is upload images with labels to get started.
When you begin training a model with AutoML Vision, you can choose one of two modes: Basic or Advanced. In Basic mode, it took AutoML Vision 18 minutes to finish the training with Kenji's training data. In Advanced mode, it took almost 24 hours. In both cases, he didn't perform any hyperparameter tuning, data augmentation or experimenting with different ML model types. Everything was automated and required no expertise as an experienced data scientist.
According to Kenji, "In Basic mode, you can't expect optimal accuracy, but you can get a rough result in a very short amount of time. In Advanced mode, you can get state-of-the-art level accuracy without any optimization or deep learning expertise. The tool would definitely increase the productivity of data scientists. Already, data scientists are getting so many AI inquiries from our customers and we have to try applying deep learning to PoCs as quickly as possible. With AutoML Vision, a data scientist wouldn’t need to spend a long time training and tuning a model to achieve the best results. This means businesses could scale their AI work even with a limited number of data scientists."
There's another feature of AutoML Vision he liked. "It's so cool that you can use the scalable online prediction with AutoML Vision right after training. Usually that's another time consuming task for data scientists, because we have to deploy the model to a production serving environment and then manage it."
Classifying branded goods with 90% accuracy
AutoML Vision also proved its ability in quite a different use case: classifying branded goods. Mercari, one of the most popular selling apps in Japan (and also gaining in popularity in the U.S.), has been trying out AutoML Vision for classifying images with its brand names.
In Japan, Mercari launched a new app, Mercari MAISONZ, for selling branded goods. For this app, Mercari has been developing their own ML model that suggests a brand name from 12 major brands in the photo uploading user interface. The model uses transfer learning with VGG16 on TensorFlow, with 75% accuracy.

The photo upload UI suggests brand names, as predicted by the ML model.
But when Mercari tried AutoML Vision in Advanced mode with 50,000 training images, it achieved 91.3% accuracy (precision score). That’s 15% more accurate than their existing model.
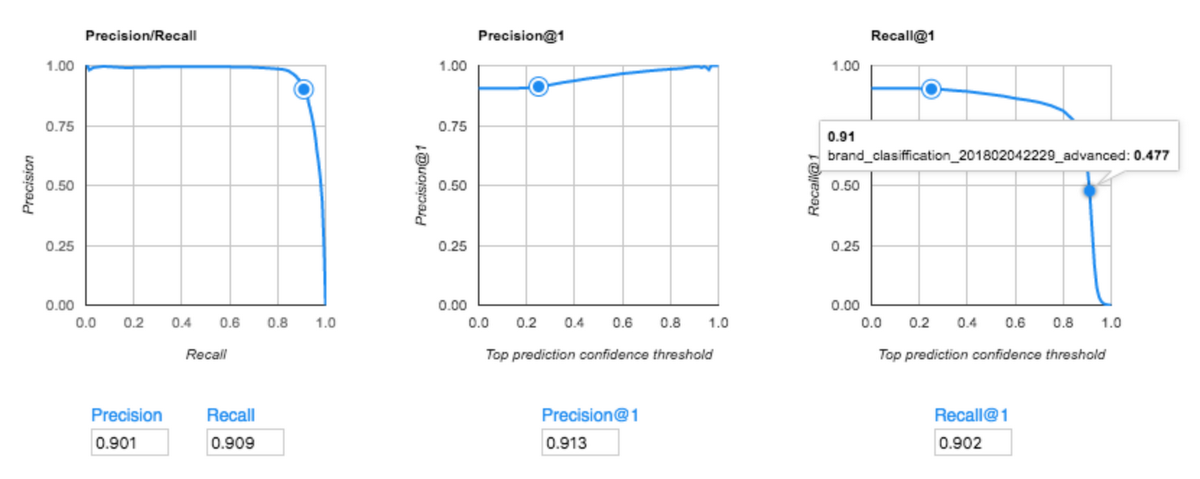
The accuracy score (precision/recall) of Mercari’s AutoML Vision model (Advanced mode)
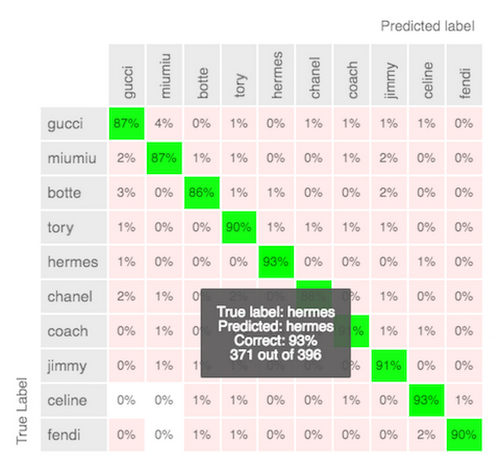
The confusion matrix of Mercari’s AutoML Vision model (Advanced mode)
A closer look at AutoML Vision
Shuhei Fujiwara, a data scientist at Mercari, was quite surprised with the result. "I can't imagine how Google achieves such high accuracy!"So, what's inside the Advanced mode? In addition to transfer learning, Advanced mode features Google's learning2learn technology, specifically NASNet.
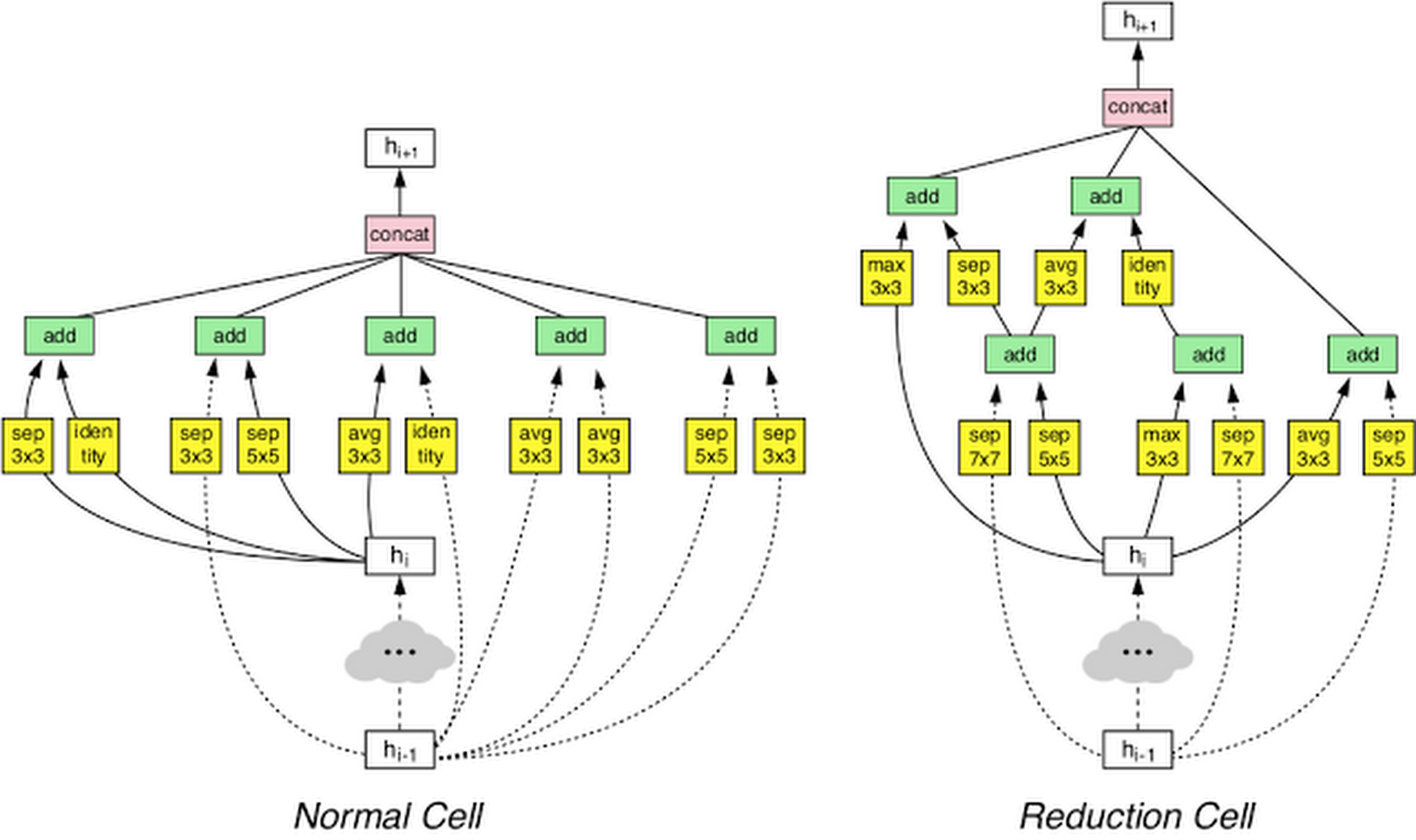
NASNet uses ML for optimizing ML: the meta-level ML model tries to find the best deep learning model design for a specific training dataset. This is the secret of Advanced mode, representing Google's "democratization of AI" philosophy. The technology lets users take advantage of state-of-the-art deep learning capabilities without spending a long time learning them.
Shuhei also likes the UI of the service. "It’s quite easy to use. You don't have to do anything about hyperparameter tuning, and also it's handy to have the confusion matrix on the UI so you can quickly check the accuracy. The service also allows you to delegate the human labeling work to Google, which can be the most time consuming part. So we're waiting for the launch of public beta for replacing the existing model with AutoML Vision and deploying to production."
One of the reasons Mercari has been growing so rapidly is the smooth user experience of their selling app. A significant increase in brand recognition accuracy in their UI could add more value once it's launched.



