The portability and familiarity of PostgreSQL with the scale and reliability of Spanner
Adam Seering
Software Engineer
Innovators in financial services, gaming, retail, and many other industries rely on Spanner to power demanding relational database workloads that need to scale without downtime. To meet developers where they are, Spanner provides a PostgreSQL interface that provides the familiarity and portability that development teams love, combining it with Spanner’s scalability and reliability. This allows them to use PostgreSQL queries, types, schemas, and clients to access Spanner’s unique consistency and availability at scale.
Let's take a look under the hood at how the PostgreSQL interface works and what that means for compatibility with PostgreSQL.
Parsing, optimizing, and execution
Most database engines, including Spanner, process queries in multiple stages. Those stages include:
- Parsing: The query string is processed and turned into a tree data structure that represents all of the table lookups, joins, expressions, and other operations that the query text asks for. It also looks up named tables, functions, etc., in the database catalog, resolving name collisions and rejecting queries that refer to tables, functions, etc that don't exist.
- Optimizing: The tree data structure is reordered and turned into an execution plan that fetches the requested data as efficiently as possible. This is sometimes referred to as query planning or compilation. We discuss Spanner's query optimizer here.
Execution: The compiled query plan is run. It fetches the requested data and returns it.
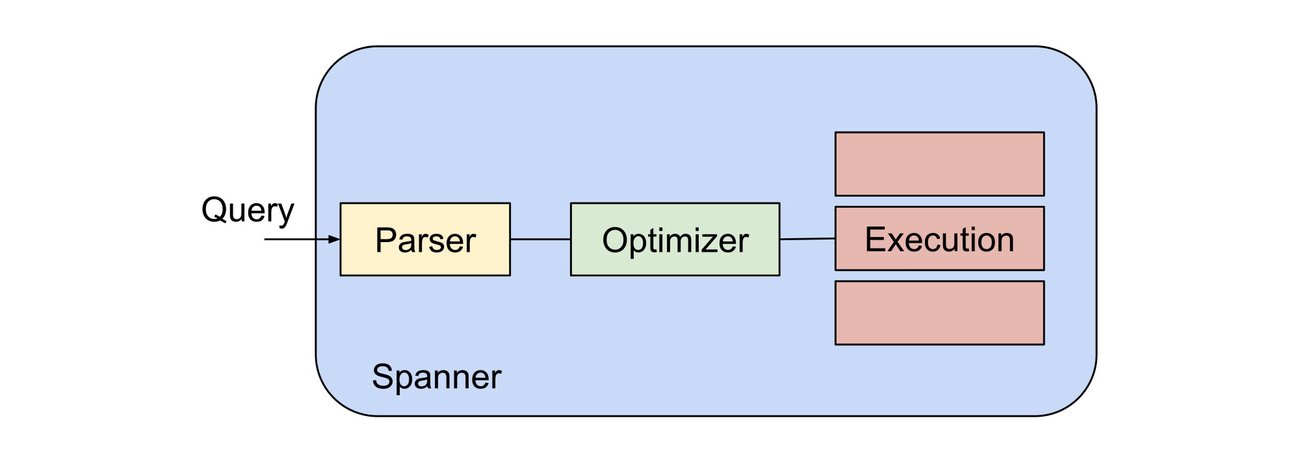
The above illustration is a logical conceptual representation of these three steps. Spanner distributes queries around the cluster to share the parsing and optimizing load, and distributes the execution of each query among multiple nodes as needed. Other databases share many of the same concepts, but may distribute the work differently (or not at all).
Spanner has historically supported the Google Standard SQL dialect (related to ZetaSQL). Google Standard SQL is a robust and standards-compliant SQL dialect that's used widely at Google, including for example by BigQuery, and supports a wide variety of SQL features.
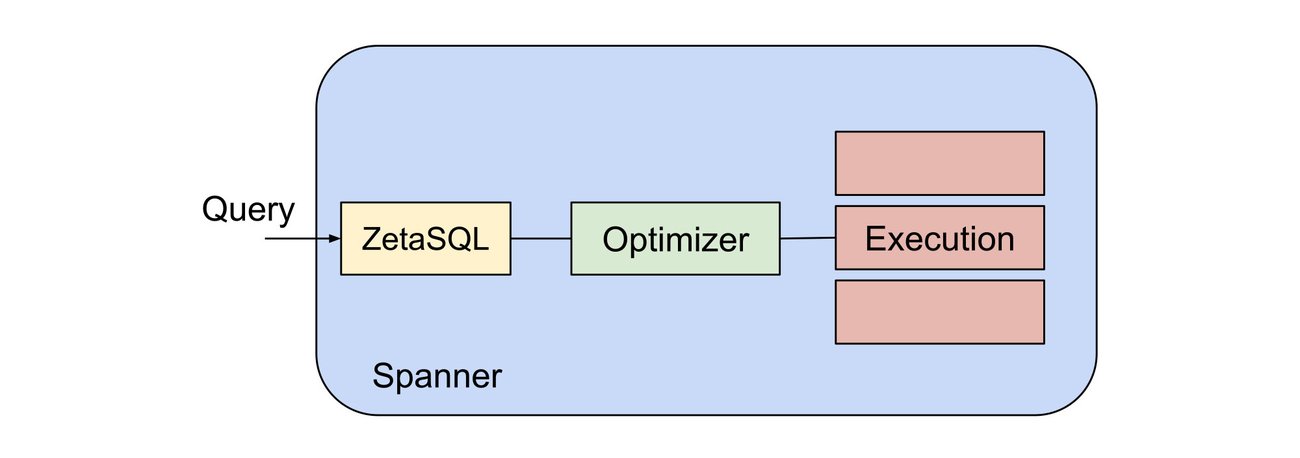
ZetaSQL focuses on compliance with the SQL standard. It’s a good option for users who want a consistent experience throughout their stack with both Spanner and BigQuery, with syntax that will be familiar coming from any database.
Other databases have taken different approaches. For example, consider PostgreSQL. The original Postgres engine was first developed in 1986, slightly predating the SQL standard itself. PostgreSQL has picked up a few quirks over the decades that make it unique and uniquely capable among other SQL implementations.
In order to enable customers who are familiar with the PostgreSQL dialect and ecosystem, Spanner has added support for PostgreSQL-syntax queries:
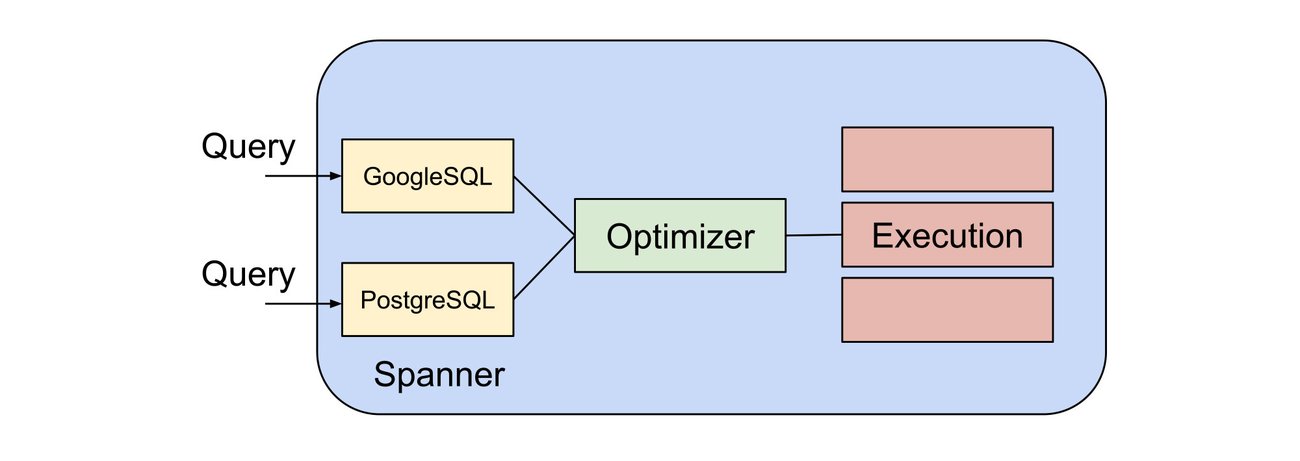
PostgreSQL-compatible queries are a "first-class" concept in Spanner, meaning that they are supported natively. They are parsed directly into data structures used by Spanner's optimizer just like their GoogleSQL counterparts. This gives the PostgreSQL dialect direct access to the full power of the underlying Spanner engine. PostgreSQL queries are not converted to GoogleSQL queries — a common misconception.
The optimizer then produces a query plan that is tailored to the specific data and infrastructure that is being used. This allows Spanner to generate query plans that are efficient and scalable, even for large and complex queries.
The PostgreSQL interface uses Spanner's optimizer, rather than PostgreSQL's, in order to produce scalable distributed query plans. This is because PostgreSQL's optimizer is tuned to produce plans that are optimized for a single server, whereas Spanner's optimizer can take advantage of Spanner's distributed architecture and scale to multiple servers, data centers, or even continents.
Catalog and system metadata
PostgreSQL's syntax is very convenient for writing queries. But syntax alone is just part of Spanner's PostgreSQL story.
Many existing PostgreSQL tools issue hidden metadata queries to introspect and understand the underlying database. For example, a tool might query tables in the SQL-standard "information_schema" schema to understand what tables and columns exist in your database. The tool might then query PostgreSQL-specific tables in the "pg_catalog" schema to figure out where and how those tables are stored on disk, what a column's default-value expression is and what raw PostgreSQL expression tree and core functions implement that expression, and other low-level PostgreSQL-specific internals.
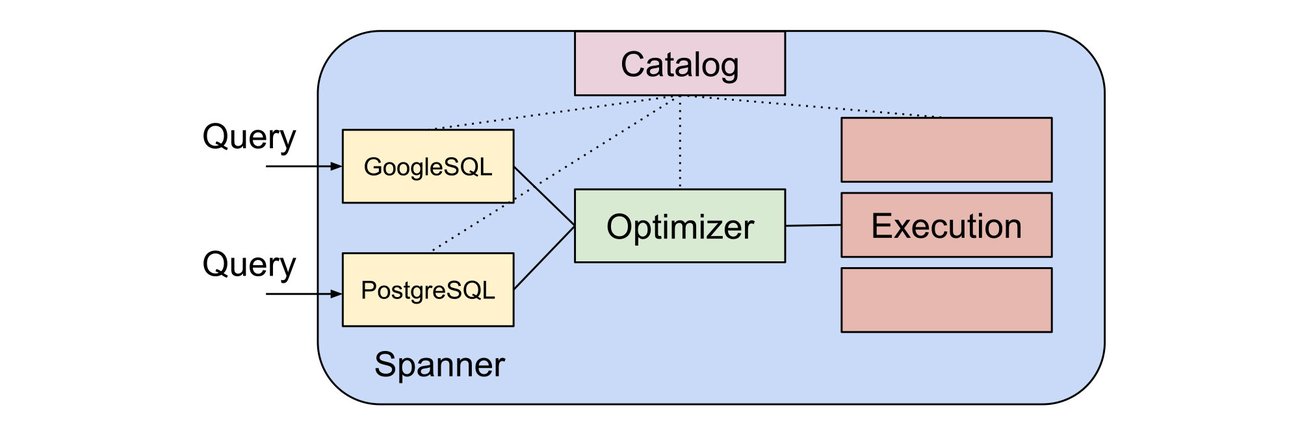
While information_schema is part of the SQL standard, PostgreSQL implements that standard slightly differently than Spanner did. When constructing a Spanner PostgreSQL database, we ensure that information_schema behaves as expected with PostgreSQL.
Spanner is developing support for the pg_catalog schema specifically for use with Spanner PostgreSQL databases. information_schema, as well as Spanner's own spanner_sys schema, continue to be available to both Google Standard SQL and PostgreSQL Spanner databases.
Engine support
PostgreSQL has been around for a long time. Its source code dates back to the Postgres project and the PostQUEL query language in the 1980s. Over the decades, it has accumulated many features. One key advantage of PostgreSQL's SQL dialect is that it enables expressing a wide variety of operations. In addition to making Spanner's engine available through the familiar PostgreSQL dialect, the Spanner PostgreSQL interface aims to extend Spanner to support a larger fraction of PostgreSQL's functionality.
Our initial focus was on common PostgreSQL data types. For example, we extended Spanner's NUMERIC(38) to support PostgreSQL-style arbitrary precision numeric values and implemented Postgres' canonicalizing JSONB type. Beyond data types, we also added support for null ordering (e.g., NULLS FIRST/LAST) in queries and indexes to align with expectations coming from PostgreSQL. Looking ahead, as Spanner adds new features we will take care to align their functionality to match Postgres; and as we plan which features to add to Spanner, we will take into account changes that would empower users coming from PostgreSQL.
PostgreSQL client, ecosystem support
Supporting PostgreSQL queries, schemas, and metadata are just part of the story. In addition to supporting PostgreSQL’s query syntax, another key piece is enabling PostgreSQL clients to connect directly to a Spanner database, in order to use existing tools with Spanner as if it were a PostgreSQL database.
PostgreSQL's wire protocol is optimized for clients running on the same machine, or at worst, the same rack, as the server. It makes several trade-offs that favor things such as client simplicity over efficient distributed performance:
- Multiple messages may be required to execute a single query, including fetching related metadata, etc. As connection latency increases, for example when connecting between two different data centers, this significantly increases query latency. This is not an issue when running on the same machine, but it becomes a problem when running in a separate data center or even continent.
- Clients only know how to connect to "the server." With sharded PostgreSQL, there's no native mechanism baked into the protocol to figure out on which server data is stored and to route queries accordingly.
- Sessions can't be resumed if the connection drops. Ongoing transactions must abort if a load-balancer timeout occurs, construction down the street actually breaks the connection to an on-premises data center, an endpoint server is overloaded and work needs to be redistributed, the client needs to restart to take a security update, etc.
Many PostgreSQL users resolve these issues using PostgreSQL proxy servers such as PGBouncer. These tools can substantially mitigate the above issues. But PostgreSQL's wire protocol predates the modern cloud and doesn't natively support concepts such as routing data from a single operation to multiple servers, transparently failing over in the case of a dropped connection, etc. Tools like PGBouncer don't fully solve these issues.
Our recommended solution is PGAdapter, a proxy that runs on client computers or in client networks. It enables running lightweight PostgreSQL clients within your server rack. As the name implies, it adapts, or translates, the PostgreSQL wire protocol into Spanner’s own gRPC-based protocol using Spanner’s globally available endpoint.
When connections need to be routed to a widely-distributed database, PGAdapter encapsulates the logic needed to make this work with reliable high performance. It handles the logic required to route a given request to the appropriate data center. It can also automatically batch simple operations to reduce round-trip latency. It can recover from disruptions that occasionally occur for queries that need to be routed over the public Internet. These are just a few of the concerns that PGAdapter handles.
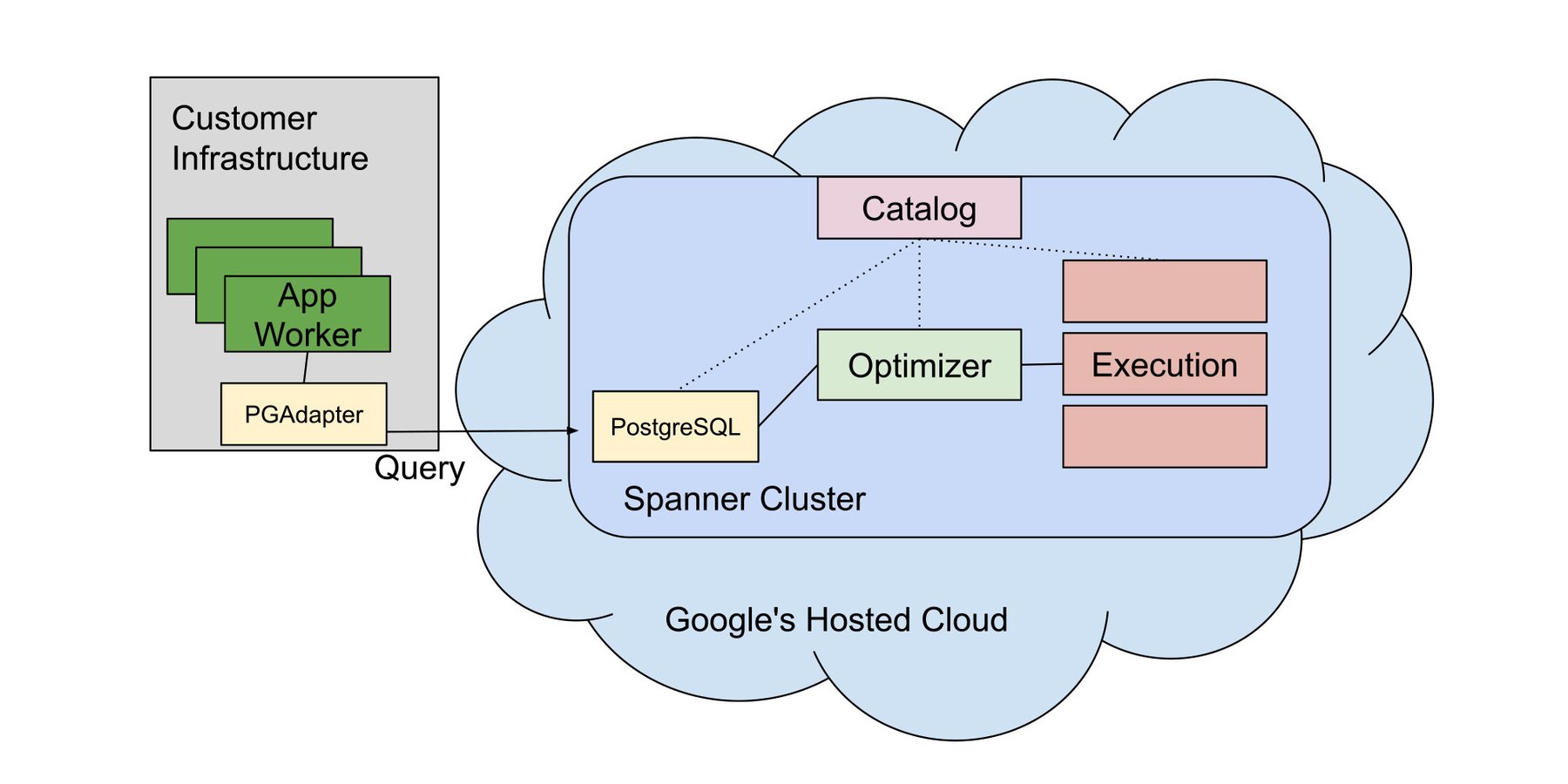
PGAdapter offers the best of both worlds: Native PostgreSQL applications can connect to Spanner without modification, and they use a protocol that is robust to the occasional churn and disruptions of modern Cloud and Internet environments.
Customers who prefer tighter integration with Spanner can use Spanner's native clients and drivers to connect to Spanner PostgreSQL databases instead. We specifically recommend this approach with JDBC: We fully support using PostgreSQL's JDBC driver via PGAdapter, but for JDBC in particular, many customers have reported that transitioning from PostgreSQL's JDBC driver + PGAdapter to Spanner's JDBC driver is a near-seamless experience and an operational simplification as it eliminates the the need for PGAdapter. You also have better access to Spanner features that may not exist in Postgres — and that are therefore not supported by the PostgreSQL driver. But we encourage users to find what works best for them, as there may be a feature that’s supported in one database but not the other.
In conclusion
Spanner's PostgreSQL interface offers a deeply integrated experience that enables customers coming from a PostgreSQL background to use familiar tools and their expertise to easily write globally distributed, highly available applications. Rather than trying to graft PostgreSQL support on top of the existing Spanner system, we’ve extended Spanner to support PostgreSQL-compatible query syntax and clients. This work is providing PostgreSQL-specific features and helping guide Spanner in its ongoing efforts to provide more and better functionality.
Please give the Spanner PostgreSQL interface a try today and let us know what you think. You can try Spanner for free for 90 days or for as low as $65 USD per month, and you can add Spanner PostgreSQL databases to any new or existing Spanner instances.


