Spanner under the hood: Understanding strict serializability and external consistency
Doug Judd
Spanner Software Engineer, Google Cloud
When it comes to database systems, an important consideration is the level of isolation and consistency they provide. Isolation level is the degree to which a database allows a transaction to execute as if there are no other concurrently running transactions. Consistency level is the degree to which every visible change of the database state upholds invariants and reflects causal dependencies. In this blog post I’m going to provide an explanation of two related terms that describe isolation and consistency level, Strict Serializability and External Consistency. Systems such as Spanner, that provide these guarantees, are said to have perfect isolation and consistency. I will describe the unique approach Spanner uses to provide these guarantees without sacrificing performance.
Transactions and Consistency
A transaction manipulates a database by a series of read/write operations that terminate with either a commit or a rollback (aka abort). When a transaction commits, its effects become durable (permanent), and when a transaction rolls back, it has no effect on the contents of the database.
One key requirement for transactions is consistency. This means that a transaction should modify the data in such a way that it maintains database invariants (e.g. index updates, constraints, cascades, etc) and application-level invariants (e.g. money isn’t lost when transferring from one account to another). It also means that causality is preserved (if transaction B is causally dependent on transaction A, then if the effects of B are seen, so should be seen the effects of A). The author of the transaction is responsible for the application-level invariants and the database system itself is responsible for the rest.
A well-formed transaction transforms the database from one consistent state to another. If a database starts in a consistent state, any serial execution of such transactions will transform the database into another consistent state. While the serial execution of transactions will maintain consistency, it can result in suboptimal performance. For example, there are situations where two transactions that operate on disjoint sets of data could be executed safely in parallel, which would increase transaction throughput. However, problems can arise if operations from concurrent transactions aren’t scheduled in the right order. For example, consider the following interleaved execution of two transactions, a and b, each transferring $100 from account1 to account2:
As can be seen from the above execution sequence, $200 is debited from account1, but only $100 is credited to account2.
Serializability
Serializability theory is a mathematical tool that allows us to prove whether or not a concurrent execution of transactions upholds the principles of isolation. There are situations where read/write operations from two concurrent transactions can be performed in any arbitrary order without impacting the outcome of the transactions. This gives the transaction scheduler some flexibility in how it schedules concurrent transactions. A concurrent execution of a set of transactions is considered to be serializable if it is equivalent to some serial execution of the same set of transactions. Assuming bug-free transactions, this guarantees that the database will be transformed from one consistent state to another (the example schedule in the previous section is not serializable). Serializability theory also introduces the following desirable characteristics of concurrent transaction scheduling which impose additional restrictions on the order in which transaction operations are scheduled:
Recoverable (RC). A concurrent execution of transactions is recoverable if whenever a transaction B reads x written by transaction A, A commits before B. Consider the case where B reads some value written by A and uses it to compute and write a new value. If B commits and the system crashes before A commits, then upon recovery, the value written by B will be recovered but the effects of A will disappear (because it didn’t commit), and therefore the recovered value written by B will be invalid.
Avoids Cascading Rollbacks (ACR). A concurrent execution of transactions avoids cascading rollbacks if whenever a transaction B reads x written by transaction A, A commits before B reads x. The reason is that if B reads x written by A and then A rolls back, the value of x read by B will be invalid and B will have to roll back as well.
Strict (ST). A concurrent execution of transactions is strict if whenever a transaction B reads or writes x written by transaction A, A commits or rolls back before B reads or writes x. This property provides the additional guarantee that if two transactions write to the same data item x, the resulting value of x will be the value written by the transaction that commits last.
Given a set of transactions, each of the above scheduler properties defines a subset of all possible transaction operation interleavings and are increasingly restrictive (i.e. ST ⊂ ACR ⊂ RC). Spanner transaction scheduling conforms to the highest level of isolation, strict serializability.
Note that Spanner uses a technique called Multiversion Concurrency Control (MVCC) to handle data updates. When a column value is updated, the previous value is not overwritten. Instead, a new timestamped version of the value will be added to the database. This allows you to access historical snapshots of the database by telling your read transaction to read at some timestamp in the past. To prevent older versions from accumulating and consuming too much storage, Spanner defines a version retention period (configurable up to 7 days). As versions become older than the retention period, they will be automatically removed from the database.
External Consistency
External consistency is a term somewhat synonymous with strict serializability that was introduced to describe a similar property as it relates to the more challenging case of a decentralized storage system. It introduces the notion of a global serial order of transactions that is defined by the real (wall clock) time order in which the transactions complete. To be externally consistent, a transaction must see the effects of all the transactions that complete before it and none of the effects of transactions that complete after it, in the global serial order. Spanner achieves external consistency by using transaction commit timestamps. All reads and writes in a transaction effectively happen at their commit timestamp which represents a real time moment during the execution of the transaction. A transaction will see the effects of all transactions that have an earlier commit timestamp and none of the effects of transactions that have a later commit timestamp. Putting it in more concrete terms, the external consistency guarantee offered by Spanner is as follows:
Given two transactions T1 and T2 (that both contain writes), If a transaction T2 calls Commit() after T1’s call to Commit() has returned, then, T2 commit timestamp > T1 commit timestamp.
While this consistency guarantee says nothing about the order of transactions that overlap in time, it is considered “perfect” for practical purposes. From the serializability theory perspective, externally consistent transactions are serializable and recoverable. However, the reverse is not necessarily true. For example, consider the following sequence of operations:
A write(x) → B write(x) → B commit → A commit
This sequence is both serializable (equivalent to A followed by B) and recoverable (no reads involved), however it’s not externally consistent since A writes x before B, but A commits after B. Externally consistent transactions are not required to uphold the “avoids cascading rollbacks” and “strict” properties. For example, consider the following sequence of operations:
A write(x) → B write(x) → A commit → B commit
This sequence is externally consistent (equivalent to A followed by B, and this coincides with the commit order) but not strict serializable because A wrote x but didn’t commit before B wrote x. Though the definition doesn’t include these additional properties, if a database system doesn’t allow reading or overwriting uncommitted data and provides external consistency, it will automatically guarantee strict serializability.
Achieving strict serializability and external consistency in a decentralized database system like Spanner is challenging. A Spanner instance can potentially run on thousands of machines. To achieve high transaction throughput, Spanner splits data into disjoint groups, each with its own transaction scheduler that generates timestamps from its own local clock.
Consider two transactions t1 and t2 that are causally dependent (t1 → t2). If they operate on overlapping sets of data, they will share at least one transaction scheduler in common. As long as the scheduler uses a technique that ensures strict serializability (e.g. two-phase locking), they will be assigned commit timestamps that reflect the causal relationship (t1 commit_ts < t2 commit_ts) and will guarantee consistency. Spanner’s transaction schedulers work this way.
Now consider the case where transactions t1 and t2 operate on disjoint sets of data. If t2 indirectly learns the outcome of t1 and uses that knowledge to formulate the values it writes, t2 will have a causal dependency on t1. However, because there is no overlap in the data they directly operate on, they may not share a common transaction scheduler. This is where the problem gets hard. Consider the scenario where machine A executes transaction t1 and then immediately afterwards machine B executes transaction t2. If the clock on machine B is slower than machine A, you can end up with the consistency problem illustrated in Figure 1.
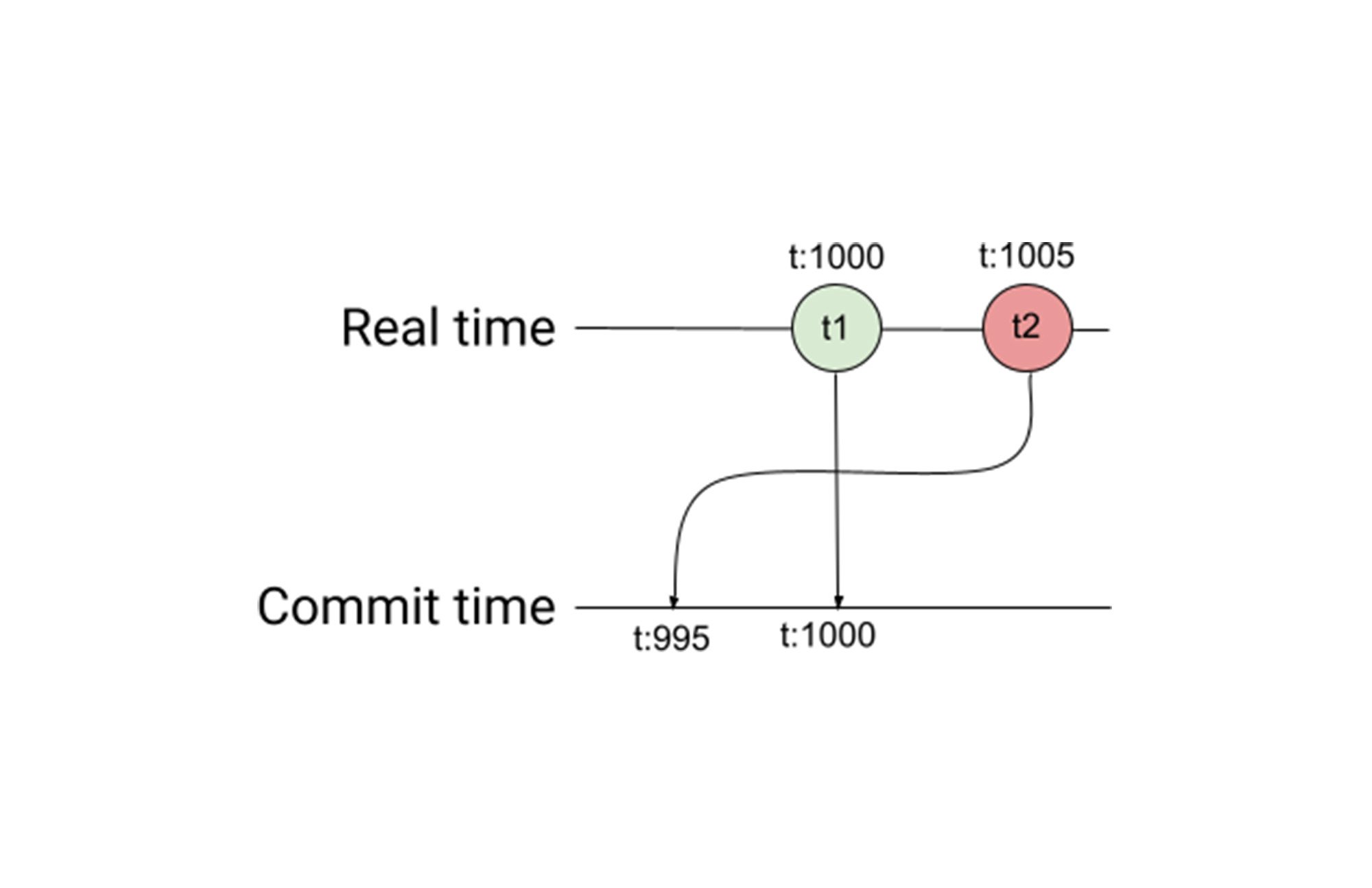
The commit time order of the transactions ends up being the reverse of the real time order. If you were to take a snapshot of the database at t1’s commit timestamp of t:1000, it would include transaction t2, even though t2 occurred after t1 in real time. If you were to take a snapshot of the database at t:995, it would include transaction t2, but not t1.
There are two components of Spanner that work together to provide strict serializability and external consistency without sacrificing performance, Paxos and TrueTime.
Paxos
Spanner provides high availability through synchronous replication using the Paxos consensus algorithm. In other words, every piece of data that is written into a Spanner database gets replicated in multiple (geo-distributed) locations. This allows data in Spanner to be available even in the face of some number of replica failures. Paxos handles writes by choosing a leader who sends out a write proposal to all of the replicas. Once a majority of replicas accept the proposal, the write is considered accepted and progress can continue. This helps maximize write throughput and allows writes to proceed even in the face of replica failures. As mentioned previously, data in a Spanner instance is split into multiple disjoint groups. We call these Paxos groups since they each have an independent Paxos protocol engine for replicating data within the group.
TrueTime
TrueTime is a clock synchronization system developed by Google. It provides a time API that exposes the notion of clock uncertainty. The method TT.now() returns a pair of timestamps [earliest, latest] and offers a guarantee that the absolute time (according to Google’s highly accurate time reference – more on this below) at which TT.now() was invoked falls somewhere in between the returned interval. This library is used by the backend Spanner servers to generate commit timestamps and reason about them (e.g. determine if a timestamp is definitively in the past).
A key component of TrueTime is the time server, which is a special machine that provides a highly accurate time reference. It accomplishes this through the use of an onboard GPS clock with a dedicated antenna or an atomic clock (each clock type has different failure modes). Every datacenter that runs the Spanner service runs multiple time servers. Running on each Spanner server machine is a time daemon that regularly communicates with the time servers to synchronize the machine’s local clock. As of this writing, TrueTime provides Spanner servers with less than 1 millisecond clock uncertainty in the 99th percentile.
Putting It All Together
I'll now describe how Spanner uses Paxos and TrueTime to provide externally consistent transactions for the case where you have causally dependent transactions that don’t directly reference the same set of data (and are scheduled by different transaction schedulers). When a Paxos group processes writes associated with a transaction, the Paxos leader performs the following steps:
Chooses a commit timestamp (
commit_ts := TT.now().latest)Sends Paxos write proposals and waits for quorum
Performs commit wait ( waits for
TT.now().earliest > commit_ts)Sends Paxos commit messages to replicas (writes are logged and applied)
Releases the locks
Notifies client
The crucial step to take note of here is step #3 (commit wait). This step guarantees that no client will see the effects of the transaction until its commit timestamp is in the past. This implies that if a write transaction t2 is dependent on the outcome of a write transaction t1 (causal relationship), then t2’s commit timestamp is guaranteed to be greater than t1’s commit timestamp. Also note that the commit timestamp is chosen in step #1 and the wait happens in step #3, so in effect, the wait happens in parallel with the sending of Paxos proposals and waiting for quorum. Thanks to TrueTime and its tight uncertainty window, the vast majority of the time, Spanner’s commit wait step involves no waiting. Things get a bit more complicated with transactions that span multiple Paxos groups, but the effect is the same.
This is how Spanner guarantees external consistency. Regardless of what timestamp a transaction uses to read the database, it will see a fully consistent version of the database as of that point in time. If there are multiple independent actors operating on the database, there is no need for coordination among the actors to ensure causally related events get properly ordered to ensure perfect consistency. Spanner’s use of two-phase locking and commit wait also allow it to guarantee perfect isolation, and with the power of TrueTime, there is virtually no scenario in which Spanner will take a performance hit due to the need to wait out clock uncertainty.
Conclusion
If you’ve made it to this point, I hope you have a better understanding of strict serializability and external consistency, two terms that describe Spanner’s isolation and consistency guarantees. Spanner powers some of the world’s largest applications including GMail and YouTube. It is also a good fit for applications that start small and experience rapid growth, as resource provisioning can scale to meet the application demands. If Spanner sounds interesting to you and you’d like to try it out, I encourage you to get started with our 90-day free trial.


