Understanding Cloud SQL maintenance: how do you manage it?
Akhil Jariwala
Product Manager, Cloud SQL
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialPicture this: you’ve just set up a mission-critical database on Cloud SQL and you’re excitedly preparing to turn on live traffic. As you go through your final launch checklist, you recall that Cloud SQL schedules routine maintenance. You pause to consider whether your system is set up properly to account for these maintenance updates.
In Part 2 of this blog series, I walked step-by-step through the Cloud SQL maintenance process and explained how we designed our maintenance workflow to keep maintenance downtime as brief as possible. In Part 3 of this series, I’ll explain the settings you have to manage when maintenance is scheduled and how you can design your system to minimize application impact due to maintenance.
What are the settings to manage maintenance?
Some mission-critical services are especially sensitive to disruption–especially during peak times–no matter how short the interruption. You can configure maintenance to be scheduled at times when brief downtime will cause the lowest impact to your applications. For each instance, you can configure a maintenance window, an order of update, and a deny maintenance period.
- A maintenance window is a day of the week and the hour in which Cloud SQL will schedule maintenance during a rollout. Note that while maintenance can be scheduled to occur any time during the one-hour window, the maintenance update itself usually lasts less than a minute.
- Order of update sets the order in which the Cloud SQL instance will get updated relative to other instances in the same region. Order of update can be set to Any, Earlier, or Later. Later instances are updated one week after Earlier instances in the same region.
- A deny maintenance period is a block of days in which Cloud SQL will not schedule maintenance. Deny maintenance periods can be up to 90 days long.
I find that the usefulness of these settings is best illustrated with an example. Say you are a developer at an ecommerce store called BuyLots. You have one Cloud SQL instance for your production environment and a second for your development environment. You want maintenance to occur at the hour of lowest traffic, which occurs at midnight on Sundays. You also want to skip maintenance during BuyLots’ busy end-of-year holiday shopping season.
On your production instance, you should set your instance’s maintenance window to Sundays between 12:00 AM and 1:00 AM ET, order of update to Later, and deny maintenance period to November 1 through January 15. See what this would look like on the maintenance card in the Instance Overview page in the Console in the example below:
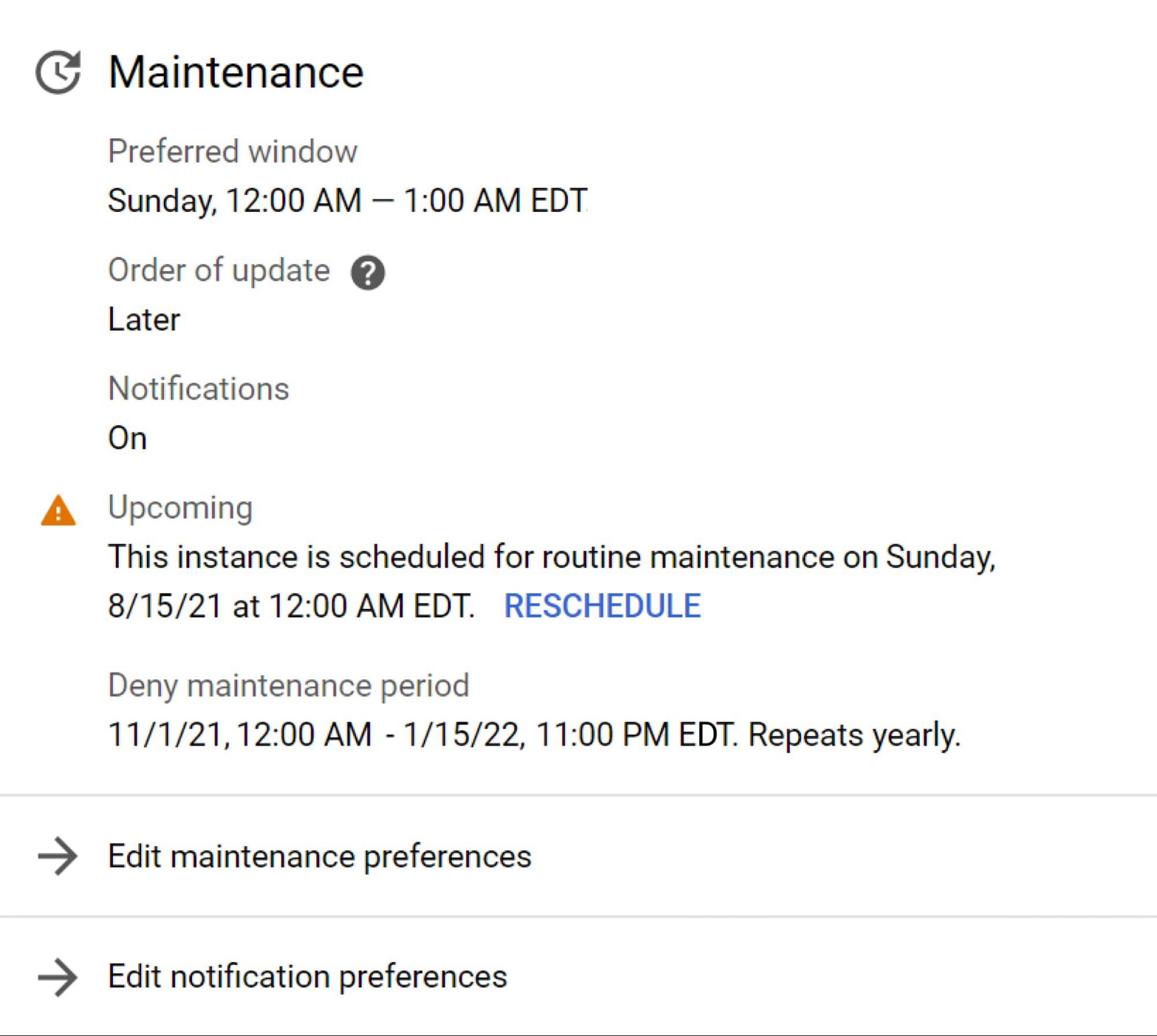
The maintenance settings for your development environment instance would be identical, except for the order of update, which would be set to Earlier. This ensures that you can run operational acceptance tests of new maintenance releases on your development instance for 7 days before maintenance rolls out to the production instance. In the event something goes awry on your development environment instance, you have time to diagnose and fix the issue so that your production environment is unaffected. If necessary, you also have time to contact Cloud SQL support to get help handling the matter.
How do maintenance notifications work?
If you’re developing mission-critical services, you may need to plan for service interruption in advance. Perhaps you need to prepare customer support or communicate the maintenance window to your end users. You can opt to receive upcoming maintenance email notifications from the Communication page under User Preferences in the Console.
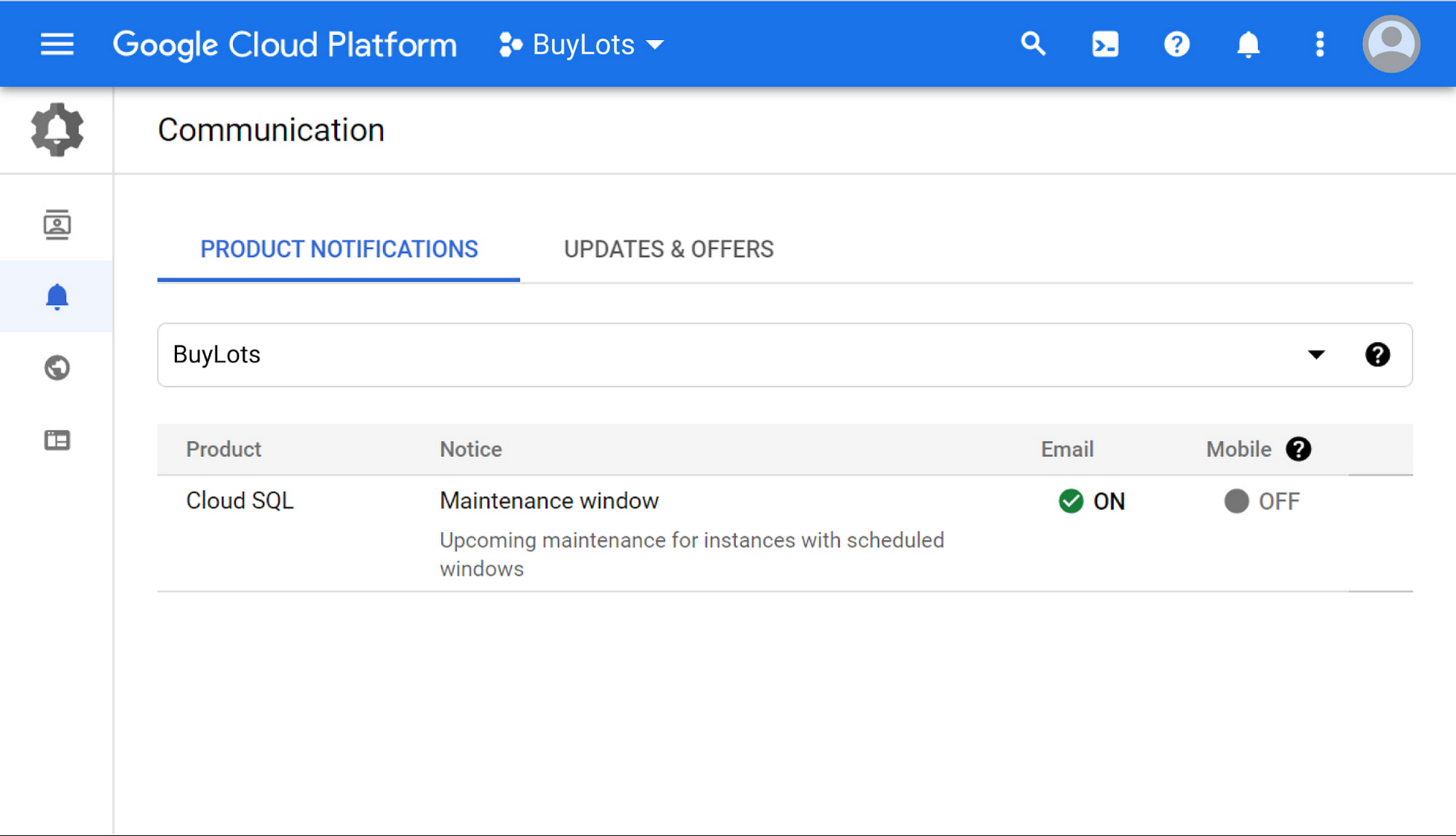
Upcoming maintenance email notifications are delivered to your Cloud Identity email address at least one week in advance of maintenance. These email addresses contain the name of the instance being maintained and the time of maintenance. Upcoming maintenance information is also posted in a banner at the top of the Instances List page and the instance’s Overview page in the Console.
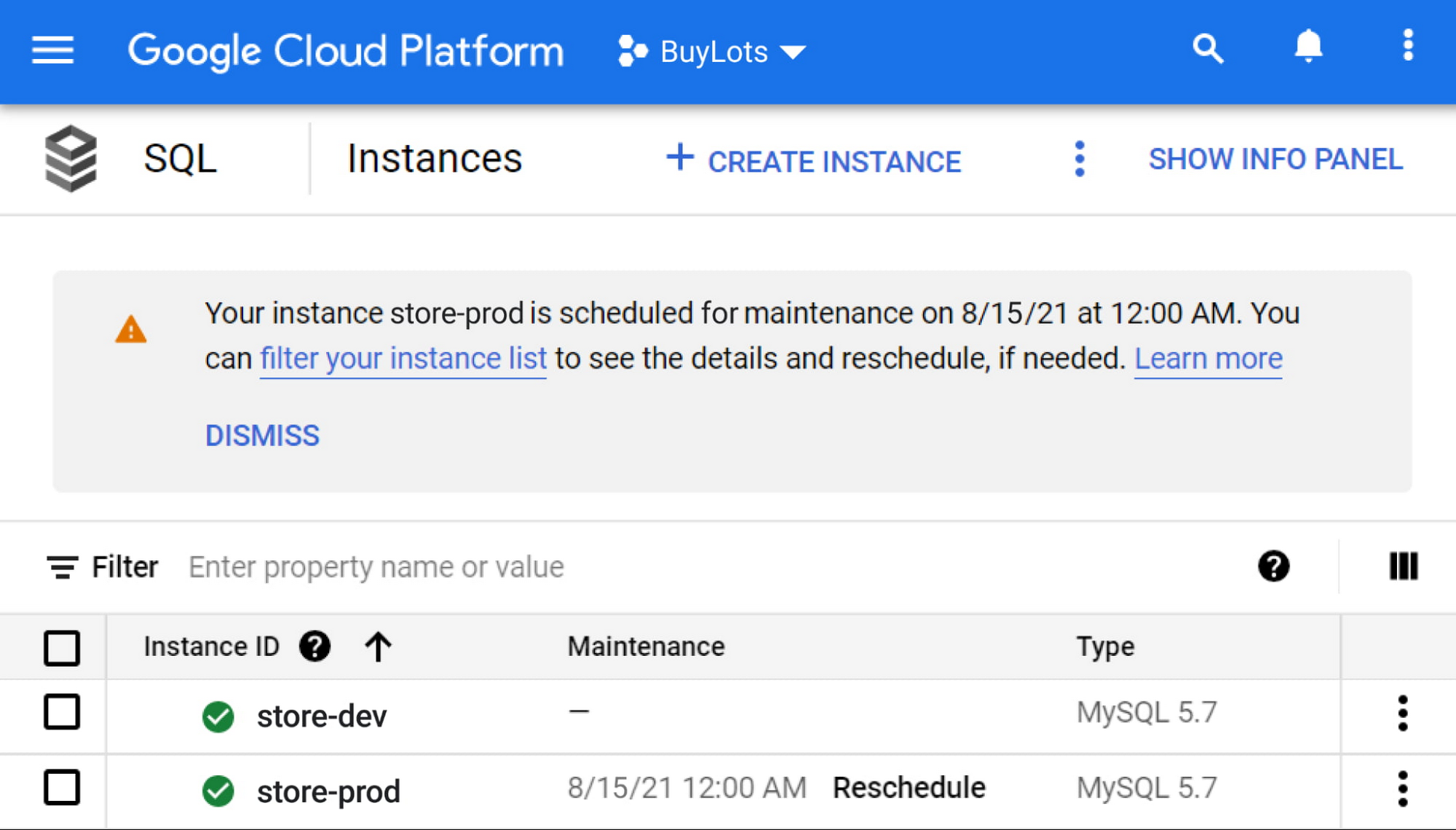
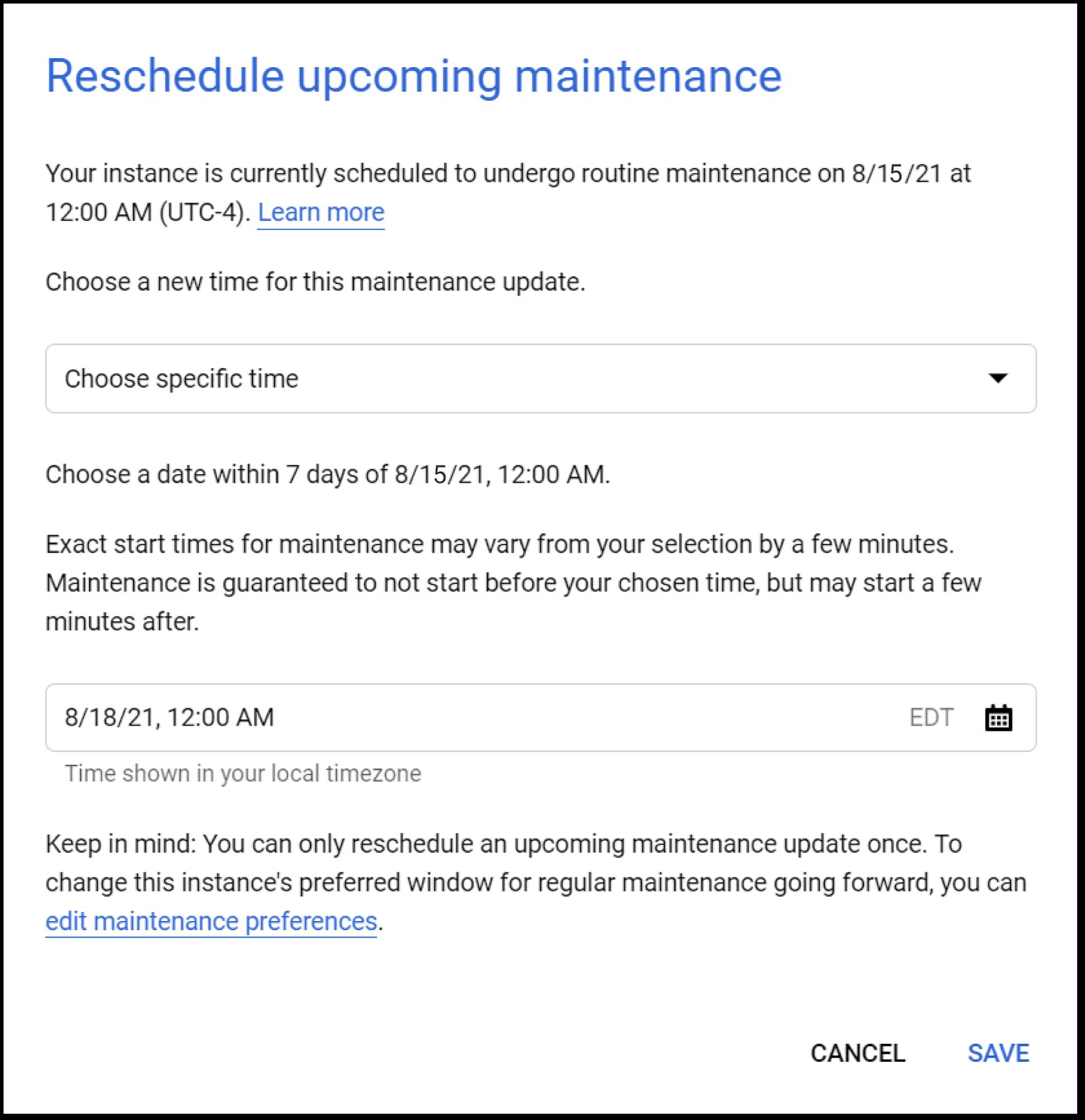
You may occasionally have a conflict with the original maintenance time, or need more time to test a maintenance update in your development environment. In these cases, you can reschedule maintenance to occur immediately, at the next maintenance window one week after the originally scheduled time, or at any point in between. In the Console, you reschedule from the Instances List page or from the instance’s Overview page.
How can an application be set up to minimize impact due to Cloud SQL maintenance?
In general, we recommend that when you’re running applications in the cloud, you build your systems to be resilient to transient errors, which are momentary inter-service communication issues caused by temporary unavailability. In Part 2, I highlighted some of the transient errors that occur during maintenance, such as dropped connections and failed in-flight transactions. As it turns out, users who have designed their systems and tuned their applications to be resilient to transient errors are also positioned to minimize impacts due to database maintenance.
To minimize the impact of dropped connections, you can institute a connection pooler like pgbouncer or ProxySQL in between your application and the database. While the connections between the pooler and the database will be dropped during maintenance, the connections between the application and the pooler are preserved. That way, the work of reestablishing the connections is transparent to the application, offloaded to the connection pooler instead.
To reduce the transaction failures, limit the number of long-running transactions. Use Query Insights to identify slow queries. Rewriting queries to be smaller and more efficient not only reduces maintenance downtime, but also improves database performance and reliability.
To recover efficiently from connection drops and transaction failures, you can build connection and query retry logic with exponential back-off into your applications and connection poolers. In the event that a query fails or a connection is dropped, the system institutes a wait period before retrying, the duration of which increases for each subsequent retry. For example, the system may wait just a few seconds for the first retry, but up to a minute for the fourth retry. Following this pattern ensures that these failures are corrected, without overloading your service.
There are many other creative solutions to minimize maintenance impacts as well, from using scripts to warm the database cache after maintenance to streamlining the number of tables in MySQL databases. We recommend following database management best practices to ensure that maintenance goes smoothly.
—
That’s a wrap for our Cloud SQL maintenance blog series! I hope you were able to learn more about what maintenance is, how we perform maintenance, and how to minimize maintenance impacts. If there’s something you didn’t see here, you’ll find the answer in our maintenance documentation. We are constantly investing in new improvements and settings for maintenance, so stay tuned to our release notes for the latest news. And if you’re new to Cloud SQL, get started with a new instance here.

