Cloud Spanner performance gains by using storing clause in indexes
Varun Gupta
Software Engineer
Overview
Spanner is a fully managed, distributed relational database that provides unlimited scale, global consistency, and up to five 9s availability. Cloud Spanner is used in financial services, gaming, retail, health care, and other industries to power mission-critical workloads that need to scale without downtime.
Spanner automatically creates an index for each table's primary key. You can also create secondary indexes for other columns. Adding a secondary index on a column makes it more efficient to look up data in that column because it avoids expensive scans over the entire table.
Spanner stores the following data in each secondary index:
All columns that are included in the index
All key columns from the indexed table, a.k.a., base table.
All columns specified in the optional STORING clause (Google Standard SQL-dialect databases) or INCLUDE clause (PostgreSQL-dialect databases) of the index definition.
Secondary indexes can help Spanner execute scans more efficiently, enabling index scans rather than full table scans.
Inside a read-write transaction, if a query performs a full table scan, it would lock all the ranges of data and therefore not allow any concurrent updates and inserts to the tables. Secondary indexes ensure lookups are performed on a small range of data which takes locks only on the matching range of data. This allows concurrent inserts and updates to the table for rows outside of the table’s lookup range. In this blog post, we will discuss the Storing Clause of secondary indexes that can be used to improve the efficiency of your queries by reducing the amount of data that needs to be scanned
Syntax for creating a secondary index
What is the STORING clause?
The storing clause specifies a list of columns included in the index as non-indexed columns.
This is an optional clause in the index definition. Spanner stores the columns mentioned in the storing clause in the index along with the indexed columns. A column in the STORING clause cannot be used in an index seek, and it is disregarded for purposes of any uniqueness or exclusion constraint enforced by the index.
Let’s say we have a Singers table with the following schema.
An example query could be:
The index singerFirstName will perform an index seek on the predicate Firstname=’Bruno’. To evaluate the query Spanner would need to perform a back join with the base table to get the value for column LastName.
For the index singerFirstNameStoringLastName which has a LastName in the storing clause, Spanner would perform an index scan on singerFirstNameStoringLastName and get the value of the LastName from the storing clause instead of doing a back join with the base table.
How is the STORING clause helpful?
Spanner stores the columns mentioned in the storing clause along with the index so that it can access those columns without having to refer back to the base table. SQL queries that use the index and select columns stored in the STORING or INCLUDE clause do not require an extra join to the base table. These indexes would perform an index only scan and are termed as covering indexes in relational database terminology. This can give significant performance gains for reads.
Example query:
The table definition for order_item is:
When we run the query we get the following query plan with the execution time of 99ms. The query plan looks like this:
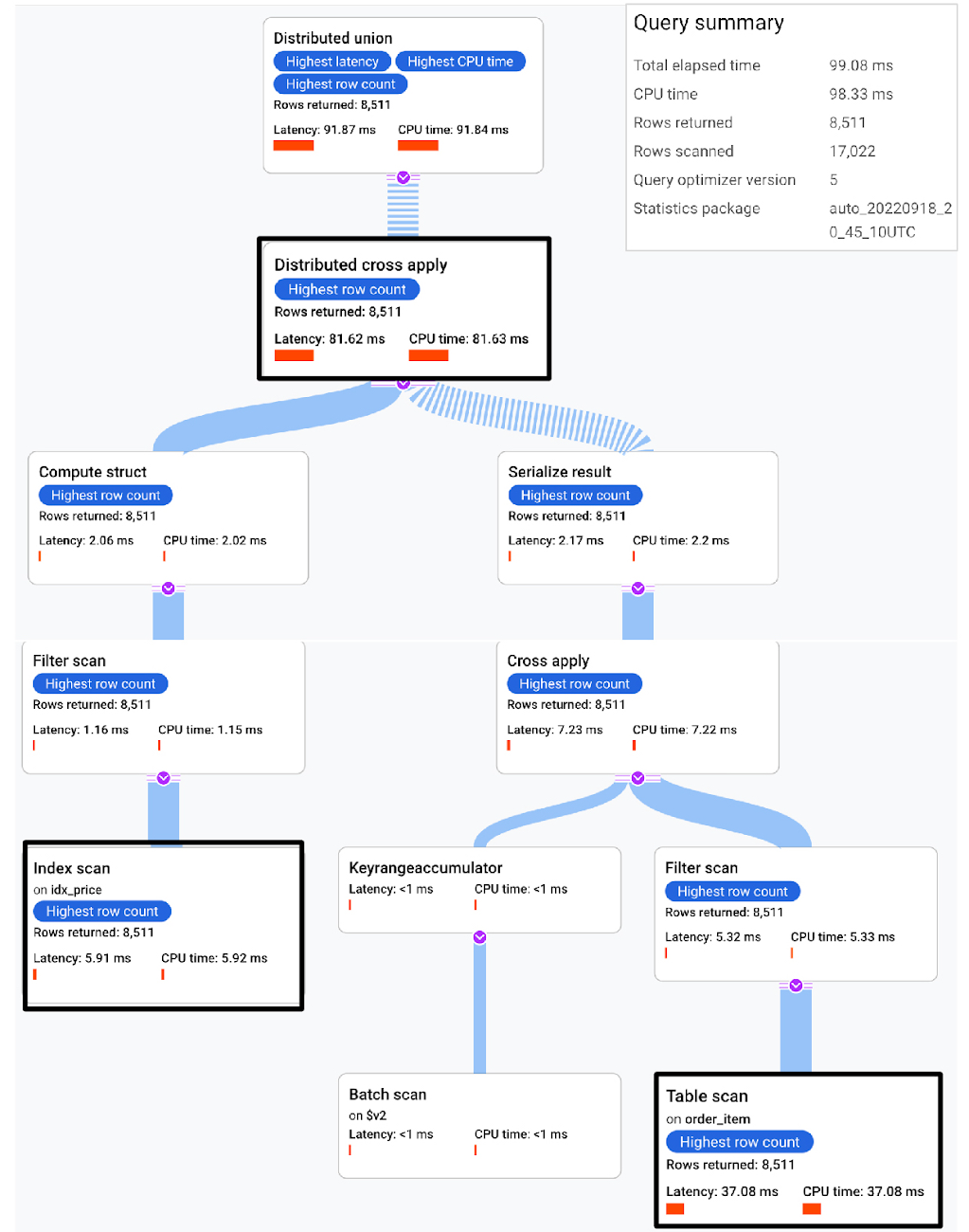
If we look at the details of the plan, we see that there is an index scan using the idx_price. From the idx_price, we are able to apply the filter price > 85000. After applying the filter, the index definition doesn’t contain order_item.quantity, so to fetch the value for this column, Spaner performs a join from the index back to the order_item table using the base table key. This is commonly referred to as a back join. As noted above, the base table key columns are always available in the index. The rows scanned for the query are 17,022.
Now let’s add another index to avoid the back join and just perform an index only scan using the STORING clause.
After running the query again with the new index, the execution time drops to 16.2 ms. The new query plan looks like
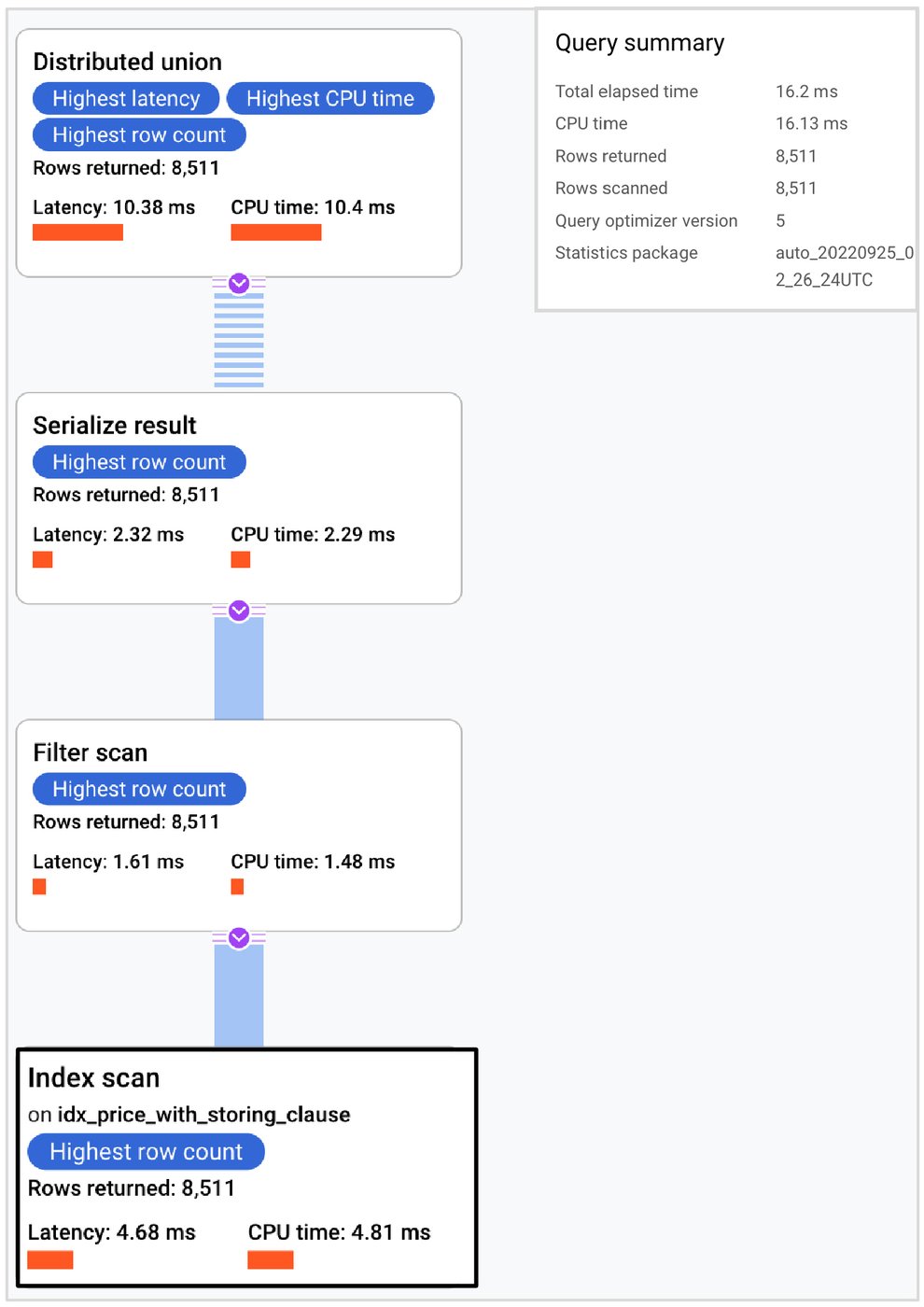
If we look at the details of the plan, we see that there is an index only scan using the idx_price_with_storing_clause. The rows scanned have dropped from 17,022 to 8,511. Here, we see that there is no back join with the order_item table. This query executes with an index only scan.
Comparison between the query plans when the query was using an index with and without the storing clause. The latency of the query with each plan might look something like, using the plan using index with storing clause as our baseline:
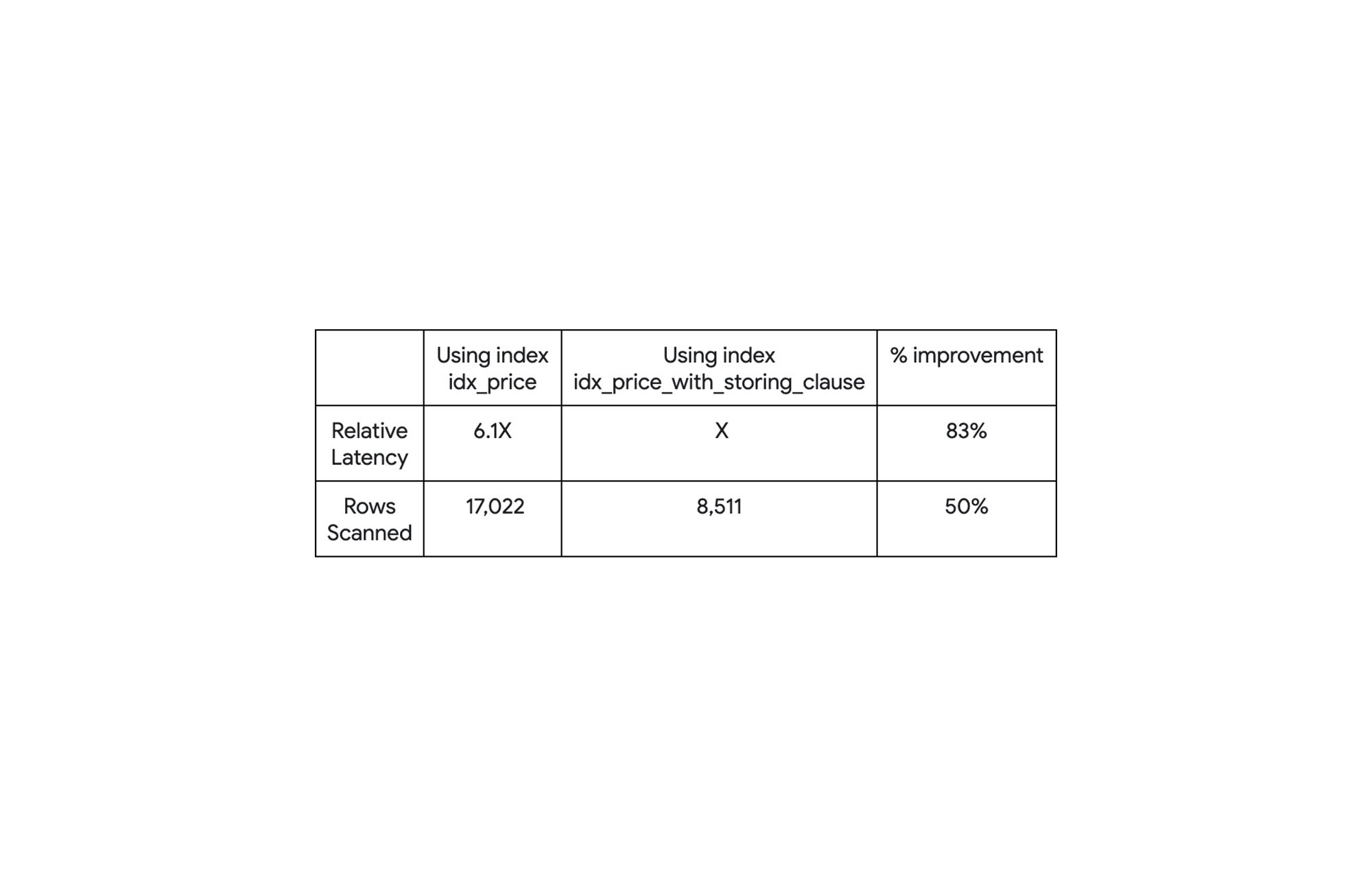
NOTE: the magnitude of the performance improvement depends on many factors, including schema, query, and data.
Limitations of the STORING Clause
The size of the index increases as extra columns need to be stored. This could lead to an increase in the storage cost of the database. Further the mutation count will increase with the STORING clause as we are writing to additional columns.
Write latencies will increase as during a write to an index the storing clause also needs to be written.
Summary
In this article, we reviewed the STORING clause and its benefits using an example. We have greatly improved latency and reduced the number rows scanned for the example query using the STORING clause. With the STORING clause, we could eliminate the back join by making the index a covering index. Thus, if the back join accounts for a significant portion of the latency of a query, consider using STORING clause to make the index a covering index. Learn more about secondary indexes or try out Spanner’s unmatched availability and consistency at any scale today for free for 90 days or as low as $65 USD per month.


