Migrating table schemas from Apache HBase to Cloud Bigtable
Jordan Hambleton
Cloud Data Engineer, Google Cloud
Shitanshu Verma
SWE, Google Cloud
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialMigrations of large workloads from Apache HBase to Cloud Bigtable are very common and we are trying to make them easier and faster. Cloud Bigtable is a natural fit for customers running their production workloads on HBase due to its scalability, low management overhead, high availability and HBase API compatibility.
Today, customers migrating to Cloud Bigtable have to manually create tables in Cloud Bigtable based on their HBase tables. This process can be tedious if the migration requires moving multiple tables or pre-splitting tables. To solve this problem, we are introducing the Cloud Bigtable Schema Translation Tool. It connects to HBase, copies the table schema and creates similar tables in Cloud Bigtable, in a fully automated way.
This blog post assumes the reader is familiar with HBase and Bigtable concepts.
The database schema
A Bigtable schema usually entails creating tables with column families, and setting garbage collection policies per column family. Defining a Cloud Bigtable schema is very similar to defining an HBase Schema.
Difference between HBase and Cloud Bigtable schema
Table Configuration: One of the main differences when creating tables between HBase and Bigtable is that HBase allows you to configure table and column family properties as part of your Data Definition Language (DDL) statements. These properties are server-side configurations that allow users to fine-tune the table’s performance with settings such as the max region size, compression, and encoding, to name a few.
In contrast, because Cloud Bigtable is a managed service, it optimizes these configuration parameters for you, leveraging what's been learned over 15 years of Bigtable production support for low-latency, high-throughput Google products such as Search, Ads, and Maps.
Namespaces: Besides these differences with being able to set server-side configurations, Namespaces is another major difference. HBase introduced the functionality of namespaces to provide the ability to create a higher level of scope for things like permissions, segregation of tables in the same cluster with the same name, and quotas.
Cloud Bigtable does not support namespaces. To control permissions you can use namespace prefixed tables (namespace-tablename) and use Cloud Bigtable table level IAM controls to control access. See section “Renaming tables and handling namespaces” below for how the schema translation tool can be configured to handle these scenarios.
Cloud Bigtable Schema Translation Tool
The CBT schema translation tool captures the schema from HBase and creates similar tables in Cloud Bigtable. The schema translation tool captures the following pieces of data from HBase to create the tables in Cloud Bigtable:
Table names
Column families
Name
Garbage collection policies
Table splits from HBase table
All the tables created from the schema translation tool are pre-split, meaning that they don’t need the warm up time during the import job to spread the load. The write load from import jobs is spread to multiple cloud bigtable nodes from the start. Over time, Cloud Bigtable will automatically optimize the splits according to the workload.
Installation/Download
To use the Schema Translation tool, download the latest jar with dependencies from the Maven repository. The file name is similar to bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar .
Ideally, the tool should be run from a machine that can connect to your HBase and Cloud Bigtable instance.
Usage
Schema translation tool works in 2 different modes:
1) Direct connection between HBase and Cloud Bigtable
This mode should be used when there is a machine that can connect with both HBase and Cloud Bigtable as illustrated in the diagram below. This machine, most likely an HBase edge/gateway node, is where the tool should be run. The tool will connect to HBase, capture the schema in memory and then create the tables in Cloud Bigtable.
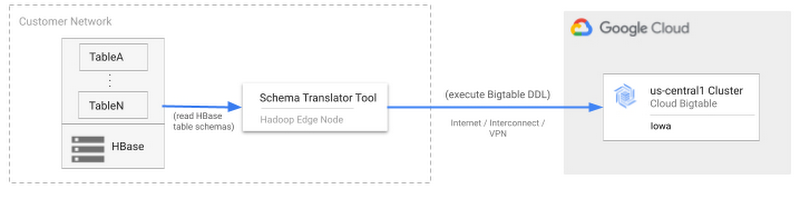
To run the tool in this mode, it needs information about the HBase cluster and Cloud Bigtable instance.
First, set the variables
Then run the tool
If you want to rename some tables the mapping file can be provided by adding -Dgoogle.bigtable.schema.mapping.filepath=/path/to/mapping/file.json.
More details about renaming tables can be found below.
2) HBase cluster lives on a private VPC
This mode should be used when your HBase cluster is in a private VPC and there is no host that can connect to both HBase and Cloud Bigtable. The schema translation process is a 3 step process illustrated in the diagram below.
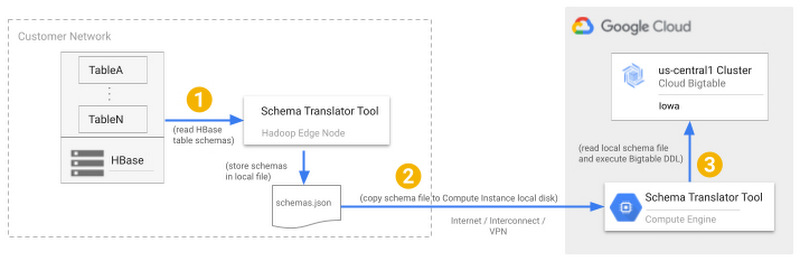
These steps are::
The schema translation tool is run on a machine on the HBase network. The HBase schema is stored in an intermediate schema file.
The schema file is copied to a machine with access to Cloud Bigtable.
The schema translation tool is run again on a host with access to Cloud Bigtable. The tool reads the schema from the intermediate schema file and creates the tables in Cloud Bigtable.
Please note that you will need to download the schema translation tool jar to the hosts used in step 1 & step 3 above.
Step 1. To copy the schema from HBase to a file:
First, set the variables
Then run the tool
Step 2. After capturing the schema in the file, you should copy the file over to a host that can connect to GCP.
Step 3. To create tables in Bigtable from the files, first set the environment variables
Then run the schema translation tool:
Note: If you want to change garbage collection policies between HBase and CBT, please be aware of the limitations on gc policy changes on a replicated table.
Renaming tables and handling namespaces
In certain situations the HBase table name may not be feasible on Cloud Bigtable. For example, if the table name is under a custom namespace (namespace:tablename). To handle such situations, the schema translation tool supports table name renaming. You can provide a JSON file containing a map of from → to mapping for a table name by setting command line parameter -Dgoogle.bigtable.schema.mapping.filepath=$SCHEMA_MAPPING_FILEPATH.
For example, a json file containing {“ns:hbase-tablename”: “cloud-bigtable-tablename”} tells the schema translator to rename HBase table hbase-tablename in namespace ns to `cloud-bigtable-tablename`. Once the tool is run you can run the Cloud Bigtable cbt list command to see a new table named `cloud-bigtable-tablename`.
Summary
Cloud Bigtable is a fully managed, API compatible alternative to Apache HBase. As users migrate from HBase to Cloud Bigtable, they need to execute several steps like exporting the data into GCS, creating the target tables in Cloud Bigtable, Importing the data into Cloud Bigtable and validating the data integrity. The Cloud Bigtable team provides tools to make the migration process seamless, including the recently released dataflow pipelines to import HBase snapshot into Cloud Bigtable and validate the data migration. This blog post introduces the HBase schema translation tool that allows you to create tables in Cloud Bigtable based on your existing HBase tables. These tables will act as the target for HBase to Cloud Bigtable data migration. Creating a target table is a required step before any data can be imported into Cloud Bigtable.
More information on Cloud Bigtable and the HBase API can be found here.

