Ready, set, launch! Cloud Spanner makes application launches easier with warmup and benchmarking tool.
Sneha Shah
Senior Software Engineer
Cloud Spanner is a fully managed relational database with unlimited scale, strong consistency, and up to five 9s of availability. To achieve the powers of consistency, scale and availability by default Cloud Spanner has a built-in mechanism to automatically shard your database and provide a transparent and seamless experience. Spanner is a distributed database and as your database grows, Spanner divides your data into shards called splits. Individual splits can move independently from each other and get assigned to different servers, which can be in different physical locations. For more information, see Database splits.
Spanner splits data based on load and size. That way, splits can be dynamically moved across Spanner nodes to balance the overall load on the database. The more data you insert into Spanner, the more splits are generated.
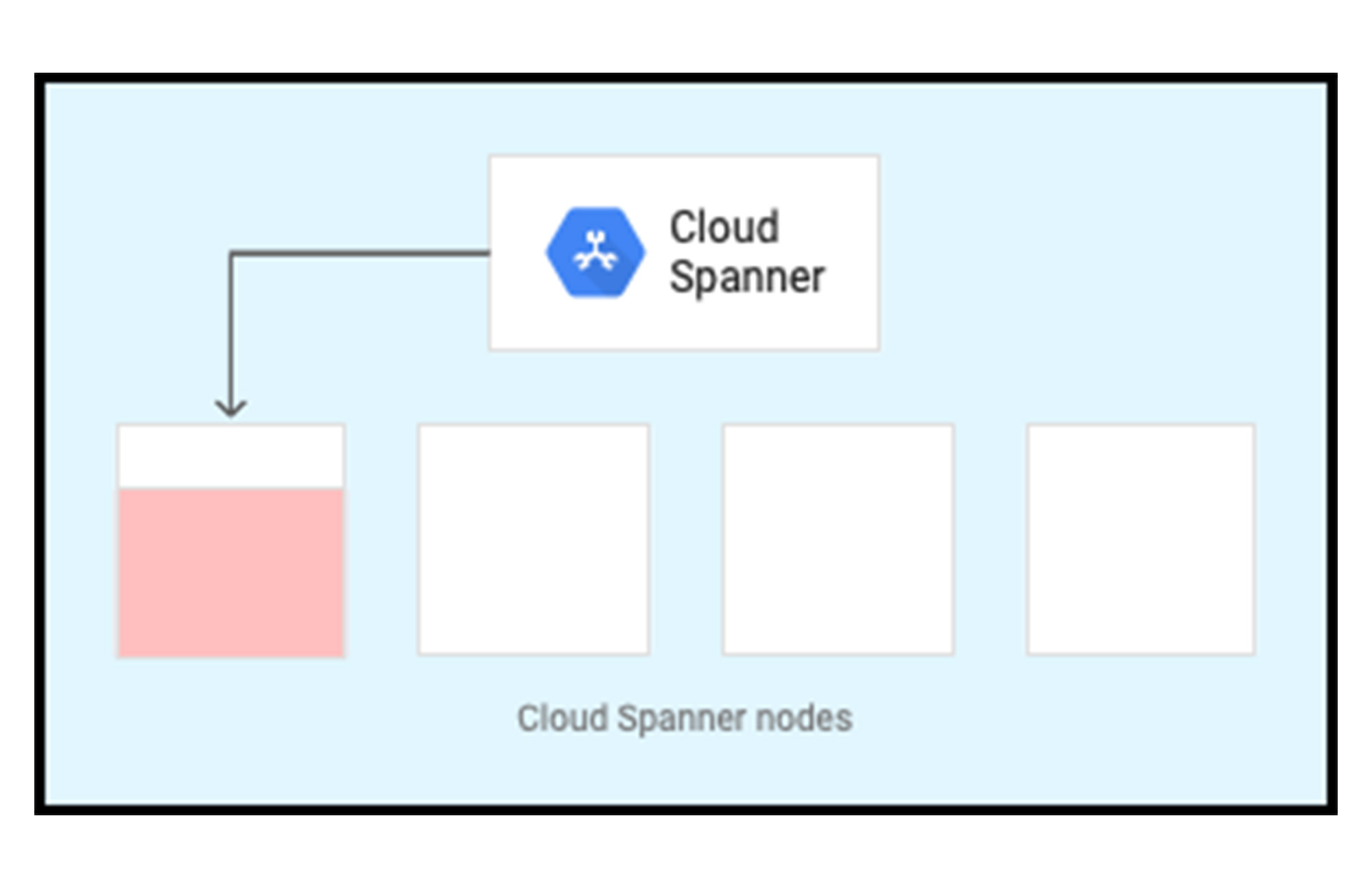
In the following diagram, there are four nodes (or 4,000 processing units) so four server resources are available in each zone within the instance configuration. Because you have no data in Spanner, when you start writing data you only write to a single server where the leader of a single split is assigned to. Spanner is currently in a cold state.
The following diagram illustrates the split to the other nodes. As the data comes into the system, Spanner starts to split that data to rebalance the load across server resources provisioned for four nodes. Now Spanner is in a warm state.
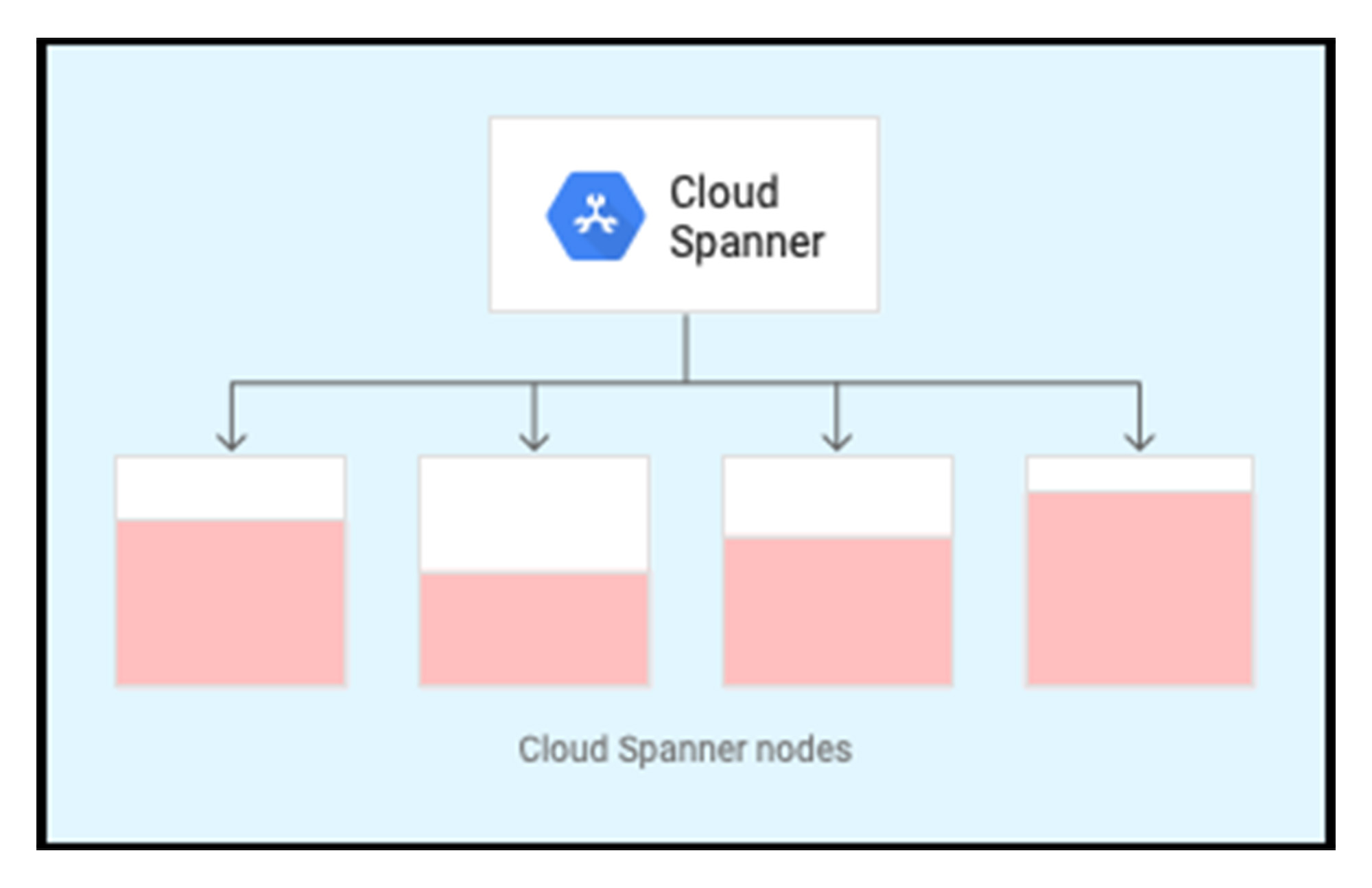
To achieve the best performance characteristics, it is advisable to launch your production application when Spanner is in a warm state with splits already balanced across all of the server resources.
Cloud Spanner Warmup
One of the ways you can pre-warm your database is by following these steps:
Create your Cloud Spanner instance and database with your production schema. It is advisable to include all indexes, to proportionally warm them up as well.
Generate load for the critical tables, those that are expected to get heavy traffic and/or are critical to the latency of your production application.
Ensure that the table primary keys you generate for your load are in the same keyspace (have the same statistical properties) as the keys used for production traffic.
Execute the load two days before your application launch. Also, it’s recommended to execute the load for an hour, at or near the expected peak load. The load causes Spanner to create more splits due to load-based splitting.
After the warmup is complete, it is recommended to delete the rows using Partitioned DML so that the splits remain available for the application launch. It is not recommended to drop the table or indexes.
Generate Load
To create load, you can use the following tool to generate random and synthetic data for a single table. The tool infers the table schema to generate data. The customers can tune the tool to mimic their data size, column size, key ranges and read/write distribution, thereby providing them the expected performance numbers at launch. Also to generate appropriate sized load (in the range of expected production traffic), it is recommended to execute the tool from a GKE cluster.
To reduce network latency, it’s best to place the GKE cluster close to the Spanner Instance (preferably in the same region as your regional instance or the default leader region of your muti-regional instance).
Cloud Spanner Setup
GKE Setup
Executing the Tool
To create an appropriate load on the Cloud Spanner database, edit the gke_load.yaml file to update the number of threads, operations and pods on the GKE cluster and supply the Spanner resources information.
Monitoring
Monitor the throughput and latency graphs on the Cloud console. The tool will eventually be able to generate higher throughput as more splits are created and able to reach & sustain the expected production peak traffic.
It usually takes about the first ~30 minutes to get stable p99 latencies, and almost an hour to get stable p99.9 latency. The throughput should get near expected throughput in the first ~30 minutes.
Best Practices
Splits are created based on usage and schema of the database, and reusing an existing database may provide different characteristics than a new database.
Reusing the database by only dropping the table may preserve unrelated splits and cause unexpected behavior.
Reusing an existing table for warmup should track the random data being written to the database by the tool. One suggested way is to create a nullable commit_timestamp column, that will be auto-filled by gcsb. These rows can subsequently be deleted after warmup and the commit_timestamp column can be dropped after warm up too.
Create the database with the complete production schema, including Indices.
Caveat: The tool currently doesn’t support the following features.
The warmup tool provides the ability to tune the data such that they are representative of the production workload:
All primary keys must be in the same keyspace as in the production database to create appropriate splits.
Column data can also be configured for size to maintain overall row length equal to the production load
It is recommended that all your Secondary Index (including Interleaved Index) are created before starting the warmup. Indexes will also automatically split based on the data load. It is important to load index primary keys in the same keyspace as the production workload to get the appropriate splits.
For interleaved tables, warmup process may differ based on the usage of your child tables:
If your child table is expected to have many rows (1000+) under a single parent row, then it is advisable to add rows (approximately in the same order of magnitude as it would be in production) within the child table during the warmup process.
Though if you only have a few rows under each parent row, then warming up the parent table is sufficient.
The warmup process may take several minutes, even up to an hour to stabilize your system. It is recommended to at least run the warmup process for an hour. For a Spanner instance with up to 50 nodes, it may take about an hour to warm up and perform at stable QPS and latencies. For instances larger than that, add about 5-10 mins for instances with double the size. Example: 50 node instances take up to 60 mins, 100 nodes may take 70 mins, 1000 nodes will be about 100 mins.
It is also recommended to tune the warmup tool configuration to execute within the recommended CPU threshold.
Make sure to track and delete the synthetic data created by the tool before your production application is launched. Data can be deleted using the Partitioned DML.
It is a prerequisite to tune the threads and GKE pods to create peak traffic. Scale the throughput by adding more GKE pods, rather than scaling the number of threads within each run to avoid CPU contention on each pod.
Verification
To ensure that your Cloud Spanner database would achieve the expected throughput of your production application, you should execute a read/write workload after the warmup. This workload will continue to create further splits, if needed. More importantly, it will provide insight into latency and throughput for the application launch.
This step can also be used to pre-warm an existing database or table. Customers can specify the specific key ranges for the tables (config) that should be split before the launch.
To generate read/write traffic, edit the gke_run.yaml file, supplying the Spanner resource information, and the expected read and write traffic. The configuration also allows you to configure strong/snapshot reads to mimic the production workload closely.
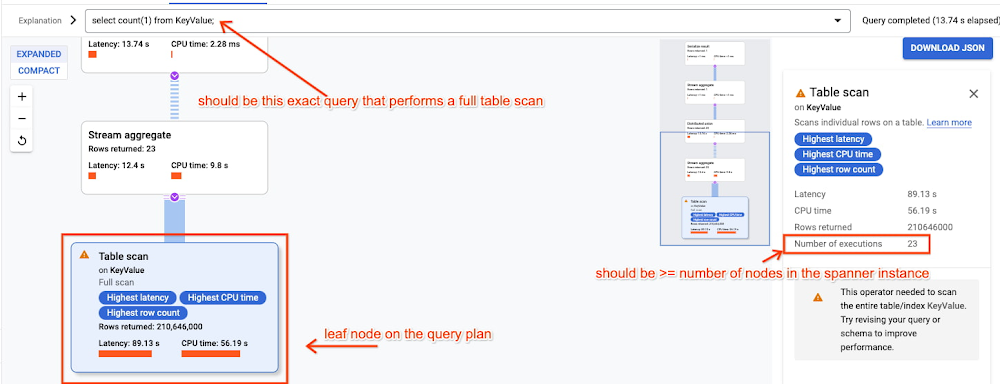
Also, as an additional correlated metric to verify: the full table scan query should at least have as many executions as the number of nodes within your Spanner Instance. To find the query executions, execute the following in the Cloud Console and examine the plan:
Optionally, you can use Cloud Spanner Key Visualizer to view the key distribution in the generated read/write traffic. If you have configured specific key ranges to warm up, you should be seeing consistent higher numbers of reads or writes in those key ranges showing up as bright bands in the Key Visualizer. If you have configured write workload to an indexed column, you should also see write activities in the indexes.
Conclusion
Spanner is a distributed, globally scalable SQL database service that decouples compute from storage, which makes it possible to scale processing resources separately from storage. This distributed scaling nature of Spanner’s architecture makes it an ideal solution for unpredictable workloads such as online games. Learn how to get started developing global multiplayer games using Spanner, in this whitepaper.



