Bringing Hibernate ORM to Cloud Spanner for database adoption
Mike Eltsufin
Software Engineer
When you’re adopting a new database technology, some things to consider can include learning a new SQL dialect or writing new boilerplate persistence logic. As much as possible, we’d like to make this simpler. For this type of work, Hibernate has become the de facto standard object relational mapping (ORM) solution for Java projects. It supports all major relational databases and enables even more powerful ORM tools like Spring Data JPA.
We’ve developed our new open source Cloud Spanner Dialect for Hibernate ORM to make it easier to adopt Cloud Spanner. You can now get the benefits of Cloud Spanner—scalability and relational semantics—with the idiomatic persistence afforded by Hibernate. This can help you migrate existing applications to the cloud or write new ones using the familiar APIs of Hibernate-compatible environments such as JPA, Spring Data JPA, Microprofile, and Quarkus.
Hibernate ORM helps address the challenges of adopting a new database technology by providing two major benefits: portability across databases and easier writing of create-read-update-delete (CRUD) logic. These benefits can increase developer productivity and speed up cloud database adoption.
For more information, check out our documentation, the git repository, or try out the codelab.
How to write a Java app with Hibernate and Cloud Spanner
Here, we’ll take you on a quick tour of what it’s like to write a Java application that uses Hibernate to talk to Cloud Spanner. The steps are similar to what you’ll find in the codelab. We’ll create an application that stores musical artists and their albums in Cloud Spanner. Although this is a basic Hibernate example, keep in mind that this can be adapted to JPA-based systems backed by Hibernate as well.
We’ll need the Cloud Spanner Dialect for Hibernate, the open source Cloud Spanner JDBC driver, and the Hibernate core. So, let’s add those dependencies to the app.
pom.xml
Now, let’s tell Hibernate about the annotated entity classes we’ll be mapping to the database.
src/main/resources/hibernate.cfg.xml
Hibernate also needs to know how to connect to the Cloud Spanner instance and which dialect to use. So, we’ll tell it to use the SpannerDialect for SQL syntax, the Cloud Spanner JDBC driver, and the JDBC connection string with the database coordinates.
src/main/resources/hibernate.properties
We’ll make sure that the authentication credentials are already set up, using either a service account JSON file in the GOOGLE_APPLICATION_CREDENTIALS environment variable or the application default credentials configured using the “gcloud auth application-default login” command.
Now we’re ready to write some code.
We’ll define two plain old Java objects (POJOs) that will map to tables in Cloud Spanner—Singer and Album. The Album will have a @ManyToOne relationship with Singer. We could have also mapped Singers to a list of their Albums with a @OneToMany annotation, but for this example, we don’t really want to load all albums every time we need to fetch a singer from the database.
Since we don’t have an existing database schema, we added the hibernate.hbm2ddl.auto=update property to let Hibernate create the two tables in Cloud Spanner when we run the app for the first time.
src/main/java/demo/Application.java
Don’t forget to also add a no-arg constructor, hashCode(), and equals(), to each of the entities, as Hibernate requires these. You can see all that in the full example.
Also, for this example we’re using an auto-generated UUID for the primary key. This is a preferred ID type in Cloud Spanner because it avoids hotspots as the system divides data among servers by key ranges. A monotonically increasing integer key would also work, but can perform less well.
With everything configured and entity objects defined, we can start writing to the database.
Create a Hibernate Session.
src/main/java/demo/Application.java
It’s time to write some data into Cloud Spanner.
src/main/java/demo/Application.java
At this point, if you go to the Cloud Spanner console and view the data for the Singer and Album tables in the database, you’ll see something like this:
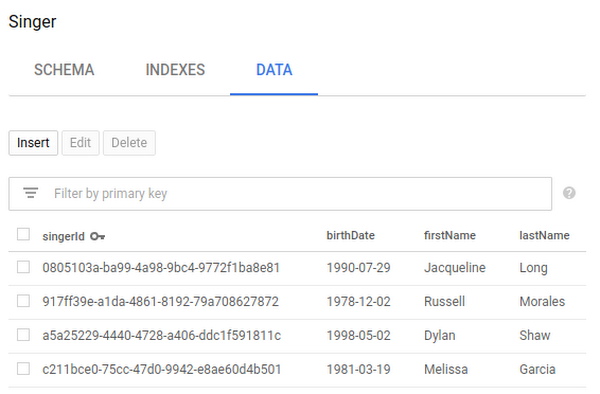
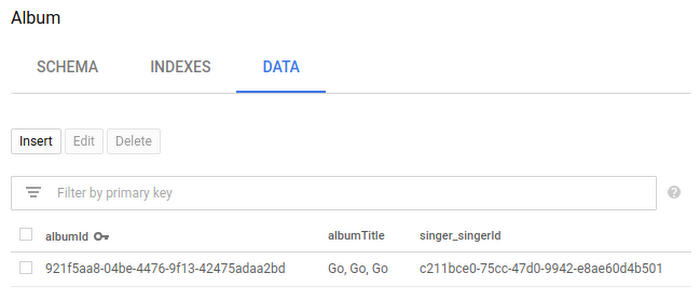
It’s nice to easily explore the tables in the Cloud Console, but we really want to query them in our application. So, finally, let’s query some data using Hibernate. Notice that we’re using HQL, which is portable across various Hibernate dialects, not just Cloud Spanner.
src/main/java/demo/Application.java
At last, make sure to close the Hibernate resources before the application shuts down.
src/main/java/demo/Application.java
For more details, check out a full working example or one of the other code samples we have that use Spring Data JPA, Microprofile, or Quarkus. Give Hibernate a try on Cloud Spanner, and send your feedback through the Github issue tracker.


