What’s New with Google’s Unified, Open and Intelligent Data Cloud

Bruno Aziza
Head of Data & Analytics, Google Cloud
We’re fortunate to work with some of the world’s most innovative customers on a daily basis, many of whom come to Google Cloud for our well-established expertise in data analytics and AI. As we’ve worked and partnered with these data leaders, we have encountered similar priorities among many of them: to remove the barriers of data complexity, unlock new use cases, and reach more people with more impact.
These innovators and industry disruptors power their data innovation with a data cloud that lets their people work with data of any type, any source, any size, and at any speed, without capacity limits. A data cloud that lets them easily and securely move across workloads: from SQL to Spark, from business intelligence to machine learning, with little infrastructure set up required. A data cloud that acts as the open data ecosystem foundation needed to create data products that employees, customers, and partners use to drive meaningful decisions at scale.
On October 11, we will be unveiling a series of new capabilities at Google Cloud Next ‘22 that continue to support this vision. If you haven’t registered yet for the Data Cloud track at Google Next, grab your spot today!
But I know you data devotees probably can’t wait until then. So, we wanted to take some time before Next to share some recent innovations for data cloud that are generally available today. Consider these the data hors d’oeuvres to your October 11 data buffet.
Removing the barriers of data sharing, real-time insights, and open ecosystems
The data you need is rarely stored in one place. More often than not data is scattered across multiple sources and in various formats. While data exchanges were introduced decades ago, their results have been mixed. Traditional data exchanges often require painful data movement and can be mired with security and regulatory issues.
This unique use case led us to design Analytics Hub as the data sharing platform for teams and organizations who want to curate internal and external exchanges securely and reliably.
This innovation not only allows for the curation and sharing of a large selection of analytics-ready datasets globally, it also enables teams to tap into the unique datasets only Google provides, such as Google Search Trends or the Data Commons knowledge graph.
Analytics Hub is a first-class experience within BigQuery. This means you can try it now for free using BigQuery, without having to enter any credit card information.
Analytics Hub is not the only way to bring data into your analytical environment rapidly. We recently launched a new way to extract, load, and transform data in real-time into BigQuery: the Pub/Sub “BigQuery subscription.” This new ELT innovation simplifies streaming ingestion workloads, is simpler to implement, and is more economical since you don’t need to spin up new compute to move data and you no longer need to pay for streaming ingestion into BigQuery.
But what if your data is distributed across lakes, warehouses, multiple clouds, and file formats? As more users demand more use cases, the traditional approach to build data movement infrastructure can prove difficult to scale, can be costly, and introduces risk.
That’s why we introduced BigLake, a new storage engine that extends BigQuery storage innovation to open file formats running on public cloud object stores. BigLake lets customers build secure, data lakes over open file formats. And, because it provides consistent, fine-grained security controls for Google Cloud and open-source query engines, security only needs to be configured in one place to be enforced everywhere.
Customers like Deutsche Bank, Synapse LLC, and Wizard have been taking advantage of BigLake in preview. Now that BigLake is generally available, I invite you to learn how it can help to build your own data ecosystem.

Unlocking the ways of working with data
When data ecosystems expand to data of all shape, size, type, and format, organizations struggle to innovate quickly because their people have to move from one interface to the next, based on their workloads.
This problem is often encountered in the field of machine learning, where the interface for ML is often different than that of business analysis. Our experience with BigQuery ML has been quite different: customers have been able to accelerate their path to innovation drastically because machine learning capabilities are built-in as part of BigQuery (as opposed to “bolted-on” in the case of alternative solutions).
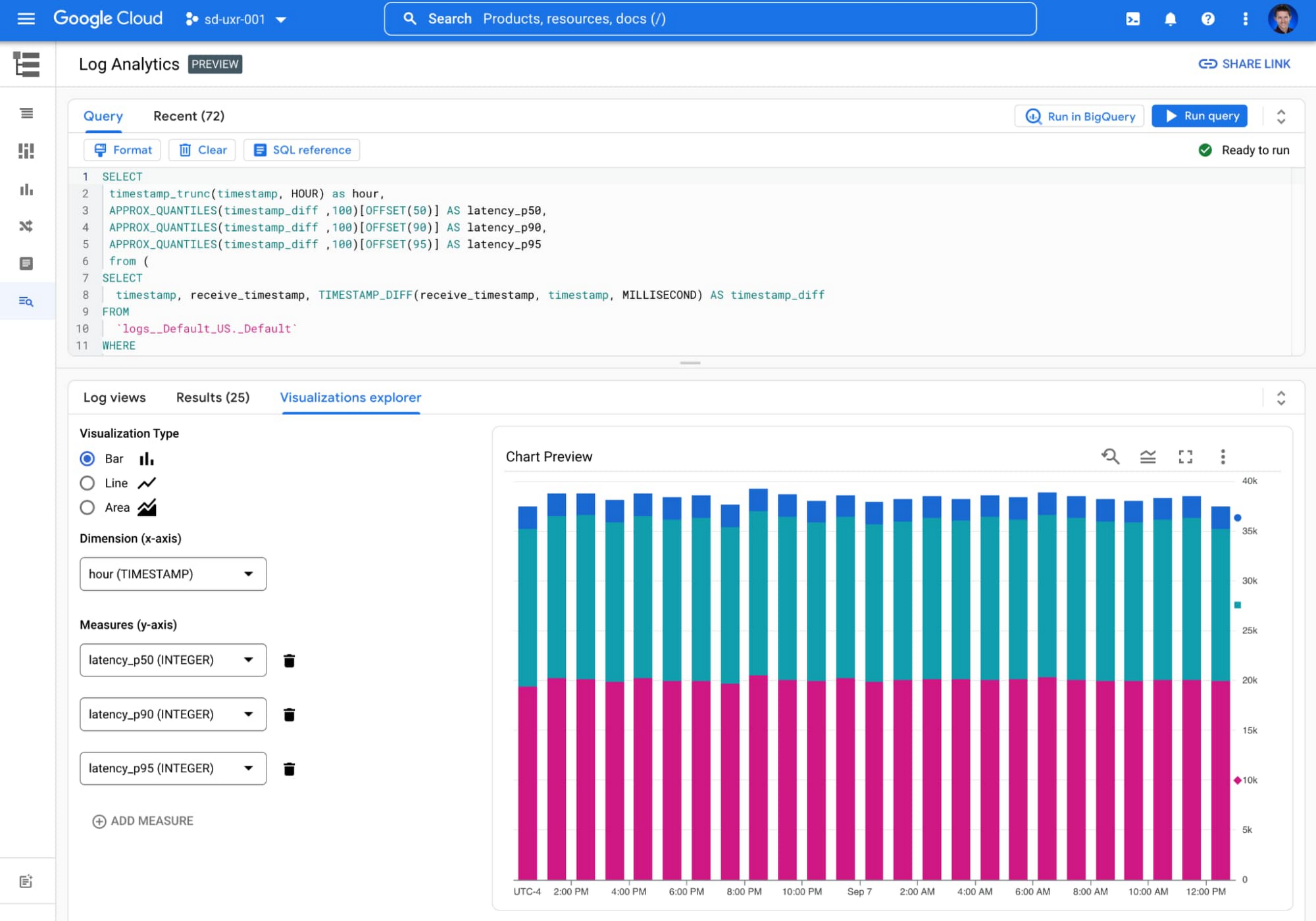
We’re now applying the same philosophy to log data by offering a Log Analytics service in Cloud Logging. This new capability, currently in preview, gives users the ability to gain deeper insights into their logging data with BigQuery. Log Analytics comes at no additional charge beyond existing Cloud Logging fees and takes advantage of soon-to-be generally available BigQuery features designed for analytics on logs: Search indexes, a JSON data type, and the Storage Write API.
Customers that store, explore, and analyze their own machine generated data from servers, sensors, and other devices can tap into these same BigQuery features to make querying their logs a breeze. Users simply use standard BigQuery SQL to analyze operational log data alongside the rest of their business data!
And there’s still more to come. We can’t wait to engage with you on Oct 11, during Next’22, to share more of the next generation of data cloud solutions. To tune into sessions tailored to your particular interests or roles, you can find top Next sessions for Data Engineers, Data Scientists, and Data Analysts — or create and share your own.
Join us at Next’22 to hear how leaders like Boeing, Twitter, CNA Insurance, Telus, L’Oreal, and Wayfair, are transforming data-driven insights with Google’s data cloud.
