Optimizing BigQuery for astronomy datasets using HealPix Index
Marcos Aurelio Poles de Souza
SAP Application Engineer
Dan Speck
VP, Technology R&D Burwood Group
This article covers how to enhance query performance on an astronomy dataset employing clustering of the records by HEALPix index. Although this article specifically refers to astronomy data, the techniques could be useful for any user of the BigQuery GIS platform.
Introduction to HEALPix
Briefly, HEALPix is a hierarchical equal-area pixelization scheme for the sphere. It is a widely used tool for representing and analyzing data on the celestial sphere. Clustering the records by Geopositioning fields and by adding a HEALPix index field for each record in the collection of tables involved in the dataset can improve the performance of queries that involve multiple tables because HEALPIX Index keep close together on the server nodes records within the region depicted by the HEALPix Index. This way BigQuery can optimize the query response and even filter out records from other clusters that are not required for processing the query.

Image 1: HEALPix grid resolutions. Reference: https://healpix.jpl.nasa.gov/index.shtml
Key concepts
First there are some key definitions for the rest of this article:
-
Clustered tables are tables that have a user-defined column sort order. The columns defined create storage blocks for the records based on their values of these fields in the records.
-
Materialized views are precomputed views that periodically cache the results of a query for increased performance.
-
HEALPix (Hierarchical Equal Area isoLatitude Pixelation) of a sphere. It is a subdivision of the spherical surface in which each pixel covers the same surface area as every other pixel. We use this as a column to cluster tables for the astronomy datasets as the majority of the query searches are for objects and their neighbors.
Reading this article you will, learn how to:
-
Create and measure the performance of clustered tables and materialized views
-
Transfer astronomy datasets to clustered tables efficiently
Bringing astronomy datasets to BigQuery
Many astronomy datasets are publicly available in different platforms and media and in some cases you may want to consolidate these datasets into BigQuery to have a central consolidated place with all the information needed to serve astronomers in their research. Frequently, transformations may be needed to harmonize and enhance records from the source datasets, such as adding the HEALPix Index to all records with Geoposition.
There are multiple options to migrate large datasets including astronomy datasets to BigQuery. In order to choose the best option, there are some areas to consider:
-
Size of the datasets: astronomy datasets can be very large, in some cases multiple PBs.
-
Data structure: astronomy datasets often have complex data structures with wide-size records that contain multiple positioning and characterists attributes.
-
Data validations: astronomy datasets often have complex data validations, for example the truth match validations.
-
Combining data from different tables or multiple observatories sources: combining data from different tables or multiple observatories sources can be complex and frequently involves a large number of records to be processed.
-
Storage Performance: the target storage for these datasets must be highly scalable to handle the high volumes and optimized for analytics to handle the queries and joins against the final tables where the different pieces of data will be stored.
It is important to have a clear understanding of the data, the target storage, and the migration process before beginning the migration.
The datasets used for this article contain a large amount of data and to speed up the migration with the necessary transformations to add HEALPix into Clustered Target tables and avoid duplication of data at the target, we used Google DataFlow (ApacheBeam SDK).
As Cloud Dataflow is a fully managed service for data processing, it provides a simple and familiar way to define data pipelines, then applies optimization and executes the pipelines using parallel processing on the Google Compute Engine resources. Also, during the execution users get visibility into the processing jobs and resources using cloud console monitoring.
Cloud Dataflow accepts Python and Java for programming the pipelines and for our transformation we used Python to leverage important libraries for this project such as HEALPY: the out-of-the-box library to perform HEALPix Index determination.
How does BigQuery help?
There are several benefits of using BigQuery as a platform for astronomy datasets:
-
BigQuery is a highly scalable and performant data warehouse that can handle large volumes of data, such as those generated by astronomical observatories.
-
It’s optimized for analytics, which means that it can quickly and easily answer complex queries on astronomy catalogs.
-
It offers a variety of features that are useful for astronomy, such as the ability to store and analyze geo-spatial data with out-of-the-box geopositioning data types and operations.
-
The analogy between geospatial data and astronomical data is well discussed in this article, Querying the Stars with BigQuery GIS.
-
BigQuery is a cloud-based service, which means that it can be accessed from anywhere in the world.
-
It’s a cost-effective solution for storing and analyzing datasets.
-
BigQuery offers clustered tables to speed up queries. Clustering is a good first option for improving query performance because it:
-
accelerates queries that filter on particular columns by only scanning the blocks that match the filter.
-
accelerates queries that filter on columns with many distinct values by providing BigQuery with detailed metadata for where to get input data.
-
enables the table's underlying storage blocks to be adaptively sized based on the size of the table.
-
It is important to create the tables clustered before loading the data.
-
-
BigQuery also offers materialized views to speed up complex and large table joins because materialized views are precomputed in the background when the base tables change. Any incremental data changes from the base tables are automatically added to the materialized views, with no user action required. Also it has smart tuning. If any part of a query against the base table can be resolved by querying the materialized view, then BigQuery reroutes the query to use the materialized view for better performance and efficiency.
Overall, BigQuery is a powerful and versatile tool that can be used to store, analyze, and share astronomy datasets. It is a good choice for astronomers who need to store and analyze large amounts of data, or who need to share their data with others.
The dataset we used
Our dataset is from Vera C. Rubin Observatory. Data Preview 0 (DP0) is the first data preview to test Legacy Survey of Space and Time (LSST) Science Pipelines and the Rubin Science Platform (RSP). DP0 will provide a limited number of astronomers and students with synthetic preview data, allowing them to prepare for science with the LSST. This dataset contains 5 tables with photometry, object details, position, and truth match records. These tables vary in size from 150 million to 800 million records (100 Gb to 300 Gb) in BigQuery.
When we uploaded the dataset into BigQuery Clustered tables by HEALPix Id, GeoPoint (latitude, longitude), and Object Identification, we use the following optimizations:
-
We applied the HEALPIx NESTED index to all records. This method labels cells in a specific sequence to preserve multiple levels and we used 512 cells per pixel.
-
We created a GEOPOINT type object column to leverage the Geoposition features from BigQuery and reduce the calculations of Geographical operations during query processing.
-
We also created materialized views for preprocessing large table joins.
Query improvements and metrics
Now that we have our data harmonized, loaded into the clustered tables, and the necessary materialized views created. We identified scenarios that required further optimizations on the query processing. We compared query executions in BigQuery on tables without clustering and the same query executions on tables with clusters. The data records used are the same in both tables.
Scenario 1: Clustered tables
|
Query Name |
BIG Query non-Clustered(seconds) |
BIG Query Clustered(seconds) |
|
Single Record Table Volume: 147 million rows (148 GB) |
1.9 |
0.8 |
|
Magnitude Between Values Table Volume: 147 million rows (148 GB) |
2.0 |
1.0 |
|
Truth match join Table1 Volume: 147 million rows (148 GB)Table2 Volume: 765 million rows(183 GB) |
29.6 |
20 |
Table 1: Queries runtime database comparison by query type.
We see a significant improvement on the performance of the BigQuery with clustered tables compared with the BigQuery without clustered tables for scenarios where the queries are executed with simple filters, range or values, or direct joins and filters.
Scenario 2: Materialized views
There are more complex scenarios involving geopositioning queries that require additional optimization. The use of materialized views preprocess and cache large table joins which records can be clustered together, providing further optimization.
Take for example the following query that selects an object within a circle in the sky and with limited magnitude intensity:
SELECT * FROM object AS obj JOIN truth_match AS truth ON truth.match_objectId = obj.objectId WHERE CONTAINS(POINT('ICRS', obj.ra, obj.dec), CIRCLE('ICRS', 61.863, -35.79, 0.05555555555555555))=1 AND (obj.mag_g <25 AND obj.mag_i <24)
These 2 tables are very large (147 million rows and 765 million rows) and the query optimizer would not be able to push down filters completely to process this query.
Therefore, we created a materialized view with all required non-duplicated columns from the 2 tables and clustered the materialized view by HEALPix, object id, object geoposition from object table.
The following figure shows the query execution on the materialized view and the filters being pushed down to the database which brought for processing a subset of the data and not the totality of the records.
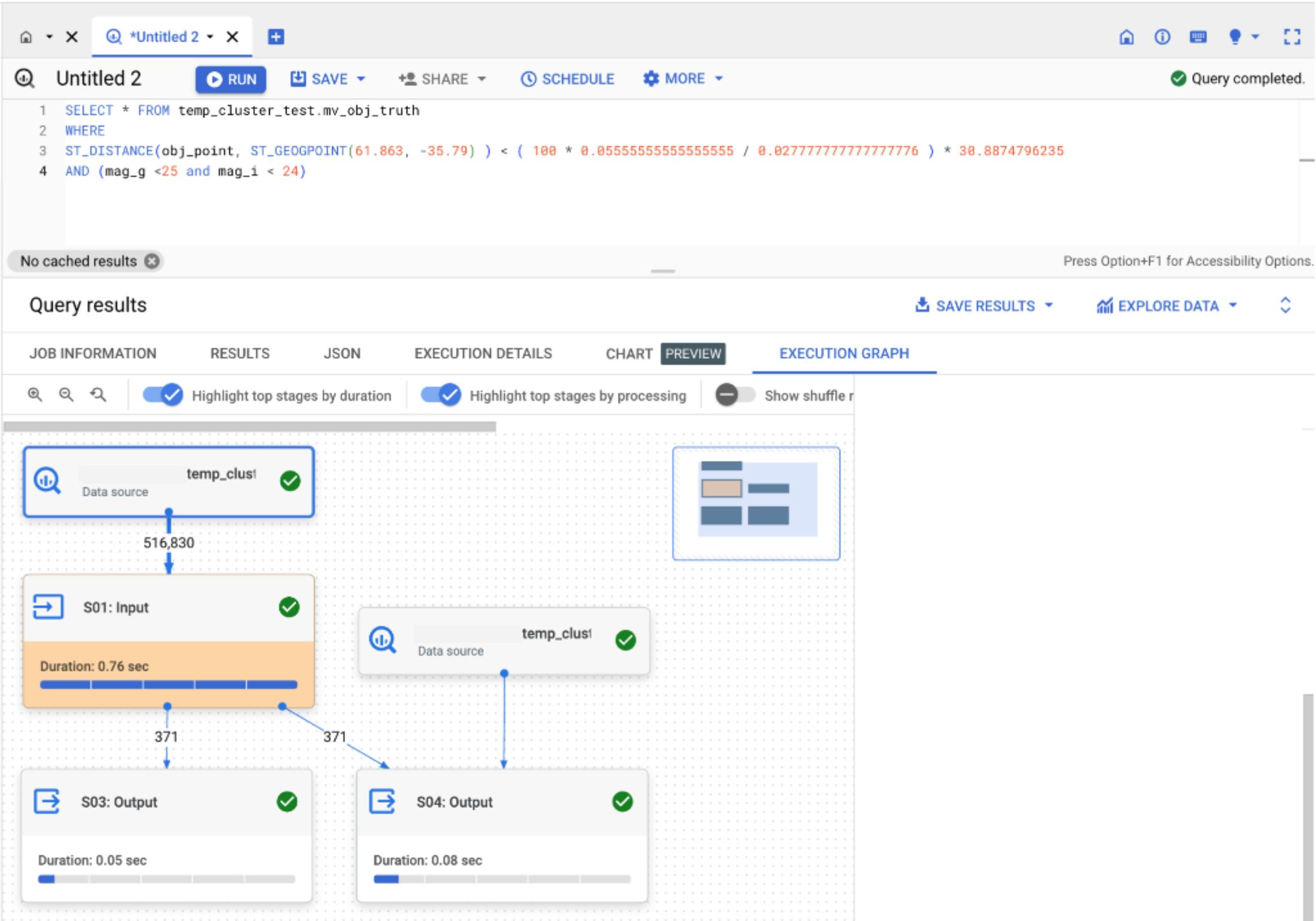
Image 2: Processing steps for the query using clustered materialized view.
Detailed runtime durations and consumption of BigQuery resources are described in the following image:
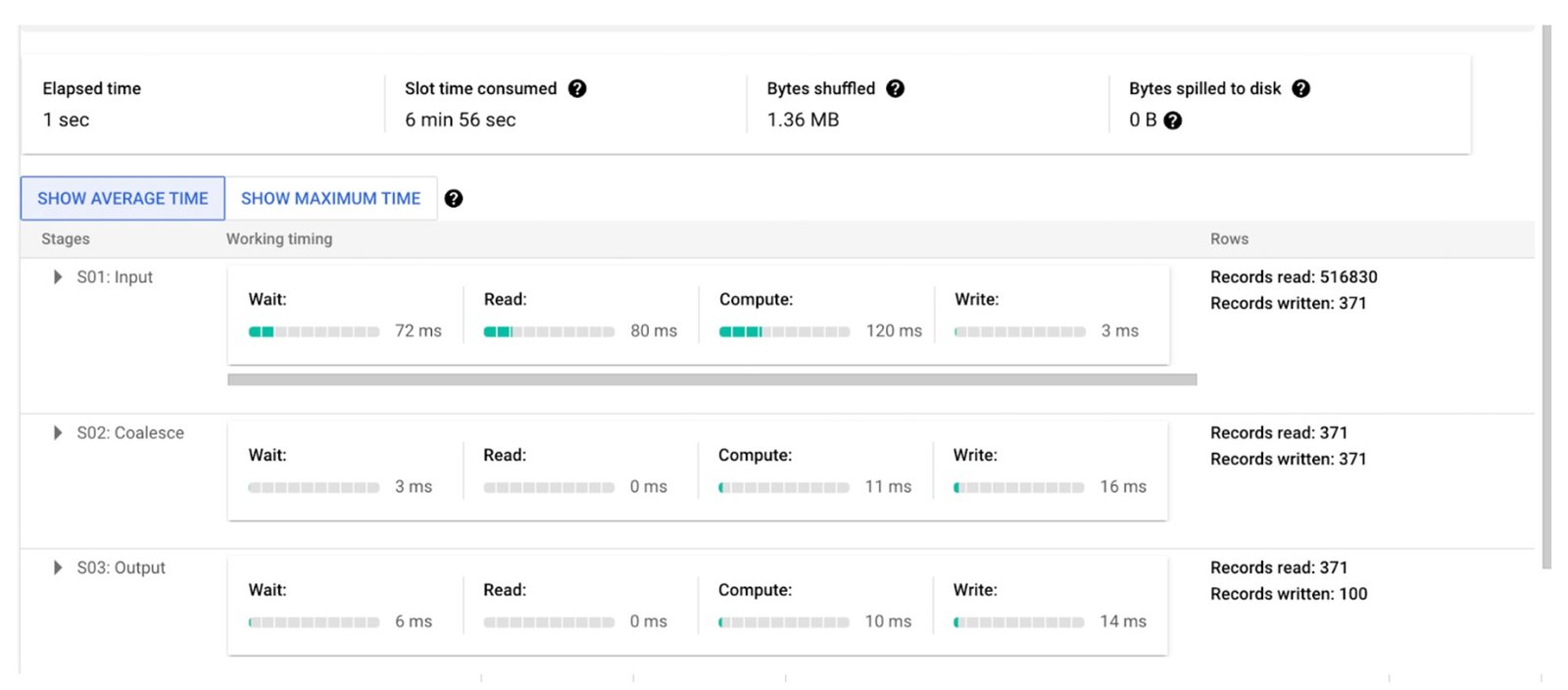
Image 3: Processing runtime details per step of querying materialized views.
The comparison results below shows a significant improvement results of the query with addition of clustered materialized view for processing:
|
Query Name |
BigQuery Clustered(seconds) |
BigQuery Materialized View(seconds) |
|
Magnitude cut in a cone on JOIN of object and truth-match (same query but with Materialized View) |
13 |
1 |
Table 2: Queries runtime database comparison with materialized view.
Closing
This article has discussed the benefits of migrating astronomy datasets into clustered tables in BigQuery and use cases for materialized views. It has also provided an approach on how to migrate astronomy datasets and improve query performance. This article results show that out-of-the-box BigQuery geopositioning functions, table clustering, and materialized views can significantly improve the performance of queries on large datasets. Customers around the globe may extend the application of these optimization approaches in large datasets in different scenarios.

