Tune Spark properties to optimize Dataproc Serverless jobs
Christian Yarros
Strategic Cloud Engineer, Google
Data scientists and engineers need large-scale compute resources but often need more know-how or the engineering team to create and manage the underlying infrastructure. Dataproc Serverless, the industry’s first autoscaling serverless product for Spark, simplifies their experience by not having to think about infrastructure for their work.
Dataproc Serverless uses Spark properties to determine the compute, memory, and disk resources to allocate to your batch workload. These property settings can affect workload quota consumption and cost (see Dataproc Serverless quotas and Dataproc Serverless pricing for more information).
This blog post will demonstrate how you can use these Spark properties to meet the runtime and cost service level agreements of your Spark jobs.
Before you begin
This blog post assumes the following:
You have an Apache Spark jar available for Dataproc Serverless.
Your project has the appropriate quota for testing.
You have no insight into what amount of cpus/memory/disk your job requires.
You’ve exhausted code optimization opportunities.
You have tried other methods such as optimizing GCS file structures / file types etc.
Dataproc Serverless and Apache Spark tuning is an iterative process. This guide outlines the steps to fine-tune your spark properties to meet cost and performance requirements. It will require you to submit your job several times.
Dataproc Serverless pricing
Dataproc Serverless for Spark pricing is based on the number of Data Compute Units (DCUs) and the amount of shuffle storage used. DCUs and shuffle storage are billed per second, with a 1 minute minimum charge.
For more information, visit: Dataproc Serverless pricing
Spark Persistent History Server and GCS Logging Output
Set up a Spark Persistent History Server (PHS) for your jobs. This will help during debugging and troubleshooting. All executors and driver logs are available in Cloud Logging while the Spark job is running. Also, Spark applications are visible in PHS while running (PHS > Incomplete Applications). Executor and driver logs are available in Cloud Logging, but the PHS has the Spark event logs that provide insight into Spark app execution (DAG, executor events, etc). The logs are actually stored in GCS; however, the UI to access them is available through the PHS (when the PHS is not running, Spark won't send the logs to GCS).
Additionally, set up a Google Cloud Storage bucket and pass these properties to your Spark job.
Tracking job performance/cost progress
Throughout your iterative experimentation, keep track of each job's properties and the impact on runtime and cost.

Submitting your job
If your job runtime / DCU usage is satisfactory, you can stop here. This can be found on the details tab of the Dataproc Serverless batch console:
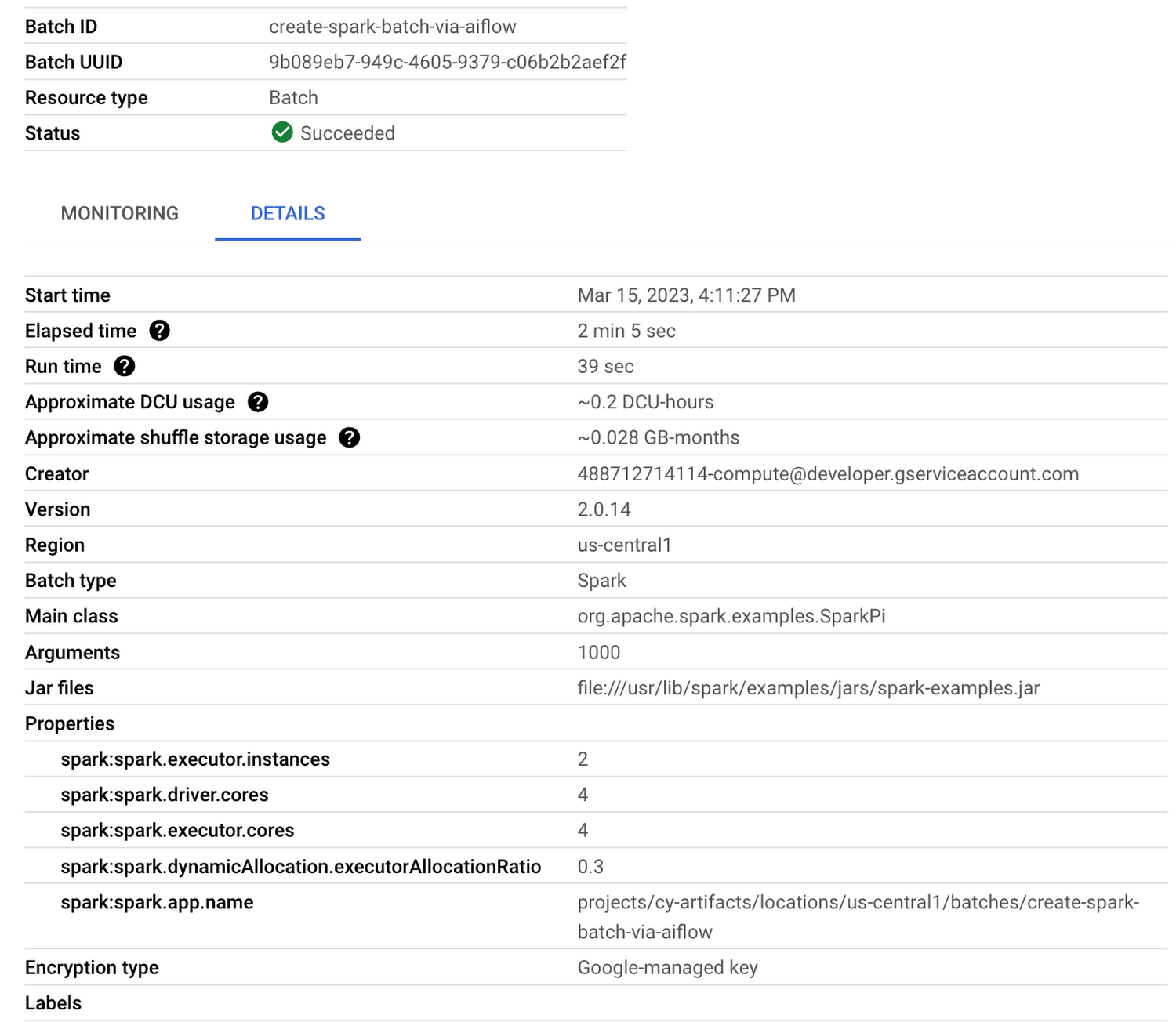
As your job runs, monitor the maximum-needed value in the Monitoring tab of the Dataproc Serverless batch console:
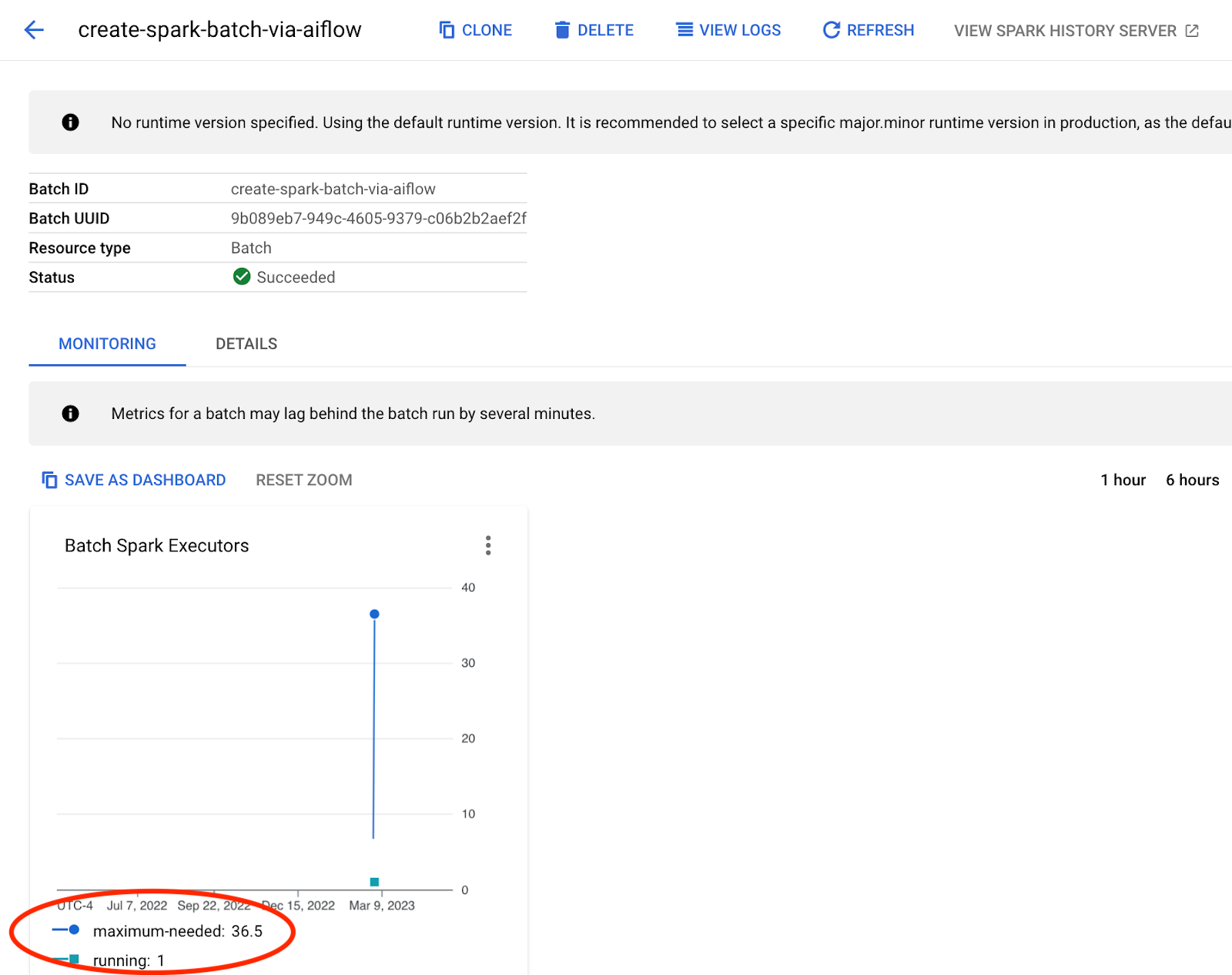
In the above example: maximum-needed = 36.5, but the job was only allocated with 1 executor.
The maximum-needed value is computed by adding the count of running tasks and pending tasks, and dividing by the tasks per executor. Dataproc Serverless will attempt to meet this demand based on the autoscaling-related properties passed during job submission. These properties are discussed in the next section.
Fine-tuning your Spark properties
Allocated job resources
For sake of simplicity, below are three example configurations for varying workloads. Experiment with each configuration to determine which best suits your job. To view the default Spark property values and learn more visit: Spark properties | Dataproc Serverless Documentation | Google Cloud
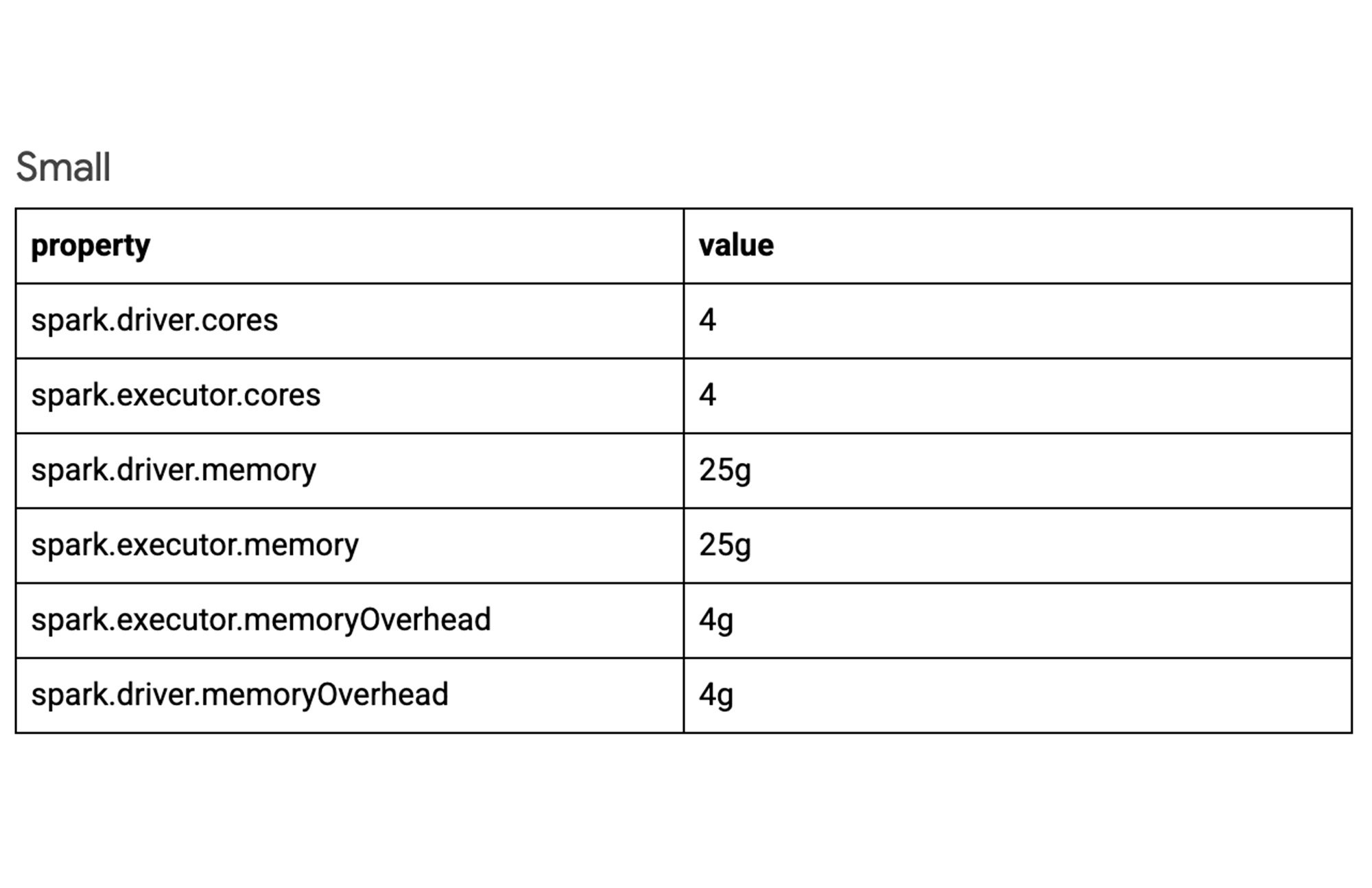
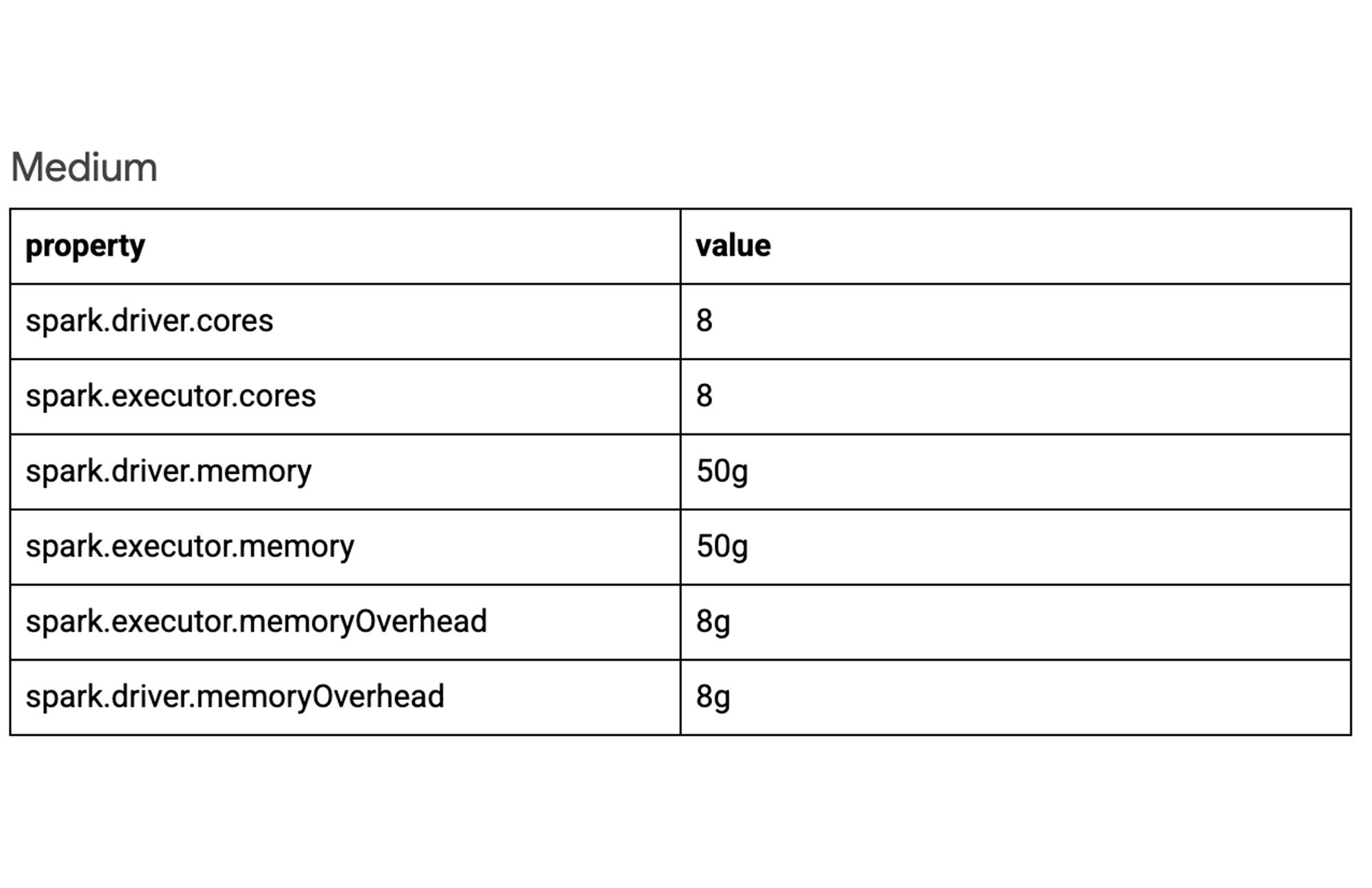
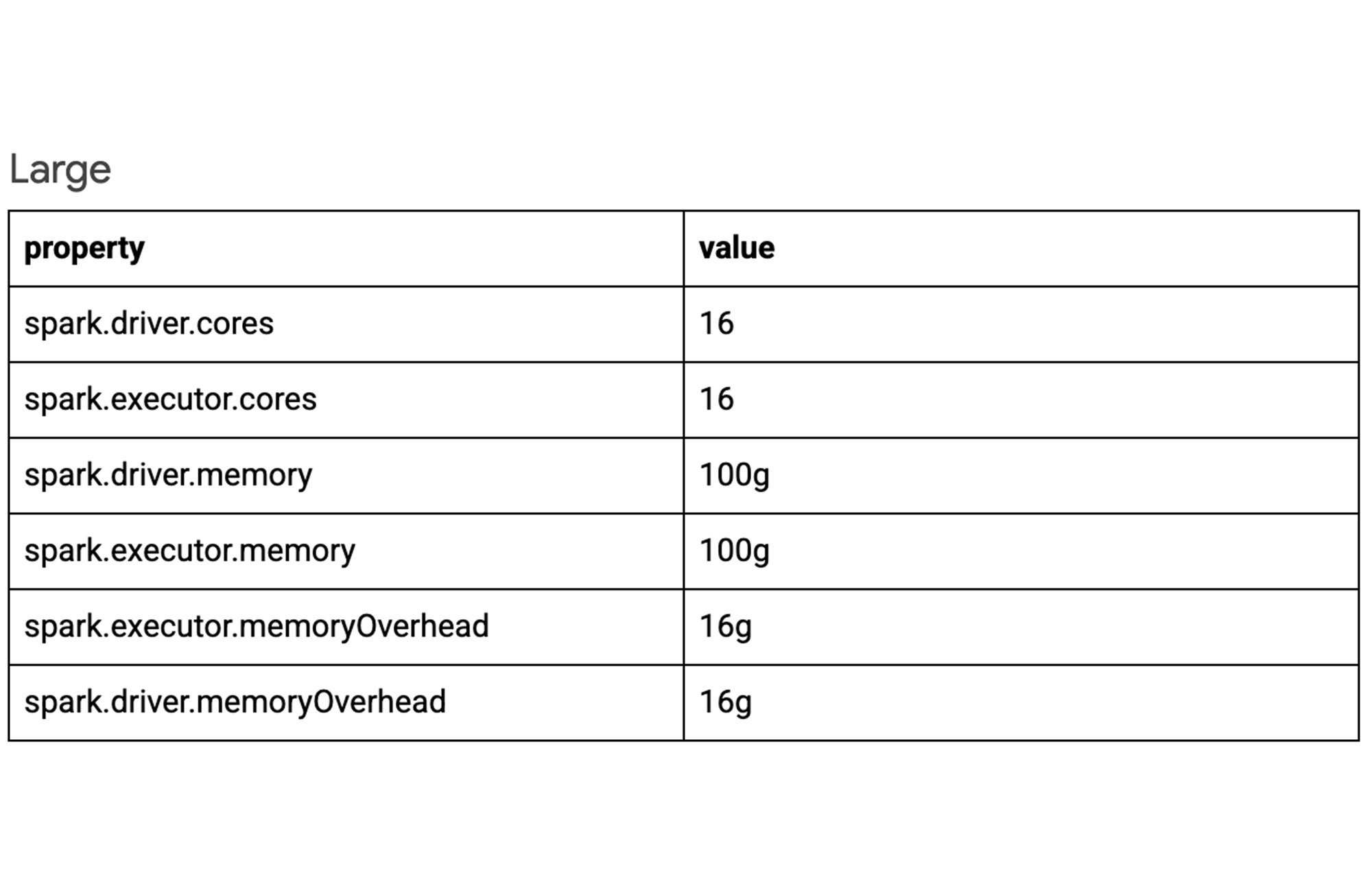
Autoscaling
Autoscaling helps cut costs by only using required resources, but may affect runtime and stability of the job. It is best to leave this as default until you are confident that runtime or job stability do not meet your needs.
Several properties influence scale range and rate, elaborated below. To view the default Autoscaling property values and learn more visit: Dataproc Serverless for Spark autoscaling.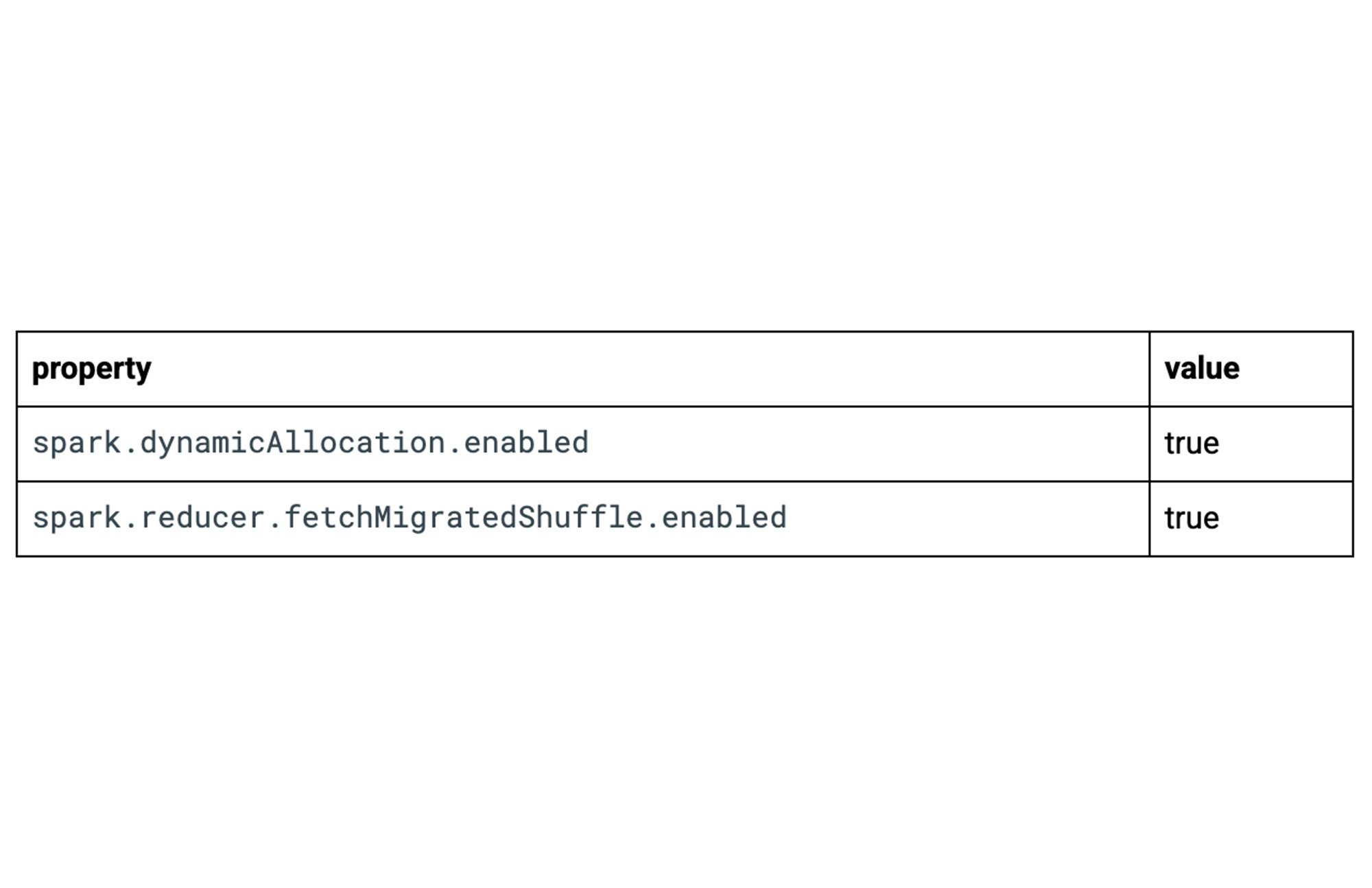
Range
Configuring a range will provide Dataproc Serverless jobs with a minimum and maximum number of executors. You can also set an initial amount (default is 2). Setting a sensible initial amount of executor instances will reduce runtime (less time spent autoscaling). Limit costs by setting maximum number of executors.

Rate
When autoscaling, Dataproc Serverless jobs compare the current number of executors vs. the maximum-needed (total number of running tasks and pending tasks, divided by the tasks per executor) and will increase/decrease the current number of executors to reach equilibrium. The rate of increase/decrease is determined by executorAllocationRatio and decommission.maxRatio.
The executorAllocationRatio property determines how quickly the job scales UP. The decommission.maxRatio property determines how quickly the job scales DOWN.
Decommissioning too many executors at the same time with shuffle or rdd migration could severely hurt performance of shuffle fetch. Therefore it is best to set this to a low value, 0.1-0.3 range. This will reduce performance regression caused by decommission.
For sake of simplicity, here are three example configurations for autoscaling rate:



No Autoscaling
Since we know how many executors your job needs based on the maximum-needed value, and since autoscaling takes time to scale up, we can set the min and max executors to be identical and turn off autoscaling. This will give your job the exact number of instances beginning / during your job run. Because dynamicAllocation is still enabled, you’ll be able to see the monitoring tab in the Dataproc Serverless job console.

Compute and disk tiers
One more way to boost the performance of your Dataproc Serverless job is to utilize compute and disk tiers. By default, your jobs will be set to standard tier. If you want higher per-core performance (compute) or better IOPS and throughput (disk), consider setting these properties to premium tier. Be aware that jobs will be billed at a higher rate with premium tiers.

Putting it all together
Consider the above options when submitting your job. Some example scenarios:
1. A job requires medium allocated job resources and moderate autoscaling?
2. A job requires maximum allocated job resources, fast autoscaling, and we know the initial executor amount to be 50?
3. A small-sized job has a predictable and consistent resource requirement of 20 executors and a need for high IOPS?
Common errors explained
Keep an eye on your project quota. If autoscaling is enabled and the project quota limit is hit, your job will not receive the resources it requires and may fail with this error.
Disk Usage = number_instances * number_cores * disk_size
CPU Usage = number_instances * number_cores
CourseGrainedSchedulerErrorThis error usually relates to insufficient resources. Try increasing the driver cores/memory and/or the number of executor instances.
FetchFailedExceptionTry setting
spark.reducer.fetchMigratedShuffle.enabled=trueFor more information, visit Spark Dynamic Allocation Issues and Solutions
Next steps
As discussed in this blog post, Dataproc Serverless uses Spark properties to determine the compute, memory, and disk resources to allocate to your batch workload. These property settings can affect workload quota consumption and cost (see Dataproc Serverless quotas and Dataproc Serverless pricing for more information). Thus, it is essential to understand how these properties function and interact with each other.
To get started with Dataproc Serverless, check out our Serverless Spark Workshop or the Dataproc Serverless Quickstart.
If you want to learn more, check out some related blog posts:

