10 top tips: Unleash your BigQuery superpowers
Felipe Hoffa
Developer Advocate, Google Cloud Platform
Lots of us are already tech heroes by day. If you know SQL, for example, you’re a hero.You have the power to transform data into insights. You can save the day when someone in need comes to you to reveal the magic numbers they can then use in their business proposals. You can also amaze your colleagues with patterns you found while roaming around your data lakes.
With BigQuery, Google Cloud’s enterprise data warehouse, you quickly become a superhero: You can run queries faster than anyone else. You’re not afraid of running full table scans. You’ve made your datasets highly available, and you no longer live in fear of maintenance windows. Indexes? We don’t need indexes where we’re going, or vacuums either.
If you’re a BigQuery user, you’re already a superhero. But superheroes don’t always know all their superpowers, or how to use them. Here are the top 10 BigQuery superpowers to discover.

1. The power of data
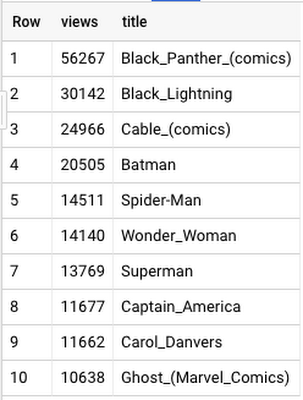
Let’s say your favorite person has been trapped by an evil force, which will only release them if you answer this simple riddle: Who were the top superheroes on Wikipedia the first week of February 2018?
Oh no! Where will you get a log of all the Wikipedia page views? How can you tell which pages are superheroes? How long will it take to collect all of this data, and comb through it all? Well, I can answer that question (see the source data here). Once data is loaded, it will only take 10 seconds to get the query results. This is how:
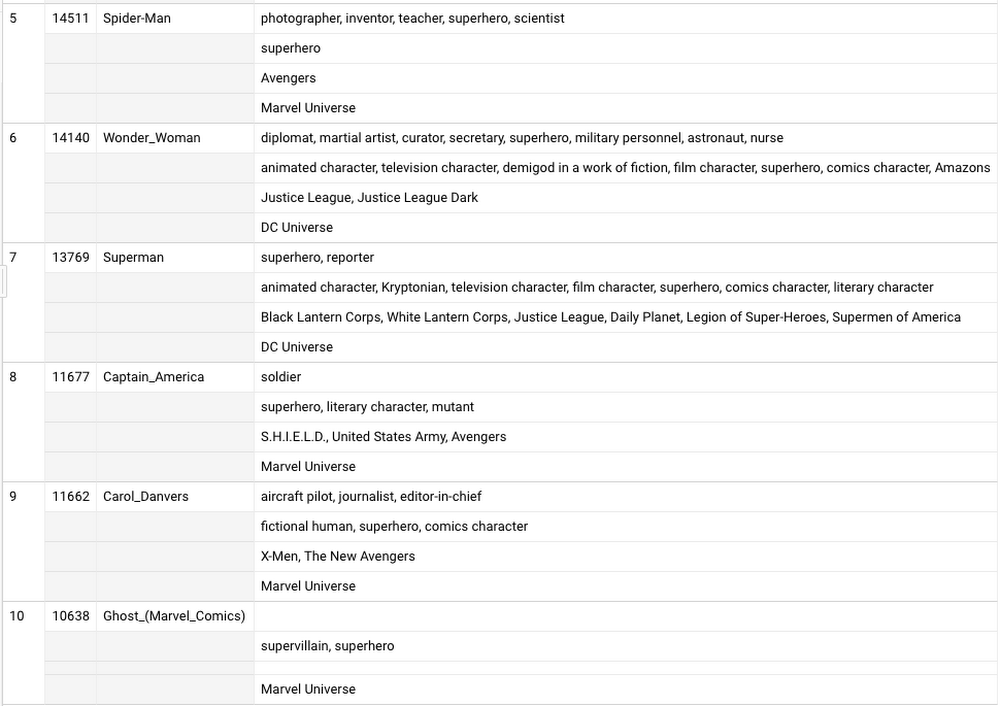
There it is—all the superheroes on the English Wikipedia page, and the number of page views for whatever time period you choose. And these are the top 10, for the first week of February 2018:
You’ve saved your friend! But first, the evil spirit needs more detail. Well, this query will do:
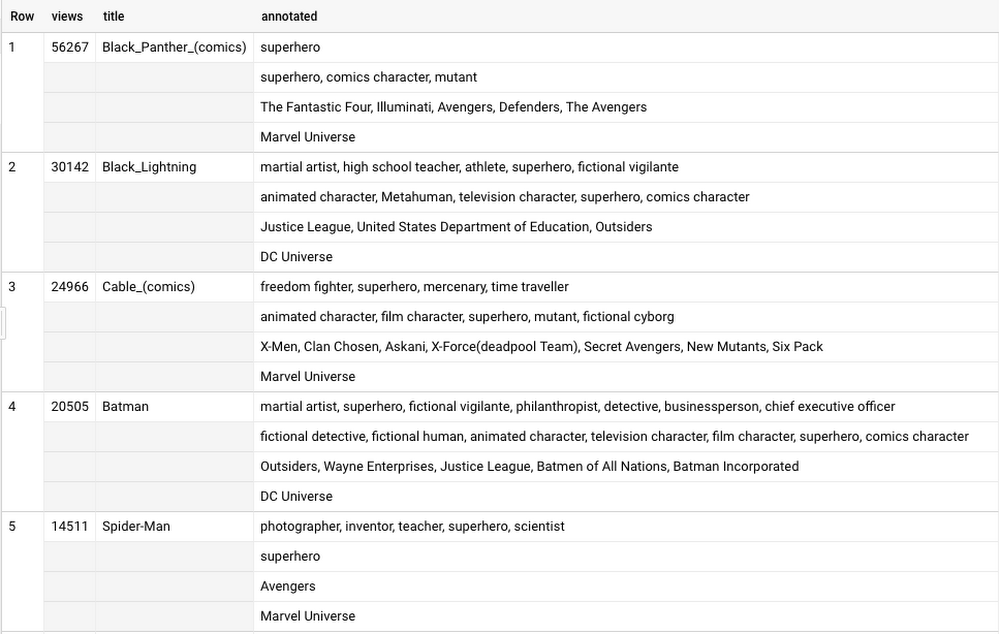
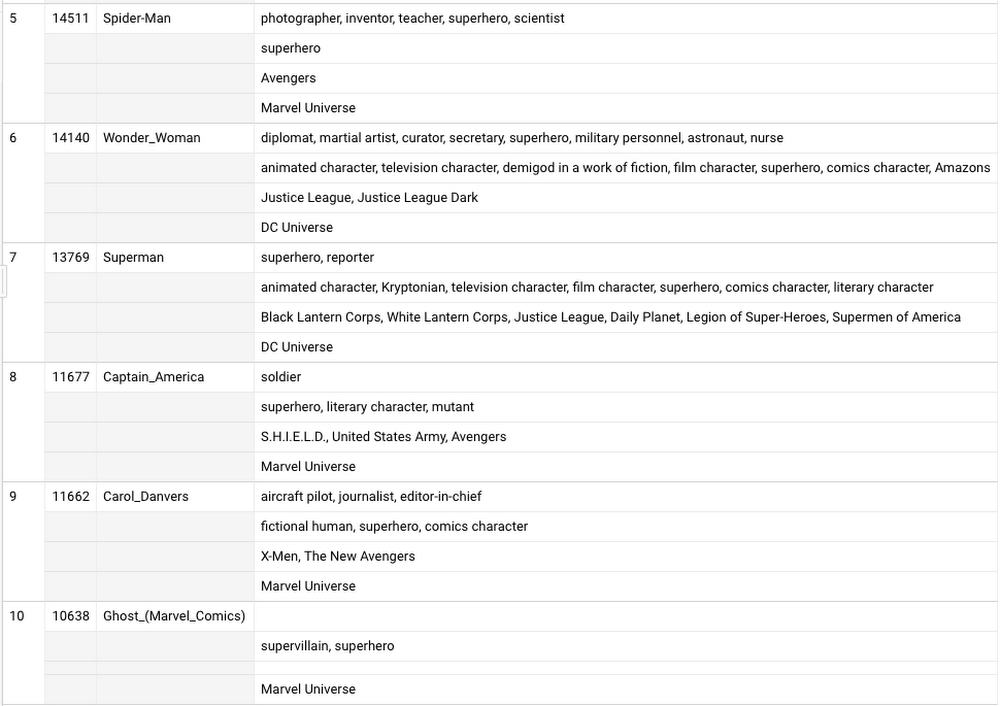
You can have the power of data too: check out the Wikipedia pageviews, and my latest Wikidata experiments (plus all of BigQuery’s public datasets) and copy paste these queries, modify them, and save your friends.
2. The power of teleportation
You want to see the tables with the Wikipedia pageviews and Wikidata? Let’s jump to the BigQuery web UI. Did you know that you can autocomplete your queries while typing them? Just press tab while writing your queries. Or you can run a sub-query by selecting it and pressing CMD-E. And teleportation? Jump straight to your tables with CMD and click on them. For example, that Wikipedia 2018 page views table we queried previously has more than 2TB of data, and the Wikidata one has facts for more than 46 million entities. And we just joined them to get the results we wanted.
Also, while looking at the schema, you can click on the fields, and that will auto-populate your query. Ta-da!
3. The power of miniaturization
Did I just say that the page views table has more than 2TB of data? That’s a lot! Remember that in BigQuery you have 1TB of free queries every month, so going through 2TB in one query means you will be out of the free quota pretty quickly. So how much data did I just consume? Let me run that first query again, without hitting the cache.
The result? 4.6 sec elapsed, 9.8 GB processed.
How is that possible? I just joined a 2TB table with a 750GB one. Even with partitioning, one week of Wikipedia page views is 2TB, divided by 52 weeks…that’s 38.5GB. So even with daily partitioning, I’m somehow querying less data.
Well, turns out I have the data in the tables clustered by the language of the Wikipedia and title, so I can make sure to always use those filters when going through the Wikipedia logs.
And that’s how you miniaturize your queries!
4. The power of X-ray vision
Let's say you want to get more data out of Wikidata for each superhero. Well, this query will do: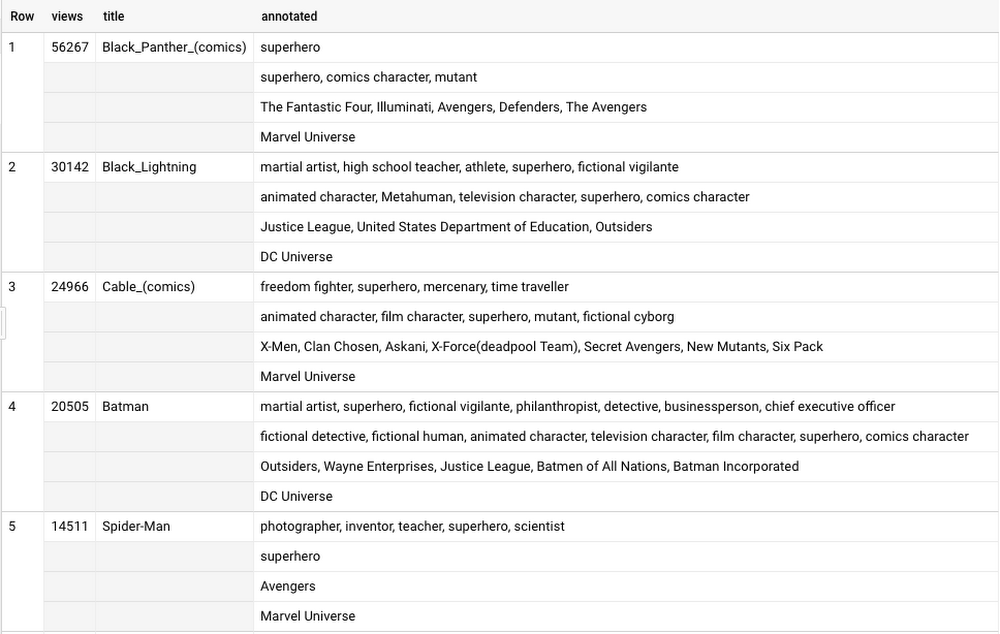
Why did this query take more time to process? Well, with our X-ray vision powers, we can see what BigQuery did in the background. Let’s look at the query history and the execution details tab.
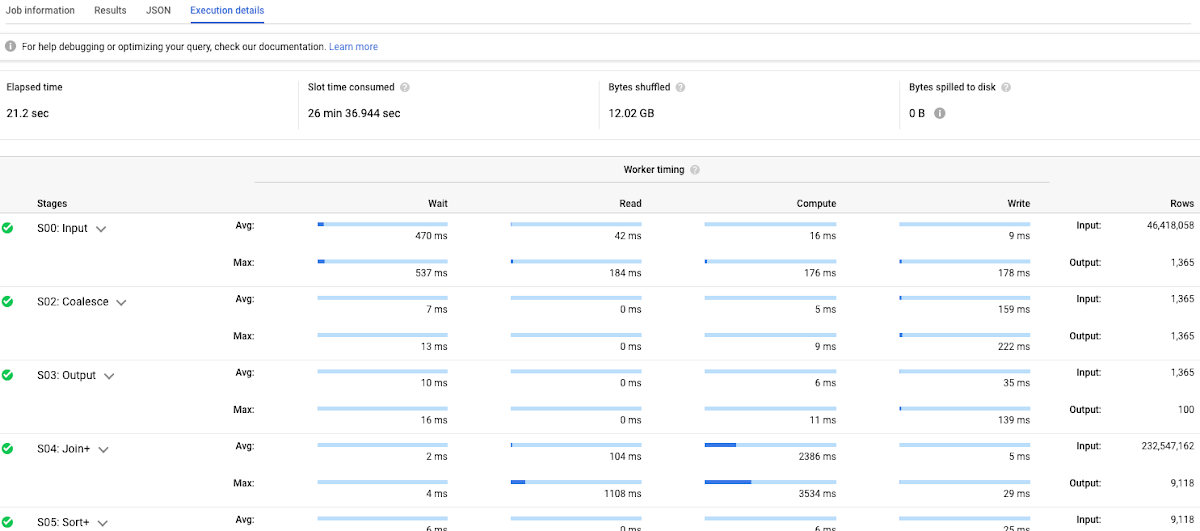
Those are all the steps BigQuery had to go through to run our query. Now, if this is a little hard to read, we have some alternatives. For example, the legacy BigQuery web UI has more compact results:
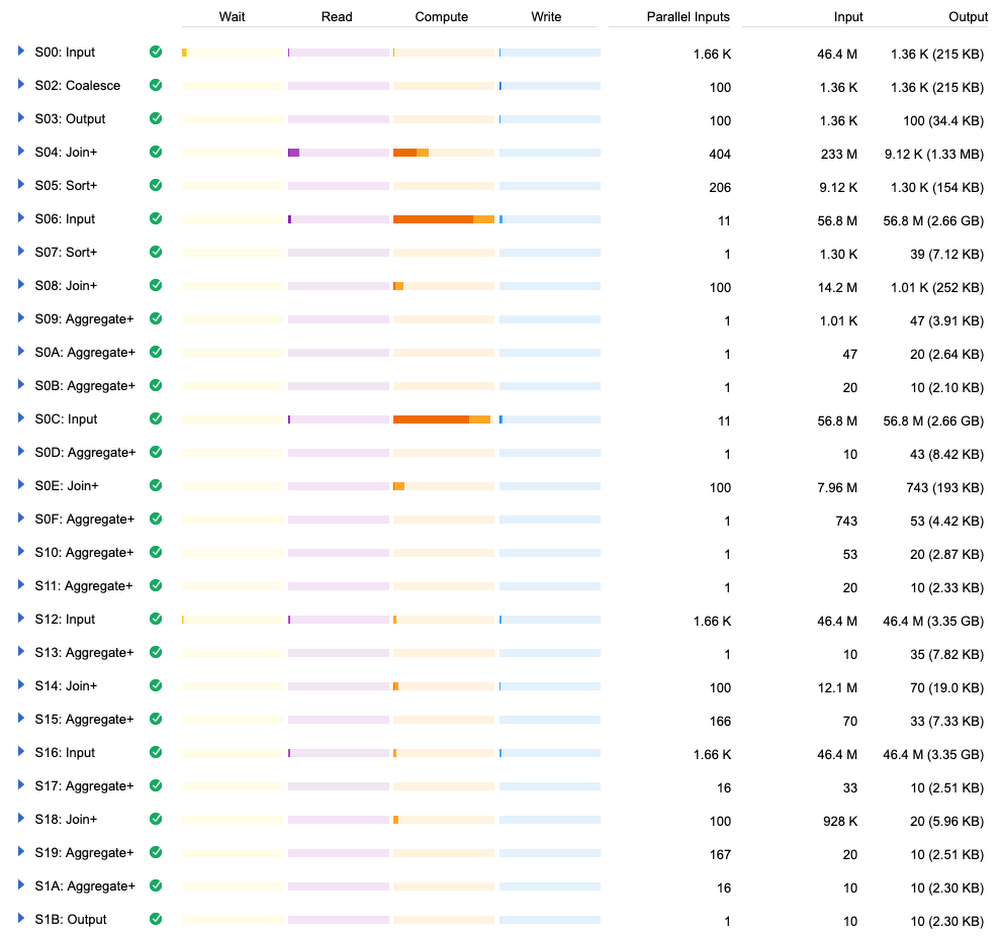
You can see that the slowest operations were computing while reading the 56-million-row table twice.
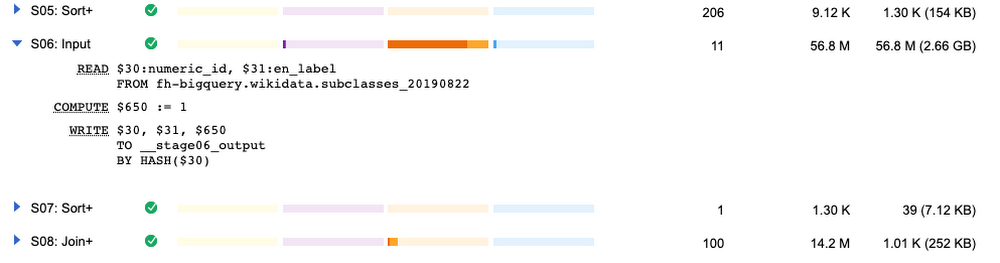
I’ll focus on that to improve performance. If I change the two, shown in these lines:
Now my query runs in half the time! The slowest part has moved elsewhere, as shown here:
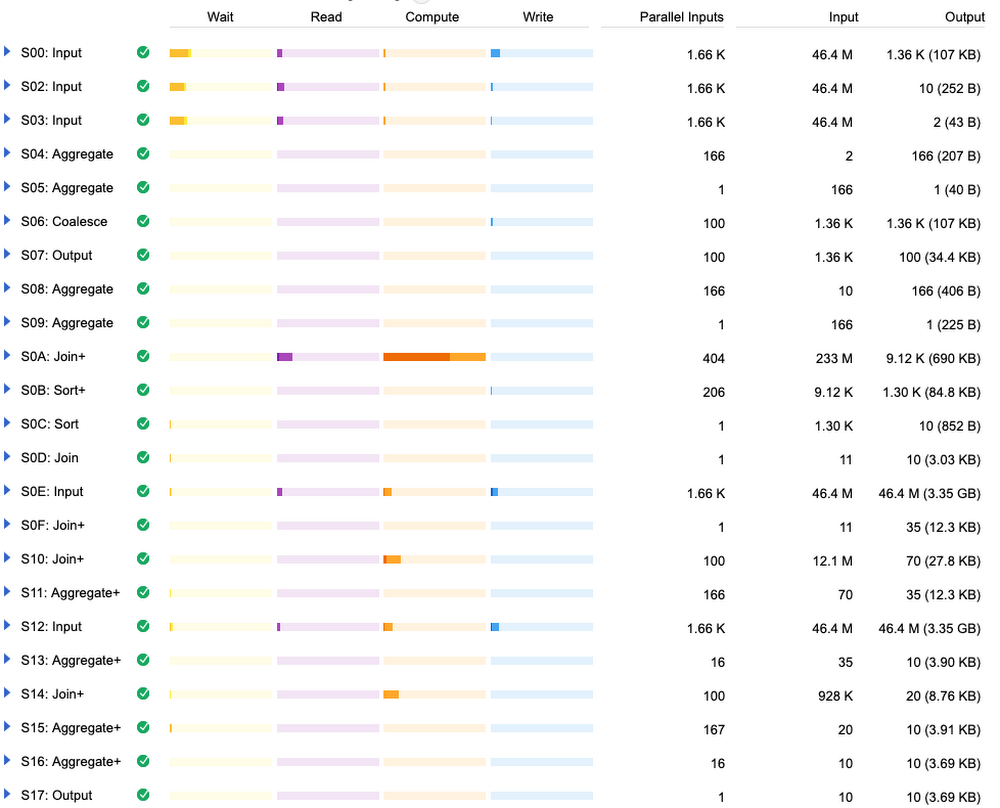
Which is this JOIN now:

It even shows us that it’s looking for all the superheroes between “3-D Man” and “Zor-El”… yes, it’s going through the whole alphabet. Get an even deeper view of the BigQuery query plan visualizer.
5. The power of materialization
It’s really cool to have these tables in BigQuery. But how did I load them? I periodically bring new raw files into Cloud Storage, and then I read them raw into BigQuery. In the case of the Wikipedia pageviews, I do all the CSV parsing inside BigQuery, as there are many edge cases, and I need to solve some case by case.
Then I materialize these tables periodically into my partitioned and clustered tables. In the case of Wikidata, they have some complicated JSON—so I read each JSON row raw into BigQuery. I could parse it with SQL, but that’s not enough. And that brings us to our next super power.
6. Navigating the multiverse
So we live in this SQL universe, a place where you can go beyond SQL alone. It’s an incredible place to manipulate and understand data, but each universe has its limitations and its rules. What if we could jump to a different universe, with different rules and powers, and manage to connect both universes, somehow? What if we could jump into the...JavaScript universe? We can, with UDFs—user-defined functions. They can easily extend BigQuery's standard SQL. For example, I can download a random JavaScript library and use it from within BigQuery, like for performing natural language processing and lots more.
Using UDFs means I can take each row of Wikidata JSON from above and parse it inside BigQuery, using whatever JavaScript logic I want to use, and then materialize this into BigQuery.
7. Time travel
Let’s take one particular table. It’s a beautiful table, with a couple thousand rows. But not everyone is happy—turns out someone wants to delete half of its rows, randomly. How would our super-enemy pull this off?
Oh no. Half of the rows of our peaceful universe are gone. Randomly. How is that even fair? How will we ever recover from this?
5 days later
We learned how to move forward without these rows, but we still miss them. If only there was a way to travel back in time and bring them back.
Yes we can.
Instead of:
we can write:
Warning: CREATE OR REPLACE TABLE deletes the table history, so write the results elsewhere.
8. The power of super-speed
How fast is BigQuery? It’s this fast.
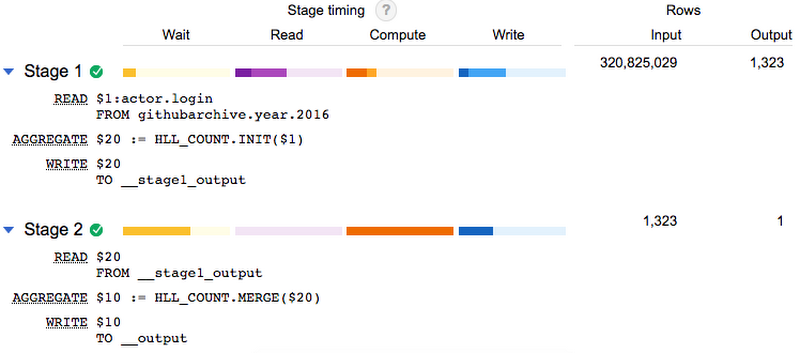
The quick summary: BigQuery can run HyperLogLog++, Google’s internal implementation of the HyperLogLog algorithm, for cardinality estimation. It lets BigQuery count uniques a lot faster than other databases can do, and has some other cool features that make BigQuery perform incredibly well.
9. Invulnerability
Our most annoying enemy? It’s a black hole of data, that thing that happens when we try to divide by zero. However it’s possible to avoid that using BigQuery expressions like the SAFE. prefix.
SAFE. prefix
Syntax:
Description
If you begin a function with the SAFE. prefix, it will return NULL instead of an error.
Operators such as + and = do not support the SAFE. prefix. To prevent errors from a division operation, use SAFE_DIVIDE. Some operators, such as IN, ARRAY, and UNNEST, resemble functions, but do not support the SAFE.prefix. The CAST and EXTRACT functions also do not support the SAFE. prefix. To prevent errors from casting, use SAFE_CAST. Find out more in the BigQuery docs.
10. The power of self-control
All superheroes struggle when they first discover their super-powers. Having super strength is cool, but you can break a lot of things if you’re not careful. Having super-speed is fun—but only if you also learn how to brake. You can query 5PB of data in three minutes, sure—but then remember that querying 1PB is one thousand times more expensive than querying 1TB. And you only have 1TB free every month. If you have not entered a credit card, don’t worry—you will have your free terabyte every month, no need to have a credit card. But if you want to go further, now you need to be aware of your budget and set up cost controls.
Check out this doc on creating custom cost controls, and find out how BigQuery Reservations work to easily use our flat-rate pricing model. Remember, with great powers comes great responsibility. Turn on your cost controls.
And there are a lot more. How about the power to predict the future? And there’s a whole world of ML to explore, not to mention all the GIS capabilities you can find in BigQuery. Check out Lak Lakshmanan talk about more of the awesome resources we have. And that brings me to our bonus super power:
11. The power of community
No superhero should stand alone. Join our Reddit community, where we share tips and news. Come to Stack Overflow for answers, and to help new superheroes learning the ropes. We can all learn from each other. And follow me and my friends on Twitter.
If you’re ready to test your powers, try to solve our weekly BigQuery Data Challenge. It’s fun, free of charge, and you might win $500 in cloud credits!
