Testing Cloud Pub/Sub clients to maximize streaming performance
Daniel Collins
Software Engineer
Cloud Pub/Sub, part of Google Cloud Platform (GCP), lets you ingest event streams from a wide variety of data sources, at nearly any scale, and allows horizontal application scaling without additional configuration. This model allows customers to sidestep complexities in operations, scaling, compliance, security, and more, leading to simpler pipelines for analytics and machine learning. However, Cloud Pub/Sub’s enablement of horizontal scaling adds the additional requirement to orchestrate multiple machines (instances or Cloud Pub/Sub clients). So to verify that Cloud Pub/Sub client libraries can handle high-throughput single-machine workloads, we must first understand the performance characteristics of a single, larger machine.
With that in mind, we’ve developed an open-source load test framework, now available on GitHub. In this post, you’ll see single-machine application benchmarks showing how Cloud Pub/Sub can be expected to scale for various programming languages and scenarios. These details should also help you understand how a single Cloud Pub/Sub client is expected to scale using different client libraries, as well as how to tune the settings of these libraries to achieve maximum throughput. Note that the Cloud Pub/Sub service is designed to scale seamlessly with the traffic you send to it from one or more clients; the aggregate throughput of the Cloud Pub/Sub system is not being measured here.
Here’s how we designed and tested this framework.
Setting up the test parameters
We will publish and subscribe from single, distinct Compute Engine instances of various sizes running Ubuntu 16.04 LTS. The test creates a topic and publishes to it from a single machine as fast as it can. The test also creates a single subscription to that topic, and a different machine reads as many messages as possible from that subscription. We’ll run the primary tests with 1KB-sized messages, typical of real-world Cloud Pub/Sub usage. Tests will be run for a 10-minute burn-in period, followed by a 10-minute measurement period. The code we used for testing is publicly available on GitHub, and you can find results in their raw form here.
Using vertical scaling
As the number of cores in the machine increases, the corresponding publisher throughput should be able to increase to process the higher number of events being generated. To do so, you’ll want to choose a strategy depending on the language’s ability for thread parallelism. For thread-parallelizable languages such as Java, Go, and C#, you can increase publisher throughput by having more threads generating load for a single publisher client. In the test, we set the number of threads to five times the number of physical cores. Because we are publishing in a tight loop, we used a rate limiter to prevent running out of memory or network resources (though this would probably not be needed for a normal workflow). We tuned the number of threads per core on the subscribe side on a per-language basis, and ran both Java and Go tests at the approximate optimum of eight threads/goroutines per core.
For Python, Node, Ruby and PHP, which use a process parallelism approach, it’s best to use one publisher client per hardware core to enable maximum throughput. This is because GRPC, upon which the client libraries tested here are built, requires tricky initialization after all processes have been forked to operate properly.
Getting the test results
The following are results from running the load test framework under various conditions in Go, Java, Node and Python, the four most popular languages used for Cloud Pub/Sub. These results should be representative of the best-case performance of similar languages when only minimal processing is done per message. C# performance should be similar to Java and Go, whereas Ruby and PHP would likely exhibit performance on par with Python.
To achieve maximum publisher throughput, we set the batching settings to create the largest batches allowed by the service, the maximum of either 1,000 messages or 10MB per batch, whichever is smaller. Note that these may not be the optimal settings for all use cases. Larger batch settings and longer wait times can delay message persistence and increase per-message latency.
In testing, we found that publisher throughput effectively scales with an increase in available machine cores. Compiled/JIT language throughput from Java, Go and Node is significantly better than that of Python. For high-throughput publish use cases such as basic data transfer, you should choose one of these languages. Note that Java performs the best among the three. You can see here how each performed:
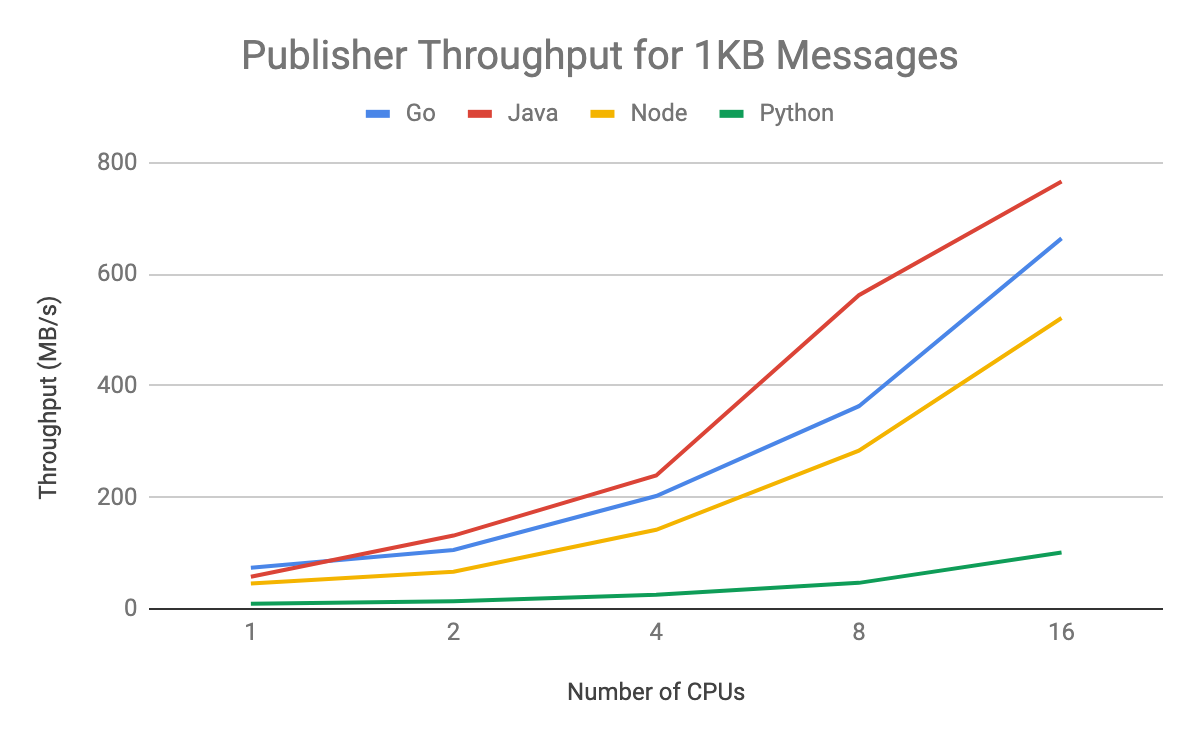
The subscriber throughput should also be able to scale to take full advantage of the available resources for handling messages. Similar to the publisher model, thread-parallel languages should use the parallelism options in the subscriber client to achieve optimal throughput. Subscriber flow control settings, by default, are set to 1,000 messages and 1GB outstanding for most languages. It’s best to relax those for the small message use case, since they will hit the 1,000 message limit with only 1MB of outstanding messages, limiting their throughput. For our load testing purposes, we used no message limit and a 100MB per worker thread size limit. Process parallel languages should use one worker per process, similar to the publisher case.
Subscriber throughput is much higher in Java or Go than in Node or Python. For high-throughput subscribing use cases, the difference between Java and Go performance is negligible, and either would work well. You can see this in graph form here:
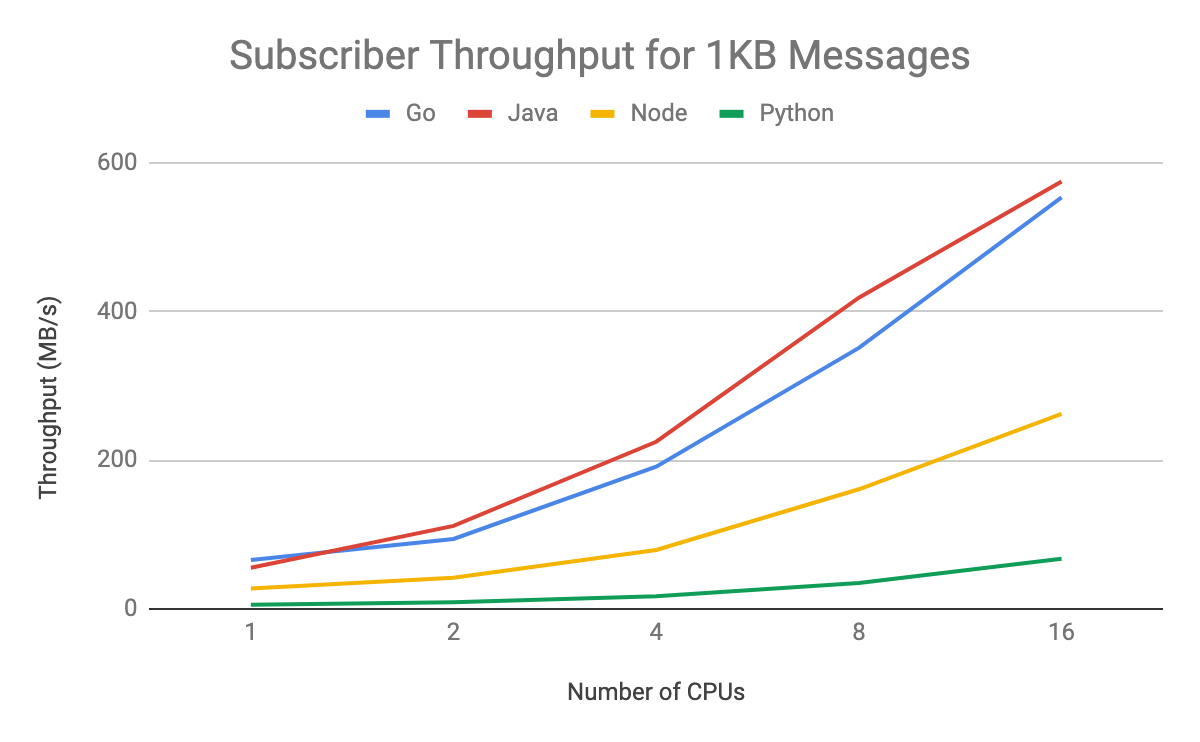
Considering other scaling modes
There are other considerations when looking at how the system scales beyond just the number of allocated CPU cores. For example, the number of workers per CPU core has a great impact on the throughput of subscriber clients. High-throughput users should change parallelPullCount in Java and numGoroutines in Go from their default values, which are set to one to prevent small subscribers from running out of memory.
The default client library settings, because they exist as a safety mechanism, are tuned away from high-throughput use cases. For both Java and Go, the performance peak in our tests occurred at around 128 workers on a 16-core machine, or eight workers per core. Here’s what that looked like:
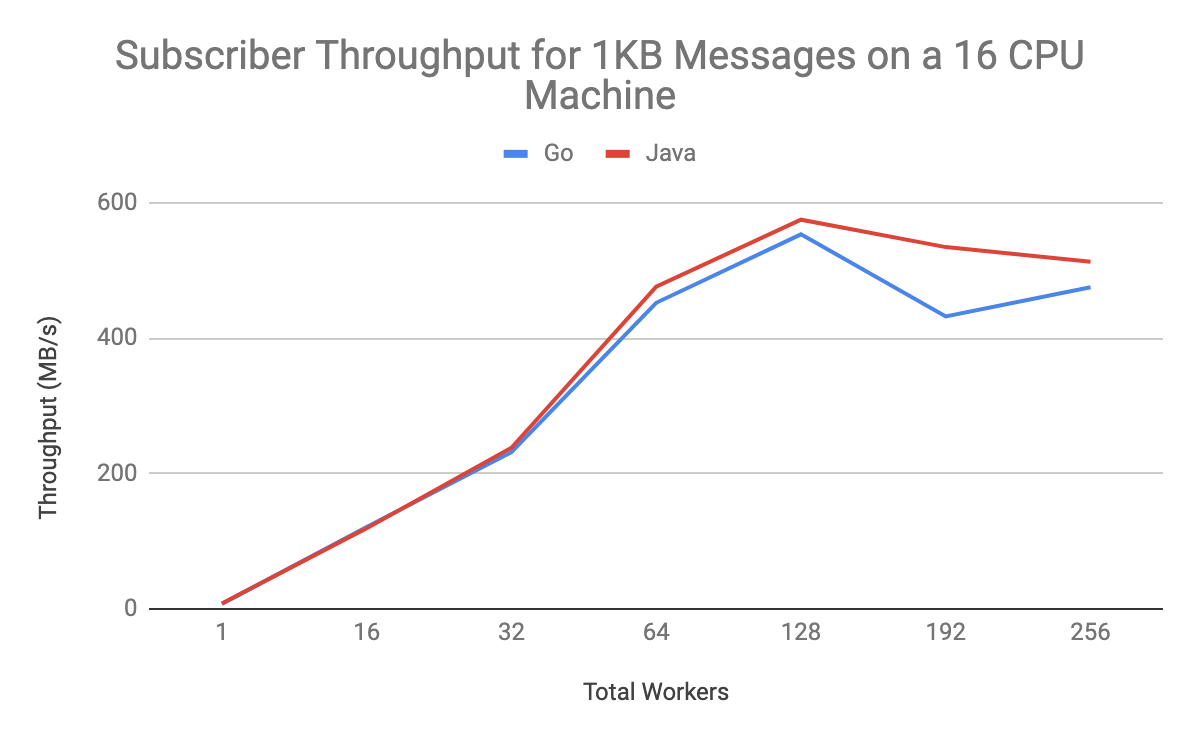
Message size can also have an effect on throughput. Cloud Pub/Sub can more efficiently process larger messages than a batch of small messages, since less work is required to package them for publishing or unpackage them for subscribing. This is important for data transfer use cases: If you have control over the size of your data blocks, larger sizes will yield higher throughput. You still should not expect to see large gains beyond 10KB message sizes using these settings. If you increase the thread parallelism settings, you may see higher throughput for larger message sizes.
A few notes on these particular results: If you want to replicate these results, you’ll need to publish at higher throughputs. To do so, apply for an exemption to the standard limits in the Google Cloud Console limits menu. In addition, an outstanding Node.js memory bug prevented us from collecting throughput results from 9MB message sizes. Here’s a look at throughput results on 16-CPU machines:
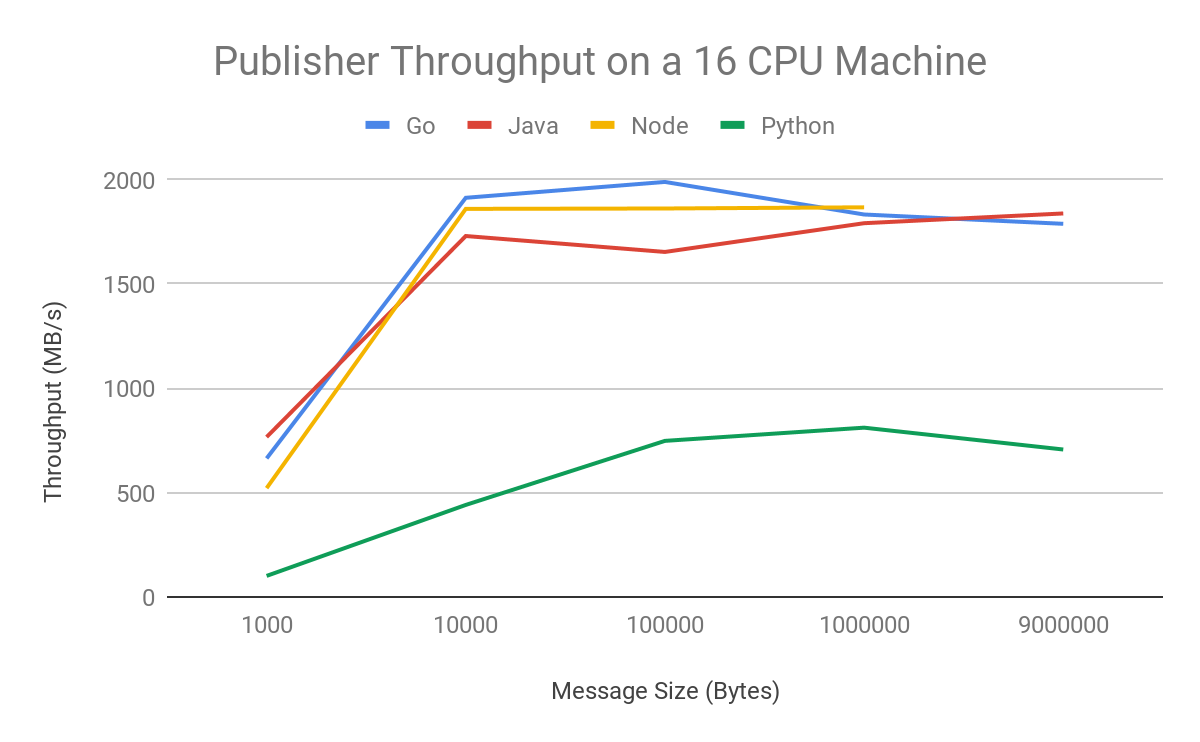
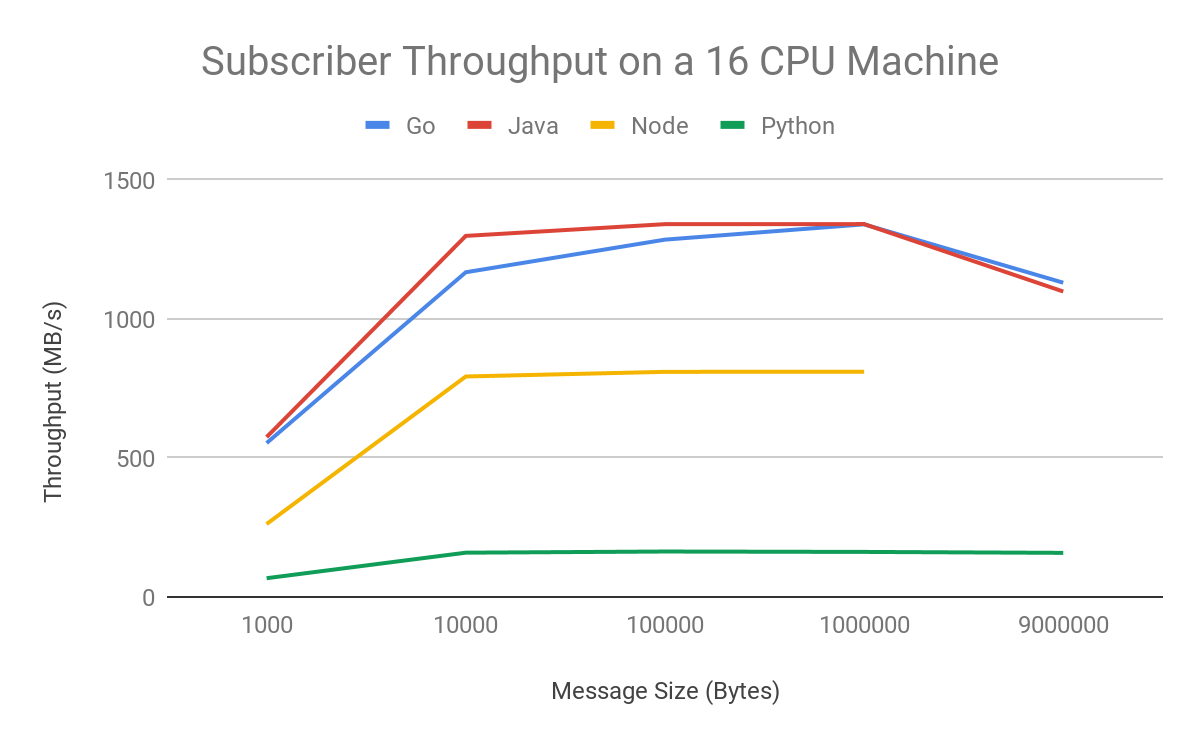
The Cloud Pub/Sub client libraries are set up to be useful out of the box for the vast majority of use cases. If you want to maximize throughput, you can easily modify the batching and flow control settings in Go, Java and C# to achieve throughput that vertically scales with machine size. There are language limitations on pursuing a shared memory threading model, so you should scale purely horizontally to more machines if that is feasible in order to reach maximum throughput while using Python or Node.js. It can be hard to get single client instances to scale beyond one core.
Try Compute Engine for horizontal autoscaling for this purpose, or Cloud Functions to deploy clients in a fully managed way. Learn more about Cloud Pub/Sub here.

