Get your BigQuery production sample, all self-serving
Gustavo Kuhn Andriotti
Strategic Cloud Engineer, Google Cloud
We are proposing a solution for the problem of getting fresh PROD samples from BigQuery. The solution also provides safety measures to avoid accidental data exfiltration, and at the same time, it’s self-serving. You get a fresh sample every day. No more outdated schemas or stale samples.
If this got your attention, chances are, you are a data scientist and working with BigQuery, or you are on the DevOps side and have to provide these samples manually. Either way, this might be the aspirin you are looking for.
Why it matters
Giving speed to data scientists is one of the single most important improvements that gives your product an edge. Imagine a solution where a data scientist can self-serve samples, and figure out insights. Then voilà, a new hypothesis and model are generated, and you can move fast to production and "bad" surprises are avoided, like biased samples or outdated data schemas.
Do you have the code?
Yes we do. You can check it out in our GitHub repository.
I heard this before
We aren't promising to solve all of your problems, but we are solving for BigQuery. The sampling is compliant and self serving. Compliant means that there is a policy in place to approve a sample request.
Can you show me?
Figure 1 is a system context diagram that shows a 10,000-foot view of the sampler system. See the image at full resolution here.
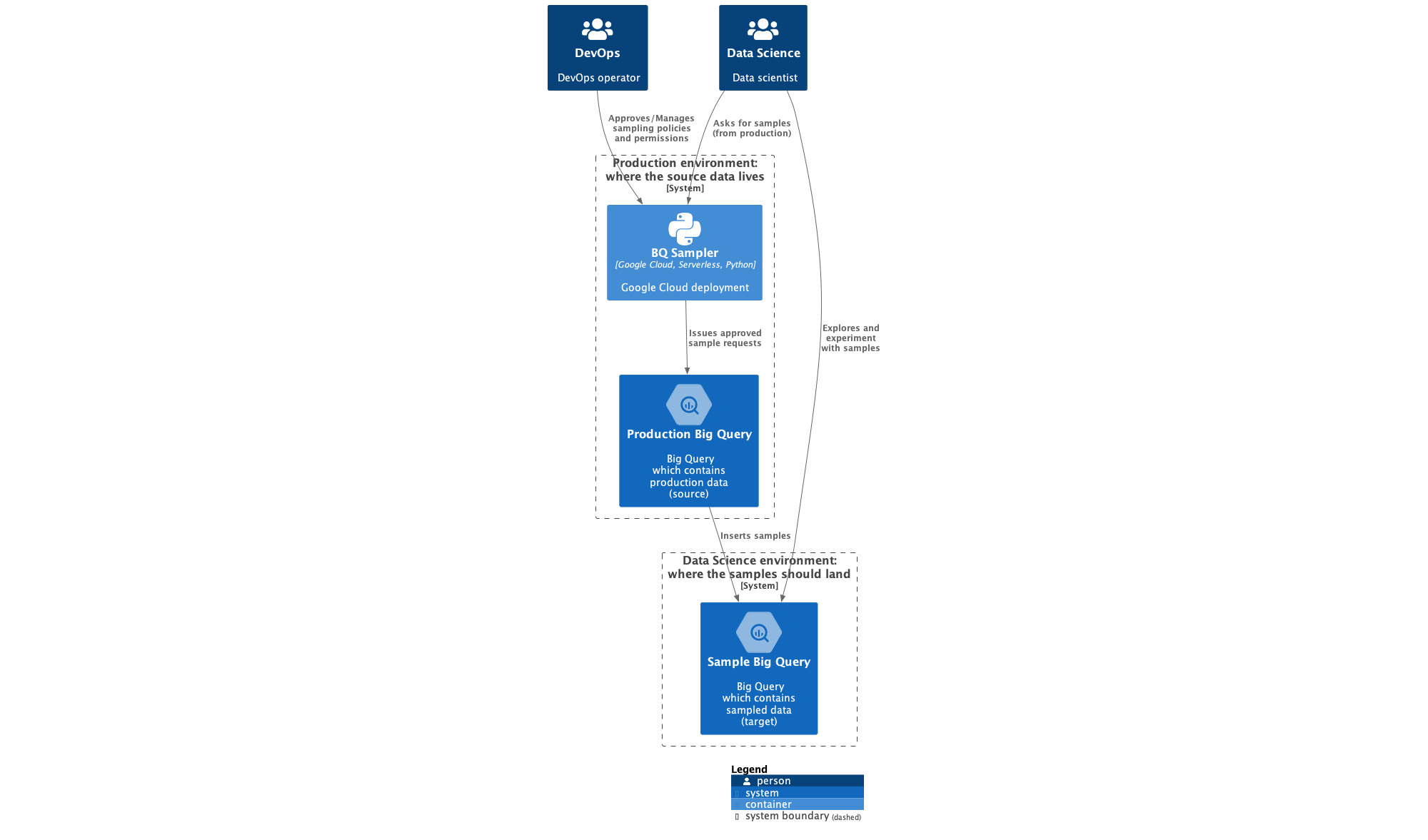
The system context diagram in Figure 1 shows two roles interacting with the sampler (BQ Sampler). The two roles are the DevOps operator and the data scientist. The Devops operator is part of the DevOps team, which includes SecOps. DevOps manages the access to the production data. The Data Science team requests samples.
When the DevOps operator or data scientist interacts with the BQ Sampler, the sampler issues approved sampler requests to the Production BigQuery, which inserts samples into the Data Science environment (Sample BigQuery).
DevOps
DevOps, including SecOps, includes the people that oversee how production data is handled.
The DevOps team has the following responsibilities:
Creates and manages policies that ensure sample requests are compliant. Questions answered by the policies include:
How many rows or what percentage of data can I get from a table?
Can I sample the table?
Which is the default sample?
Deploys and manages access to BigQuery by the sampler.
Receives and reacts to failures in the sampler.
For example, if you need a new table for samples, reach out to a person on the DevOps team.
Data science
The data science team includes the users. They request and analyze data in search of new insights. They understand what is in the data.
The data science team is responsible for the following:
Helping DevOps shape policies that are reasonable. For instance, explaining that a table contains all types of aircrafts isn’t sensitive and should be allowed to be dumped, that is, 100% of the data should be transferred to the data science environment.
Creating sample requests, such as:
I want N rows or P percent of table T.
I want a random sample or sort the sample by a particular column.
Playing with data, getting insights, creating hypotheses, and just having fun.
Removing requests that are no longer used to save BigQuery costs.
The user is you, the target audience. Your touch point with the solution is to help DevOps to develop the policies and to ask for samples that you need.
Going deep
From the user, that is, the data scientist’s perspective, there is no magic. Ask for what you want, and receive what you are allowed to have.
The steps include the following:
Ask for what you want as a scientist.
Get your request approved by the sampler using policies.
Receive the data in your own environment.
Repeat that every day.
The steps are summarized as follows:
Create your request.
Wait for the next sampler run.
Get your sample.
High-level infrastructure
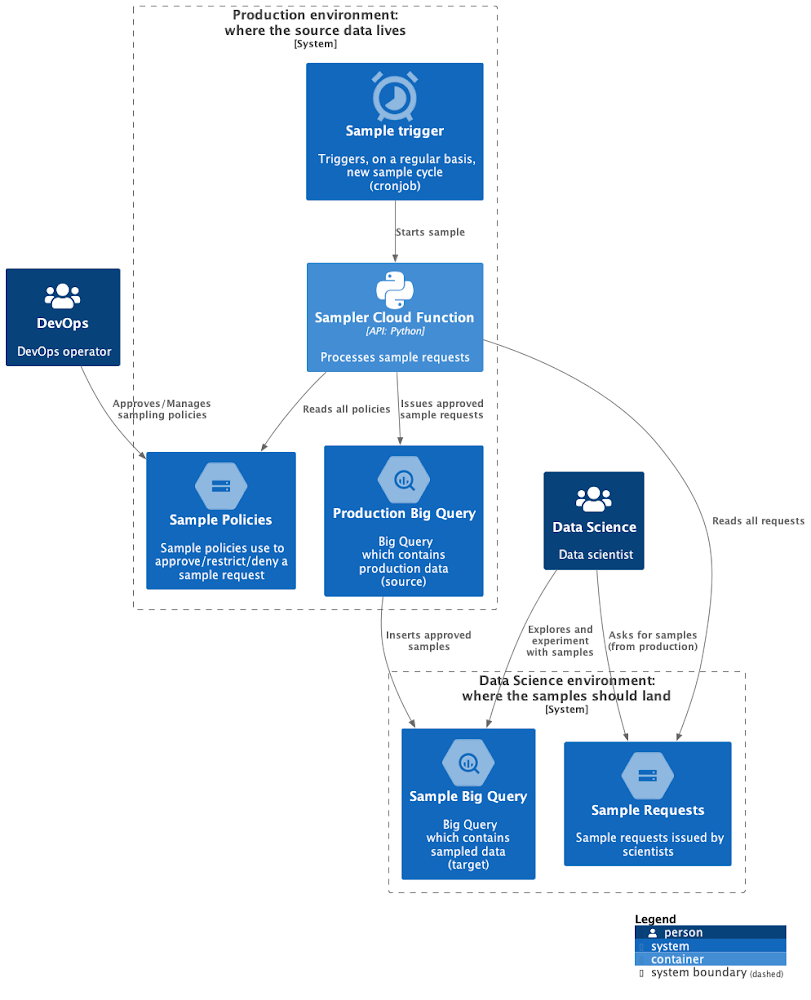
Within the sampler, the process is automated in the following manner:
The Cloud Scheduler triggers the SamplerCloud Function each day.
The Cloud Function reads requests and policies from Cloud Storage. Then the Cloud Function processes the BigQuery samples from production and sends them to the Data Science environment. The main components, shown in Figure 2, that implement the solution include:
Cloud Scheduler: Triggers the sampling cycle in the cadence that you want.
Cloud Function: Hosts the code that does the sampling.
Cloud Storage: A repository for requests and policies. The first is in the Data Science environment, which sends them to the Production environment.
BigQuery: The engine that generates the source of data and becomes the destination for samples. The source is the Production environment, and the target is the Data Science environment.
The detailed infrastructure
In Figure 3, the Components diagram, we expose the entire infrastructure. First thing to keep in mind is that despite the multiple PubSub topics and Cloud Functions, these components are in fact a single topic and function.
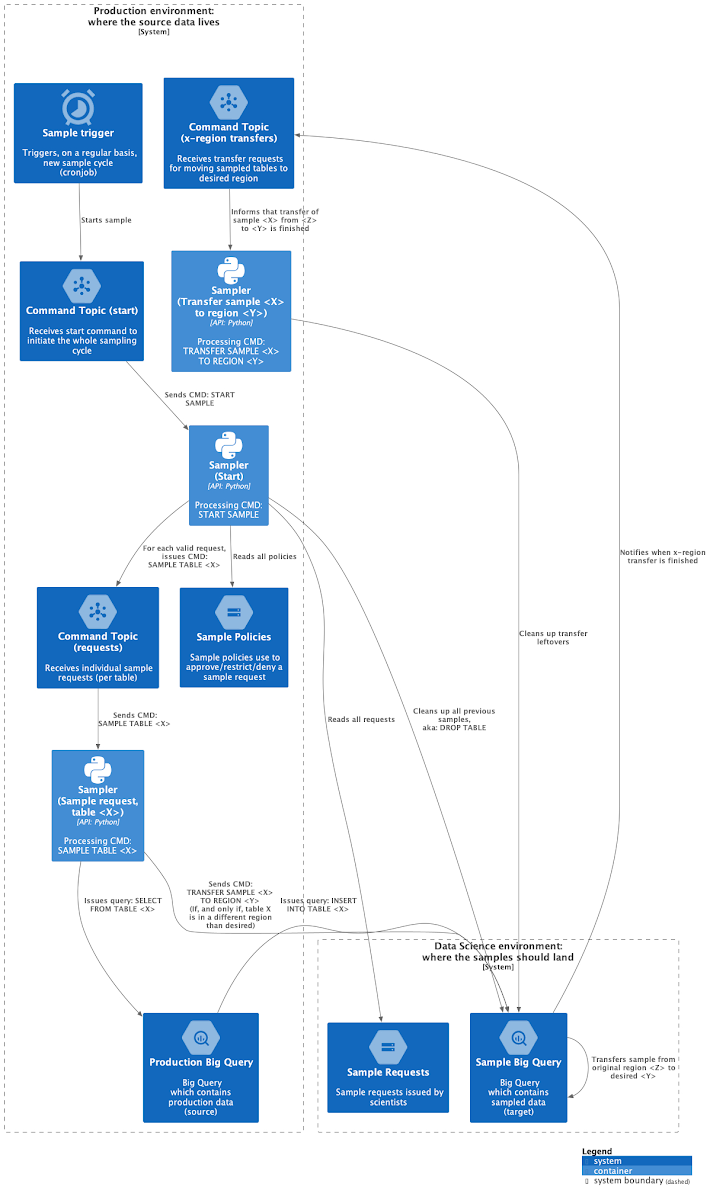
We show the components to make the logical steps clear, which include:
Start sample: It tells the sampler to start a full sampling cycle.
Clean up: Drop all previous samples.
Sample table X: Run the approved sample request for table X.
Transfer clean up: Clean up artifacts left by a cross-region table transfer.
A couple of things might puzzle you.
Why PubSub?
PubSub lets us make the Cloud Function stateless and parallel. Each logical step is triggered by a PubSub message, and you can trigger a sample for each table at the same time by sending as many messages as there are tables to be sampled. Since the function is stateless, the parallelization is trivial.
Why clean-up?
There are two problems that the cleanup step solves – schema changes and sample inflation.
Schema changes
Scenario: We keep old samples and the original table has a new schema.
Issue: We would have to deal with data migration from one schema to another. This is hardly something you can do automatically. Therefore, we would have to push that migration onto you. The simplest solution is to wipe the previous sample and table, and then manually recreate the tables in the sampling step.
Sample inflation
Assume the data isn't wiped before each sample. This causes you to steadily increase your sample size beyond what is allowed by the policy. This happens because the sampler is unaware of the previous sample. Also, getting a fresh sample better reflects the current data. For example, imagine that you have an app, and you are sampling the user’s age. It is likely that your initial customer base is young and trying out your app. As you gain traction, it is likely that other age groups will start using the app. If you don't refresh your sample, it is likely that it is very skewed towards the younger demographic.
Transfer cleanup
Transfer refers to the BigQuery data transfer service. Because BigQuery only allows cross-project table queries within the same region, we need the ability to transfer data to different regions.
Recall that we can't change the landing region in a query. The query needs to be in the same region. Imagine that PROD data is europe-west3, but data scientists want to try a new feature in Vertex AI, which is only available in us-east1.
Therefore, to have the sample in the same region as the new feature, we have to use BigQuery data transfer service. Remember, a sample can only happen in the same region as the original data. This means that we first sample it in the exact same region with the PROD, europe-west3. Then we use the data transfer service to copy the sample from europe-west3 to us-east1. This leaves some artifacts behind to be cleaned up. The transfer cleanup step does exactly that, removes leftover artifacts.
What's next?
Stay tuned for a deeper technical discussion on this solution in an upcoming blog post. For now, you can go to the GitHub repository, and try it out for yourself. We love feedback and bug reports, so if you find an issue, let us know.
Solution design
We settled around a very simple solution that has the following components:
BigQuery: The source and destination of data.
Cloud Scheduler: Our crontab to trigger the sampling on a daily or regular basis.
Cloud Pub/Sub: Coordinates the triggering, errors, and sampling steps.
Cloud Storage: Stores the policies and requests (two different buckets).
Cloud Functions: Our workhorse for logic.
Secret Manager: Keeps sensitive information.
Cloud Monitoring: Monitors the health of the system.
The people involved
We owe a big "thank you" to the OPSD project team from SWISS and Lufthansa Group. This post came from a real necessity within the project to have fresh PROD samples and to be compliant with SecOps. We want to especially thank Federica Lionetto for co-writing this post, Yaroslav Khanko for reviewing the security aspects, Ziemowit Kupracz for the terraform code review, and Regula Gantenbein for the CI/CD integration.



{kind=link}
{kind=link}