Simplify data processing and data science jobs with Serverless Spark, now available on Google Cloud
Abhishek Kashyap
Sr. Product Manager, Google Cloud
Marek Wolczanski
Data Platform Engineer, OpenX
Most businesses today choose Apache Spark for their data engineering, data exploration and machine learning use cases because of its speed, simplicity and programming language flexibility. However, managing clusters and tuning infrastructure have been highly inefficient, and a lack of an integrated experience for different use cases are draining productivity gains, opening up governance risks and reducing the potential value that businesses could achieve with Spark.
Today, we are announcing the general availability of Serverless Spark, industry's first autoscaling serverless Spark. We are also announcing the private preview of Spark through BigQuery, empowering BigQuery users to use serverless Spark for their data analytics, along with BigQuery SQL. With these, you can effortlessly power ETL, data science, and data analytics use cases at scale.
Dataproc Serverless for Spark (GA)
Per IDC, developers spend 40% time writing code, and 60% of the time tuning infrastructure and managing clusters. Furthermore, not all Spark developers are infrastructure experts, resulting in higher costs and productivity impact.
Serverless Spark, now in GA, solves for these by providing the following benefits:
Developers can focus on code and logic. They do not need to manage clusters or tune infrastructure. They submit Spark jobs from their interface of choice, and processing is auto-scaled to match the needs of the job.
Data engineering teams do not need to manage and monitor infrastructure for their end users. They are freed up to work on higher value data engineering functions.
Pay only for the job duration, vs paying for infrastructure time.
How OpenX is using Serverless Spark: From heavy cluster management to Serverless
OpenX, the largest independent ad exchange network for publishers and demand partners, was in the process of migrating an old MapReduce pipeline. The previous MapReduce cluster was shared among multiple jobs, which required frequent cluster size updates, autoscaler management and also, from time to time, cluster recreation due to upgrades as well as other unrecoverable reasons.
OpenX used Google Cloud’s serverless Spark to abstract away all the cluster resources and just focus on the job itself. This significantly helped to boost the team’s productivity, while reducing infrastructure costs. It turned out that for OpenX, serverless Spark is cheaper from the resource perspective, not to mention maintenance costs of a cluster lifecycle management.
During implementation, OpenX first evaluated the existing pipeline characteristics. It’s hourly batch workload with input size varies from 1.7 TB to 2.8 TB compressed Avro per hour. The pipelines were run on the shared cluster along with other jobs and do not require data shuffling.

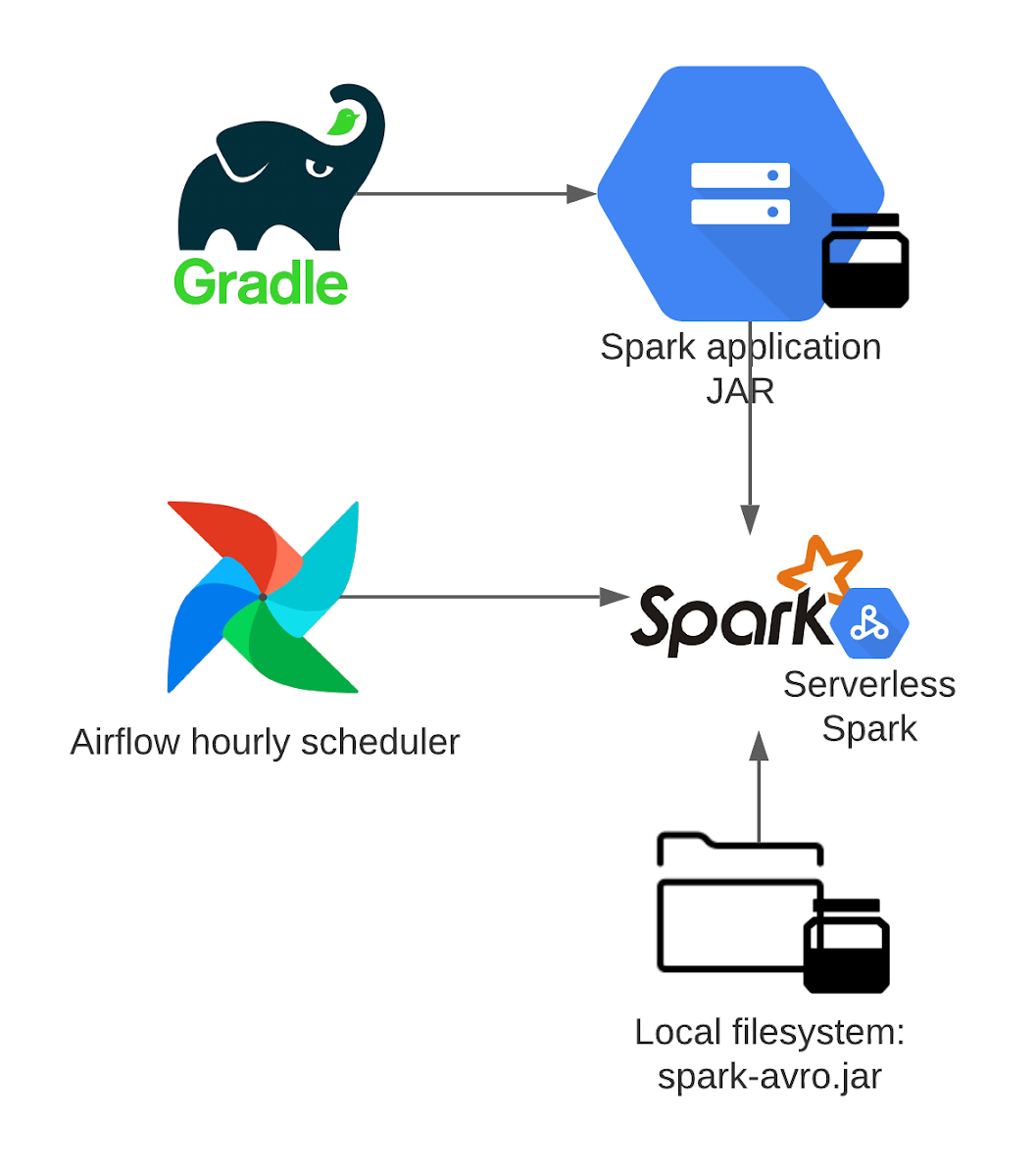
To set up the flow, Airflow Kubernetes worker is assigned to a workload identity, which submits a job to the Dataproc serverless batch service using Airflow's plugin DataprocCreateBatchOperator. The batch job itself is assigned to a tailored service account and Spark application jar is released to the Google Cloud Storage using gradle plugin as Dataproc batches can load a jar directly from there. Another job dependency (Spark-Avro) is loaded from the driver or worker filesystem. The batch job is then started with the initial size of 100 executors (1vCPU + 4GB RAM) and autoscaler adds resources as needed, as the hourly data sizes vary during the day.
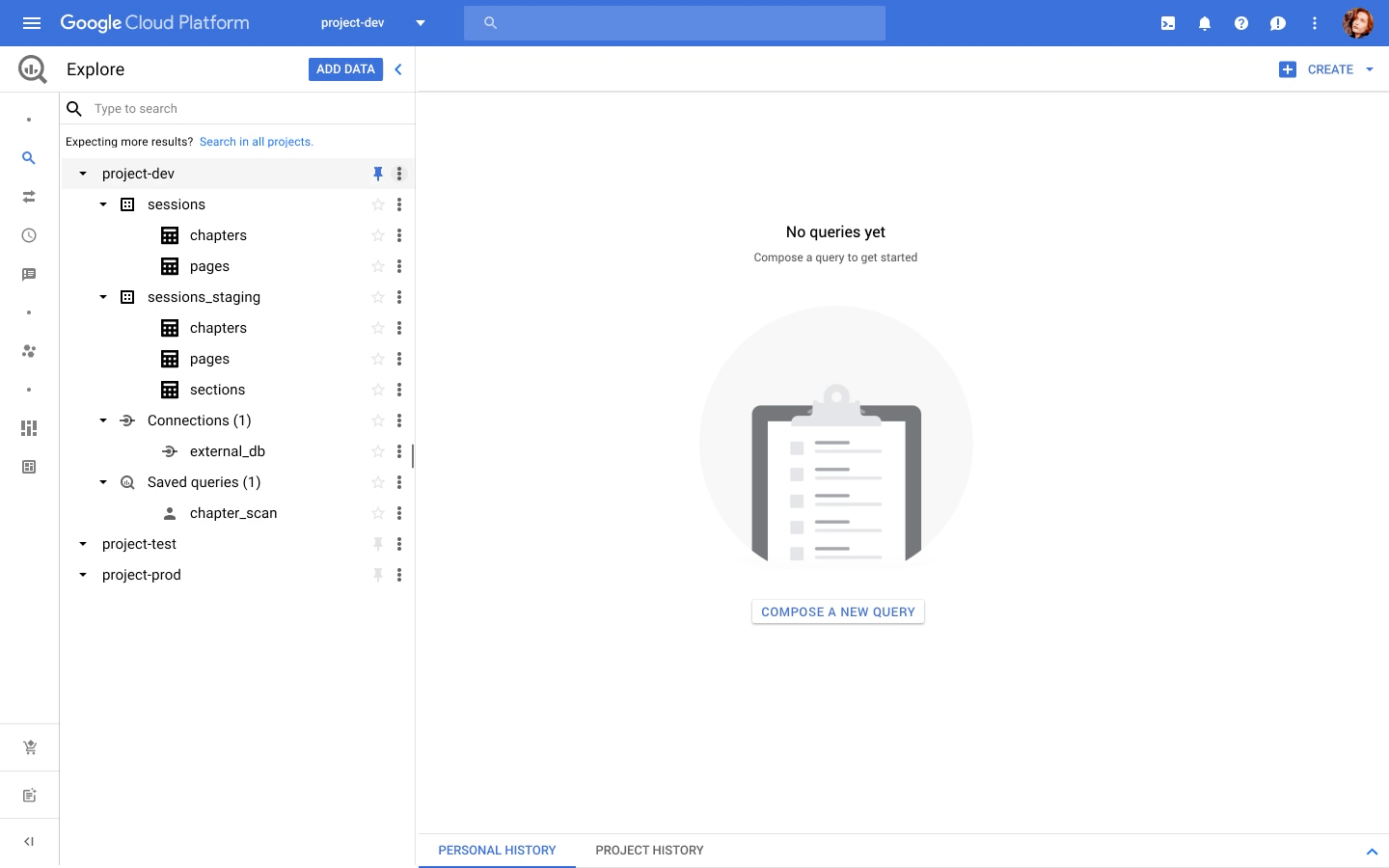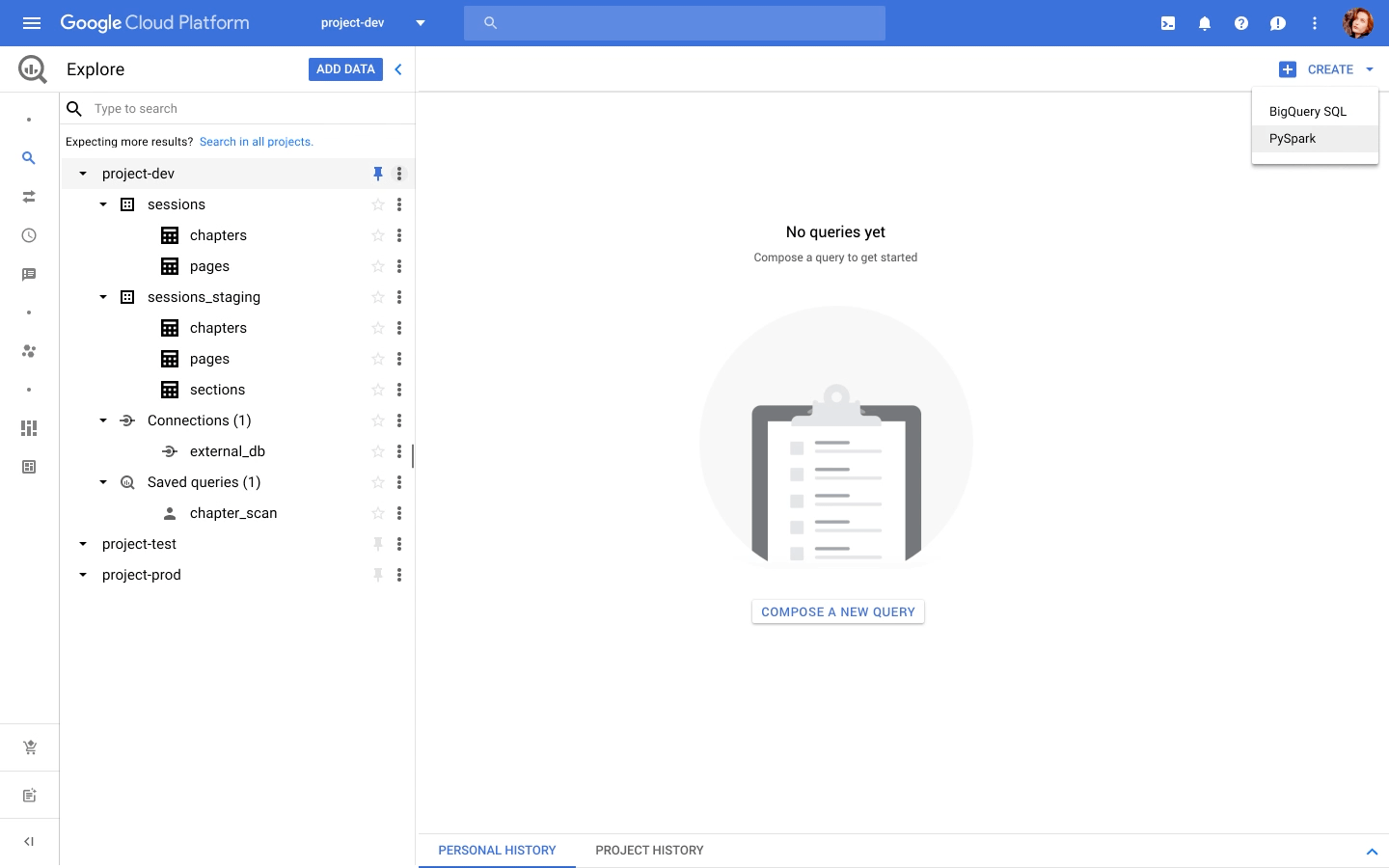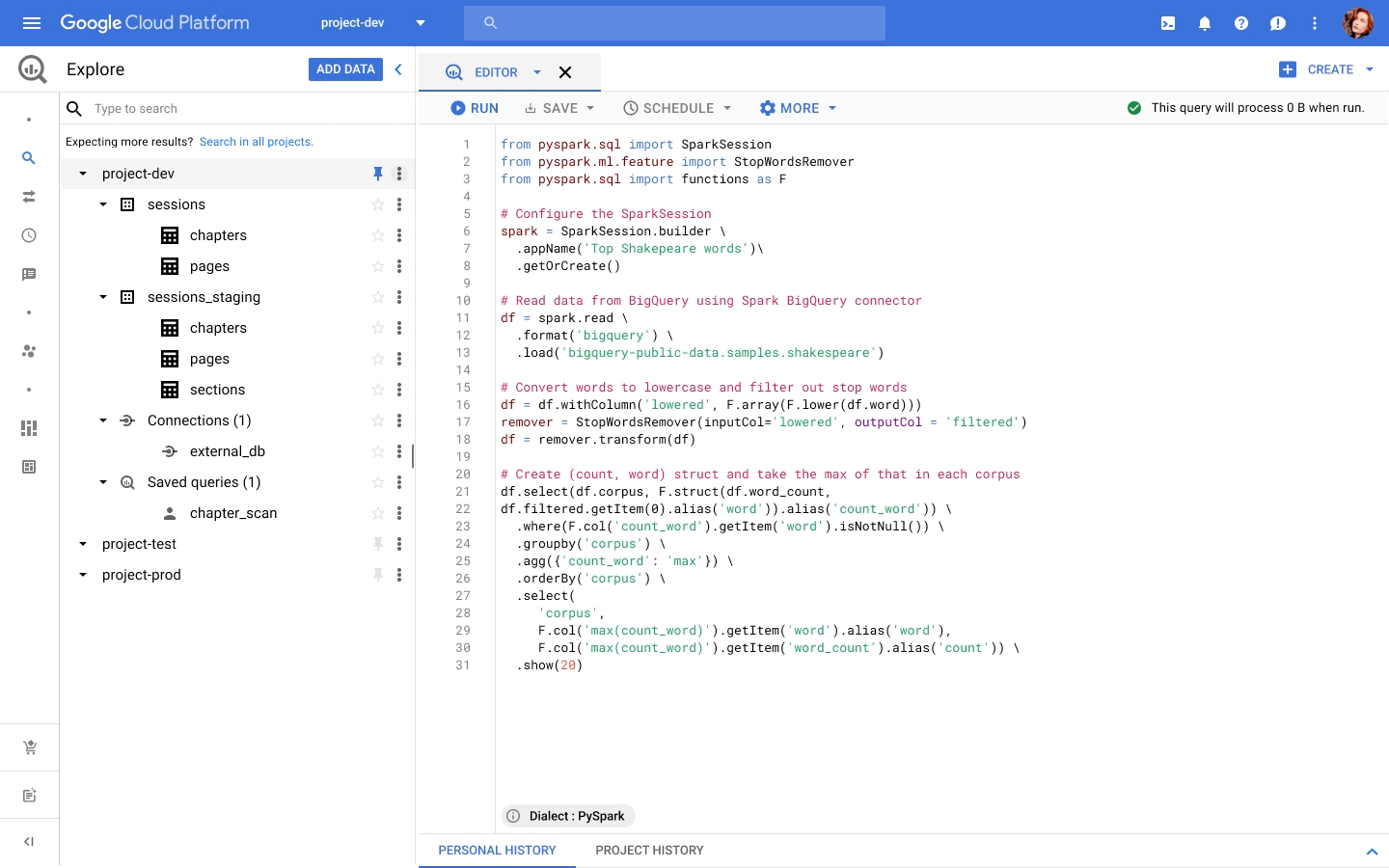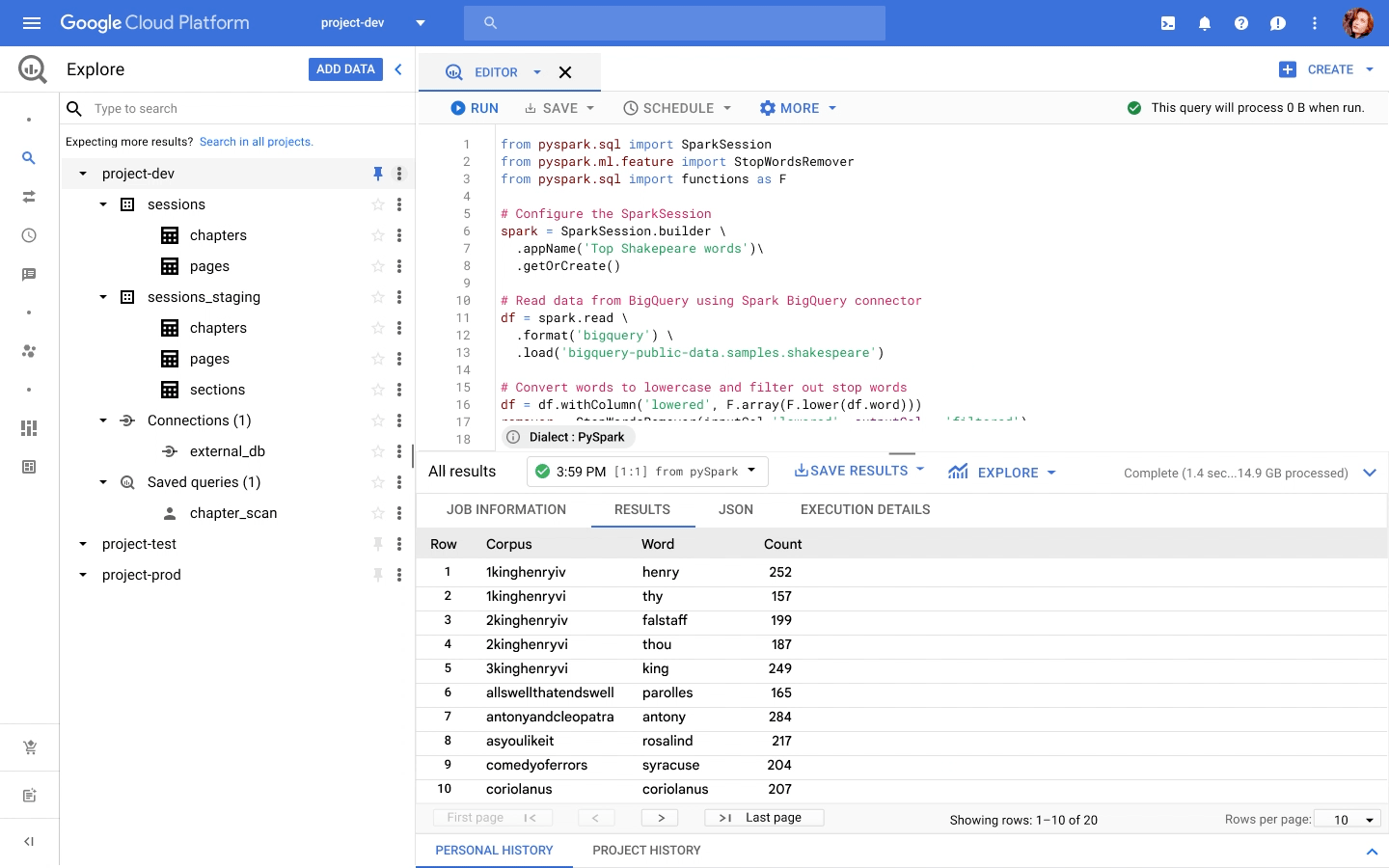
Serverless Spark through BigQuery (Preview)
We announced at NEXT that BigQuery is adding a unified interface for data analysts to write SQL or PySpark. That Preview is now live, and you can request access through the signup form.
You can write PySpark code in the BigQuery editor, and the code is executed using serverless Spark seamlessly, without the need for infrastructure provisioning. BigQuery has been the pioneer for serverless data warehousing, and now supports serverless Spark for Spark-based analytics.
What’s next?
We are working on integrating serverless Spark with the interfaces different users use, for enabling Spark without any upfront infrastructure provisioning. Watch for the availability of serverless Spark through Vertex AI workbench for data scientists, and Dataplex for data analysts, in the coming months. You can use the same signup form to express interest.
Getting started with Serverless Spark and Spark through BigQuery today
You can try serverless Spark using this tutorial, or use one of templates for common ETL tasks. To sign up for Spark through BigQuery preview, please use this form.



