Simplified data transformations for machine learning in BigQuery
Lak Lakshmanan
Director, Analytics & AI Solutions
Building machine learning models on structured data commonly requires a large number of data transformations in order to be successful. Furthermore, those transformations also need to be applied at the time of predictions, usually by a different data engineering team than the data science team that trained those models. Keeping the set of transformations consistent between training and inference can be quite hard because of differences in toolsets between the two teams. We’re announcing some new features in BigQuery ML that can help preprocess and transform the data with simple SQL functions. In addition, because BigQuery automatically applies these transformations at the time of predictions, the productionization of ML models is greatly simplified.
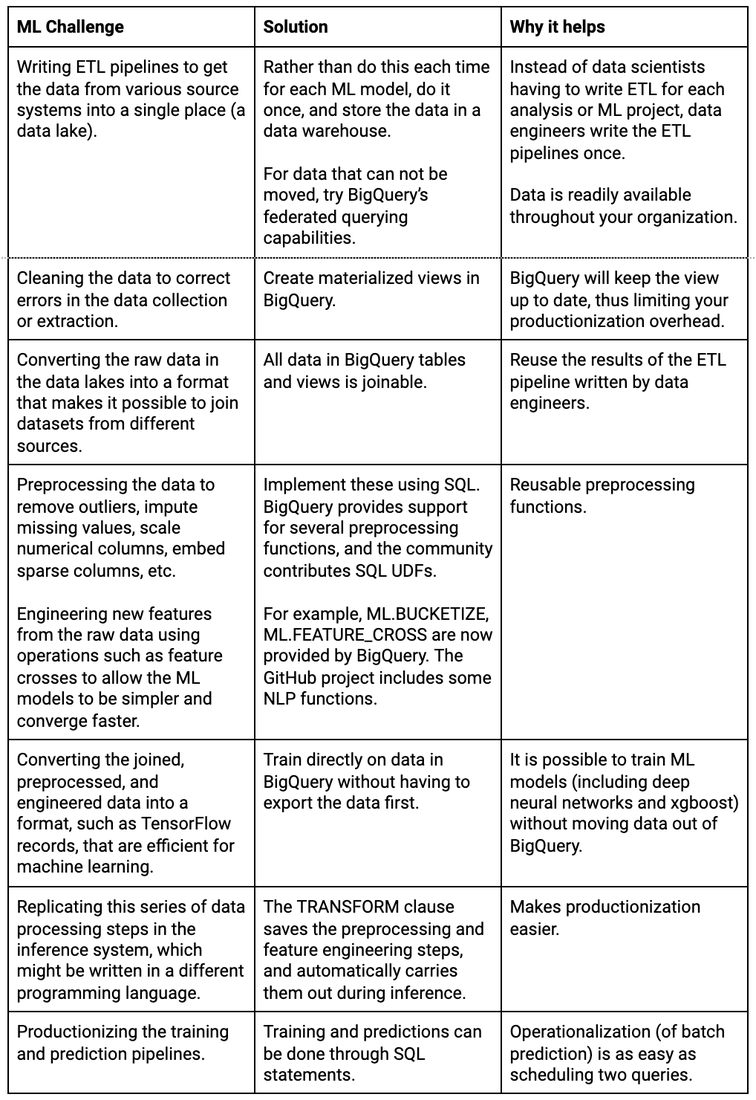
In a 2003 book on exploratory data mining, Dasu and Johnson observed that 80% of data analysis is spent on cleaning the data. This hasn’t changed with machine learning. Here at Google Cloud, we often observe that in our machine learning projects, a vast majority of the time is spent getting the data ready for machine learning. This includes tasks such as:
Writing ETL pipelines to get the data from various source systems into a single place (a data lake)
Cleaning the data to correct errors in the data collection or extraction
Converting the raw data in the data lakes into a format that makes it possible to join datasets from different sources
Preprocessing the data to remove outliers, impute missing values, scale numerical columns, embed sparse columns, and more
Engineering new features from the raw data using operations such as feature crosses to allow the ML models to be simpler and converge faster
Converting the joined, preprocessed, and engineered data into a format, such as TensorFlow Records, that’s efficient for machine learning
Replicating this series of data processing steps in the inference system, which might be written in a different programming language
Productionizing the training and prediction pipelines
Taking advantage of a data warehouse with built-in machine learning
A large part of machine learning projects consists of data wrangling and moving data around. Instead of writing custom ETL pipelines for each project to move data into a data lake, and task every ML project with having to understand the data and convert it into a joinable form, we recommend that organizations build an enterprise data warehouse (EDW). If the EDW is cloud-based and offers separation of compute and storage (like BigQuery does), any business unit or even external partner can access this data without having to move any data around. All that’s needed to access the data is an appropriate Identity and Access Management (IAM) role.
With this type of EDW, data engineering teams can write the ETL pipelines once to capture changes in source systems and flush them to the data warehouse, rather than machine learning teams having to code them piecemeal. Data scientists can focus on gaining insights from the data, rather than on converting data from one format to another. And if the EDW provides machine learning capabilities and integration with a powerful ML infrastructure such as AI Platform, you can avoid moving data entirely. On Google Cloud, when you train a deep neural network model in BigQuery ML, the actual training is carried out in AI Platform—the linkage is seamless.
For example, to train a machine learning model on a dataset of New York taxicab rides to predict the fare, all we need is a SQL query (see this earlier blog post for more details):
Productionizing with scheduled queries
Once the model has been trained, we can determine the fare for a specific ride by providing the pickup and dropoff points:
This returns:

If you use a cloud-based, modern EDW like BigQuery that provides machine learning capabilities, much of the pain associated with data movement goes away. Note how the query above is able to train an ML model simply off a SELECT statement. This takes care of the first three pain points we identified at the beginning of this article. Productionizing the training of the ML model and carrying out batch predictions is as simple as scheduling the above two SQL queries, thus greatly reducing the pain point associated with productionization.
The BigQuery ML preprocessing and transformation features we’re announcing today address the rest of the obstacles, allowing you to carry out data munging effectively, train machine learning models quickly, and carry out predictions without fear of training-serving skew.
Preprocessing in BigQuery ML
A data warehouse stores the raw data in a way that is applicable to a wide variety of data analysis tasks. For example, dashboards commonly depict data in the data warehouse, and data analysts commonly carry out ad hoc queries. However, a common requirement when training machine learning models is to not train on the raw data, but to filter out outliers, and carry out operations such as bucketizing and scaling in order to improve trainability and convergence.
Filtering can be carried out in SQL using a WHERE clause, like this:
Once we determine the operations necessary to clean and correct the data, it is possible to create a materialized view:
Because materialized views are currently in alpha in BigQuery, you might choose to use a logical view or export the data to a new table instead. The advantage of using a materialized view in the ML context is that you can offload the problem of keeping the data up to date in BigQuery. As new rows are added to the original table, cleaned-up rows will appear in the materialized view.
Similarly, scaling can be implemented in SQL. For example, this code does a zero-norm of the four input fields:
It is possible to store these scaled data in the materialized view, but because the mean/variance will change over time, we do not recommend doing this. The scaling operation is an example of ML preprocessing operations that require an analysis pass (here, to determine the mean and variance). Because the results of the analysis pass will change as new data is added, it is better to perform preprocessing operations that require an analysis pass as part of your ML training query. Note also that we are taking advantage of convenience UDFs defined in a community GitHub repository.
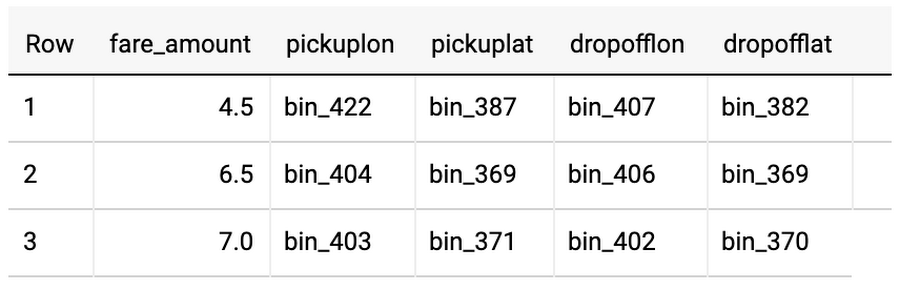
BigQuery provides out-of-the-box support for several common machine learning operations that do not require a separate analysis pass through the data. For example, here’s an example of bucketizing the inputs, knowing the latitude and longitude boundaries of New York:
Note that now the fields are categorical and correspond to the bin that the pickup and dropoff points correspond to:
Limiting training-serving skew using TRANSFORM
The problem with training a model as shown above is that productionization becomes quite hard. It is no longer as simple as sending the latitudes and longitudes to the model. Instead, we also have to remember and replicate the preprocessing steps in the prediction pipeline:
This is why we’re announcing support for the TRANSFORM keyword. Put all your preprocessing operations in a special TRANSFORM clause, and BigQuery ML will automatically carry out the same preprocessing operations during prediction. This helps you limit training-serving skew.
The following example shows computing GIS quantities, carrying out the extraction of features from a timestamp, doing a feature cross, and even concatenating the various pickup and dropoff bins (very complex preprocessing, in other words):
The prediction code remains very straightforward and simple and does not have to replicate any of the preprocessing steps:
Enjoy these new features!
Get started:
Find a list of preprocessing functions in the documentation.
The queries in this post can be found in these two notebooks on GitHub. Try them out from an AI Platform notebook or from Colab.
To learn more about BigQuery ML, try this quest in Qwiklabs.
Check out chapter 9 of BigQuery: The Definitive Guide for a thorough introduction to machine learning in BigQuery.



