Get your BigQuery production sample, all self-serving
Gustavo Kuhn Andriotti
Strategic Cloud Engineer, Google Cloud
A recap from part 1: We are proposing a solution for the problem of getting fresh PROD samples from BigQuery. The solution also provides safety measures to avoid accidental data exfiltration, and at the same time, it’s self-serving. You get a fresh sample every day. No more outdated schemas or stale samples.
If you want more info on how, when and why you should get BigQuery samples from your production environment, you can read our first post on the topic (code here).
How it works, the details
Wondering if this method will work for you, and if this solution is in line with your organization's security policy? We are here to tell you that this is for you.
Assumptions
We assume that DevOps isn't interested in preparing the samples themselves and it is better to let data scientists self serve. First because it isn't DevOps responsibility to infer about data, which is where data scientists are the subject matter experts.
I am from DevOps
In this case, we assume you want to assess only once whether you have data access to a particular table in production. We also assume that you don't want to manually intermediate every sample request. This means that you can encode your assessment in a simple JSON file that we call a policy.
Policies
In the following JSON example, there are two sections, limit and default_sample:
-
limit: Defines the maximum amount of data you can get out of a table. You can specify the
count,percentage, or both. In case you specify both, the percentage is converted to a count and the minimum amount between thepercentage(converted to count) and thecountis used. -
default_sample: Used in case the request either doesn't exist or is "faulty" like a non-JSON or an empty file.
Example:
I am a data scientist
We assume that you as a data scientist want to figure out if you have access to data in production. Once you have access, you will request different samples whenever you need them. When you wake up the next day, your samples will be ready for you. Sounds fair? Let us look at the request format.
Requests
A request has the same structure as the default_sample entry in the policy, where:
-
size: Specifies how much of the table data is desired. You can specify the
count,percentage, or both. In case you specify both,the maximum amount between thecountand thepercentage(converted to a count) is used as the actual value. -
spec: Specifies how to sample production data by providing the following:
-
type: Either
sortedorrandom. -
properties: If
sorted, specify by which column to use for sorting and the sorting direction: -
by: Column name.
-
direction: Sorting direction (either
ASCorDESC).
Example:
We are confused, please elaborate
Let us get a bit more concrete and go over an example. This will help you to understand what a limit and size are. They seem similar but aren't the same.
Limit is not size
There is a subtle but important semantic distinction on how limit differs from size. In the policy, you have a limit,which uses the minimum between count and percentage. The limit is used to restrict the amount of data given. The size is used for requests and default sampling. It uses the maximum between count and percentage. The size must not go beyond the limit.
Let us use an example to show how it works
The table in this scenario has 50,000 rows.
Then it follows:
In this case, the sample size has a limit of 5,000 rows, which is 10% of 50,000 rows.
Sampling cycle
In Figure 4, you have the flow of a data sampling that ignores infrastructure:
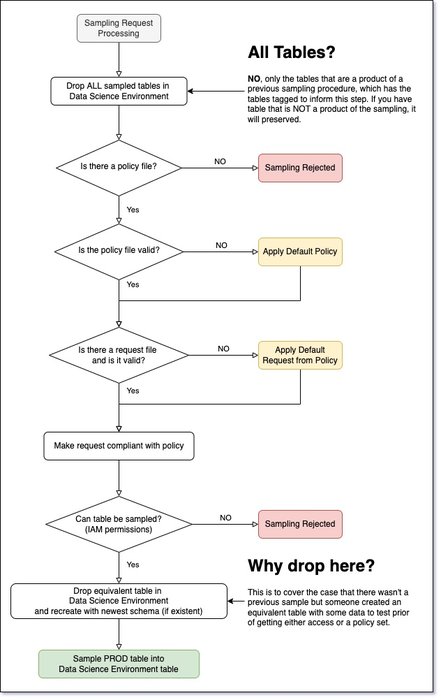
Figure 4. Sampling flow. See the image at full resolution here.
Figure 4 might seem like overkill, but it isn’t. We need to make sure that:
-
Sample inflation doesn’t happen, i.e., your sample should not grow with each sampling cycle. Meaning, policies must be respected.
-
You must be tolerant of faulty requests.
-
Keep the schemas in sync with production.
In detail, the sampler has the following flow:
-
Cloud Scheduler puts a message
STARTinto theCOMMANDPubSub topic. It tells the sampler function to start the sampling. -
The sampler function will do the following:
-
Remove all previous samples in the Data Science environment.
-
List all available policies in the policy bucket.
-
For each table it finds, send a
SAMPLE_STARTcommand with the corresponding policy. -
For each
SAMPLE_STARTcommand, it checks if there is a corresponding request file. They are in the request bucket. -
The request is checked against the policy.
-
A compliant sampling is issued to the BigQuery source. It is inserted in the corresponding table in the Data Science Environment.
-
Each error the sampler function finds, it reports into the
ERRORPubSub topic. -
The error function is triggered by any message in this topic. It sends an email informing about the error.
-
Assume that the sampler function isn't executed within 24h. Then it triggers an alert that is sent to the
ERRORPubSub topic. -
If there is a "catastrophic" error in either the sampling or error functions, it sends an email alert.
Limitations
We are going to address each point in detail in the following sections. For reference, here is a short rundown of things we aren't supporting:
-
JOINs of any kind -
WHEREclauses -
Auto-obfuscation (the data is auto-anonymized before inserting the sample)
-
Column exclusion
-
Row exclusion
-
Correct uniform sampling distribution
-
Non-uniform data sampling distributions (such as Gaussian, Power, and Pareto)
Wait, some seem pretty straightforward, why not "future work"?
We are going to "explain ourselves". The "NOT"s do fall, mostly, in one of the categories:
-
It is too complex and time consuming to implement.
-
You can use views.
-
It would be too expensive for you to have it.
We address each item in the laundry list in the sections that follow.
JOINs and WHEREs, really?
Unfortunately, yes. The issue with JOINs and WHEREs is that they are too complex to implement to enforce a sampling policy. Here is a simple example:
-
Table
TYPE_OF_AIRCRAFT, which is a simple ID for a specific aircraft, for example, Airbus A320 neo has IDABC123. -
100% of the data is sampled, that is you can copy the table.
-
Table
FLIGHT_LEG, which is a single flight on a specific day, for example, London Heathrow to Berlin at 14:50 Sunday. -
Ten percent is sampled.
-
Table
PASSENGER_FLIGHT_LEGprovides which passenger is sitting where in a particularFLIGHT_LEG. -
Only 10 rows are allowed.
You can now construct a query that joins all of these tables together. You can ask all passengers flying in a particular aircraft type on a particular day. In this case, to honor the policies, we have to do the following:
-
Execute the query.
-
Verify how much data from each particular table is being pulled through it.
-
Start capping based on the "allowances".
This process will be:
-
Probably very expensive for you. Therefore, we will execute and then "trim" (you are paying for the full query).
-
Can have many edge cases that violate the policies.
-
Risk of data exfiltration.
But I need to obfuscate data, please
A lot of people do need obfuscation, we know. This topic alone is addressed by Cloud DLP. There are also many (more) capable solutions in the market that you can use for it. See the blog post: Take charge of your data: using Cloud DLP to de-identify and obfuscate sensitive information.
Column and row exclusion sounds simple
We agree that column and row exclusions are simple, and it is even easier (and safer) to deal with using views or Cloud DLP. The reason we don't do it here is because it is a difficult use case to create a generic specification that works for all use cases. Also, there are much better approaches like Cloud DLP. It all depends on the reason why you want to drop columns or rows.
Wait, is it not really uniform either?
Except for views, we rely on TABLESAMPLE statements. The reason is cost. A truly random sample means using the ORDER BY RAND() strategy, which requires a full table scan. With TABLESAMPLE statements, you are only paying a bit more than the amount of data you want. Let us go deeper.
The caveat on TABLESAMPLE statements
This technique allows us to sample a table without having to read it all. But there is a huge CAVEAT using TABLESAMPLE. It is neither truly random nor uniform. Your sample will have the bias in your table blocks. Here is how it works, according to the documentation:
The following example reads approximately 20% of the data blocks from storage and then randomly selects 10% of the rows in those blocks:
SELECT * FROM dataset.my_table TABLESAMPLE SYSTEM (20 PERCENT)
WHERE rand() < 0.1
An example is always easier. Let us build one with a lot of skewness to show what TABLESAMPLE does. Imagine that your table has a single integer column. Now picture that your blocks have the following characteristics:
At this point, we are interested in looking at what happens to the average of your sample when using TABLESAMPLE. For simplicity, assume:
-
Each block has 1,000 records. This puts the actual average of all values in the table to around 5.6.
-
You chose a 40% sample.
TABLESAMPLE will sample 40% of the blocks and you will get two blocks. Let us look at your average. Let us assume that blocks with Block ID 1 and 2 were selected. This means that your sample average is now 9.5. Even if you use the downsampling that is suggested in the documentation, you will still end up with a biased sample. Simply put, if your blocks have bias, your sample has it too.
Again, removing the potential bias means increasing the sampling costs to a full table scan.
I need other distributions, why not?
There are several reasons why not. The main reason is that other distributions aren't supported by the SQL engine. There is no workaround for the missing feature. The only way to have it is to implement it. Here is where things get complicated. Fair warning, if your stats are rusty, it is going to be rough.
All the statements below are based on the following weird property of the cumulative distribution function (CDF):
For a given distribution its CDF is continuously distributed.
Source and a lecture if you feel like it.
For it to work, you will need to do the following:
-
Get all data on the target column (which is being the target of the distribution).
-
Compute the column's CDF.
-
Randomly/uniformly sample the CDF.
-
Translate the above to a row number/ID.
-
Put the rows in the sample.
This process can be done, but has some implications, such as the following:
-
You will need a full table scan.
-
You will have to have a "beefier" instance to hold all of the data (think billions of rows), and you will have to compute the CDF.
This means that you will be paying for the following:
-
The already expensive query (full table scan).
-
Time on the expensive instance to compute the sample.
We decided it isn't worth the cost.
Views: the workaround
We do support sampling views. This means that you can always pack your "special sauce" in them and let the sampler do its job. But views don't support BigQuery's TABLESAMPLE statement. This means that random samples need a full table scan using the ORDER BY RAND() strategy. The full table scan doesn't happen on non-random samples.
Feels like you cheated
Yes, you are right, we cheated. The workaround using views pushes the liability onto SecOps and DataOps, who will need to define compliant views and sample policies. Also, it can be costly, because querying the view is like executing the underlying query and sampling it. Be very careful especially with the random samples from views due to the full table scan nature of it on views.
Solution design
We settled around a very simple solution that has the following components:
-
BigQuery: The source and destination of data.
-
Cloud Scheduler: Our crontab to trigger the sampling on a daily or regular basis.
-
Cloud Pub/Sub: Coordinates the triggering, errors, and sampling steps.
-
Cloud Storage: Stores the policies and requests (two different buckets).
-
Cloud Functions: Our workhorse for logic.
-
Secret Manager: Keeps sensitive information.
-
Cloud Monitoring: Monitors the health of the system.
Now that you know what is under the hood, let us do it: check out the code here and happy hacking.
We owe a big "thank you" to the OPSD project team from SWISS and Lufthansa Group. This post came from a real necessity within the project to have fresh PROD samples and to be compliant with SecOps. We want to especially thank Federica Lionetto for co-writing this post, Yaroslav Khanko for reviewing the security aspects, Ziemowit Kupracz for the terraform code review, and Regula Gantenbein for the CI/CD integration.



{kind=link}