Introducing Apache Spark Structured Streaming connector for Pub/Sub Lite
Michael Jiang
Software Engineer
Sameer Farooqui
Cloud Data Engineer
Today we’re excited to announce the release of an open source connector to read streams of messages from Pub/Sub Lite into Apache Spark. Pub/Sub Lite is a scalable, managed messaging service for Spark users on GCP who are looking for an exceptionally low-cost ingestion solution. The connector allows you to use Pub/Sub Lite as a replayable source for Structured Streaming’s processing engine with exactly-once guarantees1 and ~100ms processing latencies. The connector works in all Apache Spark 2.4.X distributions, including Dataproc, Databricks, or manual Spark installations.
What is Pub/Sub Lite?
Pub/Sub Lite is a recently released, horizontally scalable messaging service that lets you send and receive messages asynchronously between independent applications. Publisher applications publish messages to a Pub/Sub Lite topic, and subscriber applications (like Apache Spark) read the messages from the topic.
Pub/Sub Lite is a zonal service. While you can connect to Pub/Sub Lite from anywhere on the internet, running publisher and subscriber applications in the same zone as the topic they connect to will help minimize networking egress cost and latency.
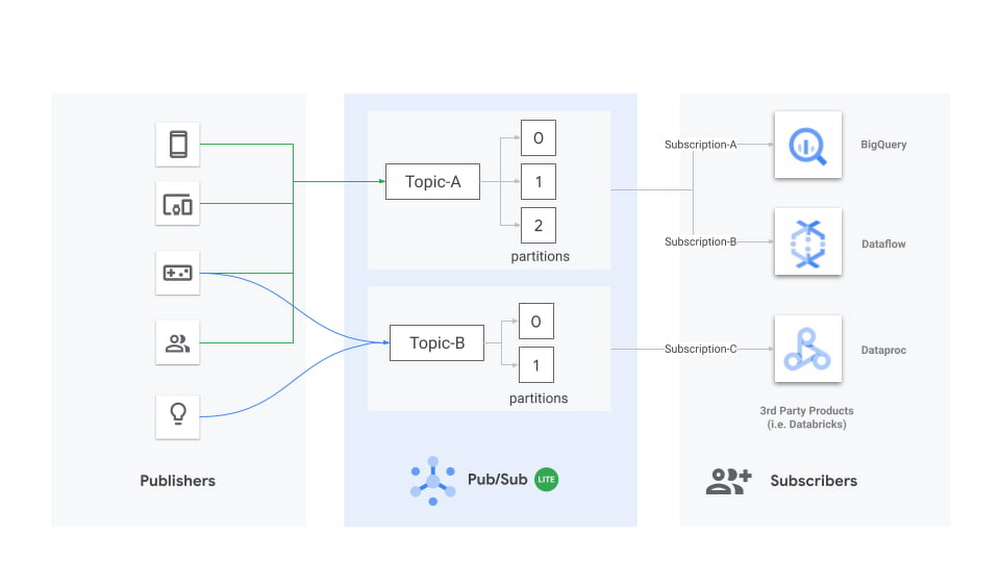
A Lite topic consists of a pre-configured number of partitions. Each partition is an append-only timestamped log of messages. Each message is an object with several fields, including message body, a user-configurable event_timestamp, and an automatically set publish_timestamp based on when Pub/Sub Lite stores the incoming message. A topic has a throughput and storage capacity that the user configures. To configure the topic capacity, you will have to consider a handful of properties, such as the number of partitions, storage/throughput capacity for each partition, and message retention period.
The Pub/Sub Lite pricing model is based on provisioned topic throughput and storage capacity. Plan to provision enough capacity to accommodate peaks in traffic; then, as your traffic changes, you can adjust the throughput and storage capacity of your topics. Pub/Sub Lite’s Monitoring metrics let you easily detect conditions when you need to increase your capacity. Start by creating alerting policies that will notify you when your backlog is growing unexpectedly: subscription/backlog_quota_bytes should be comfortably lower than topic/storage_quota_byte_limit. If a subscription exceeds the storage capacity, the Pub/Sub Lite service removes the oldest message from the partition, regardless of the message retention period for the oldest message. You should also set up alerts for topic/publish_quota_utilization and topic/subscribe_quota_utilization to make sure publish/subscribe throughputs are comfortably below limit.
Pub/Sub Lite scales vertically by allowing you to increase the throughput capacity of each partition in increments of 1MiB/s. You can increase the number of partitions in a topic as well, but this will not preserve the order of messages. The connector v0.1.0 will require you to restart with a new subscription on repartitioning, but we plan to remove this limitation soon—please keep an eye on the release notes. When starting with Pub/Sub Lite, it’s best practice to slightly overprovision the number of partitions so that the per-partition publishing and subscribing throughput capacities can be set to the lower bounds of 4 MiB/s and 8 MiB/s, respectively. As the application traffic increases, you can update the Lite topic to increase both the publishing and subscribing capacities up to 16 MiB/s and 32 MiB/s per partition, respectively. You can adjust publish and subscribe throughput capacity of a partition independently.
For more details on how your application can interact with Pub/Sub Lite, review the publishing and subscribing messages guides.
Architecture for Pub/Sub Lite + Structured Streaming
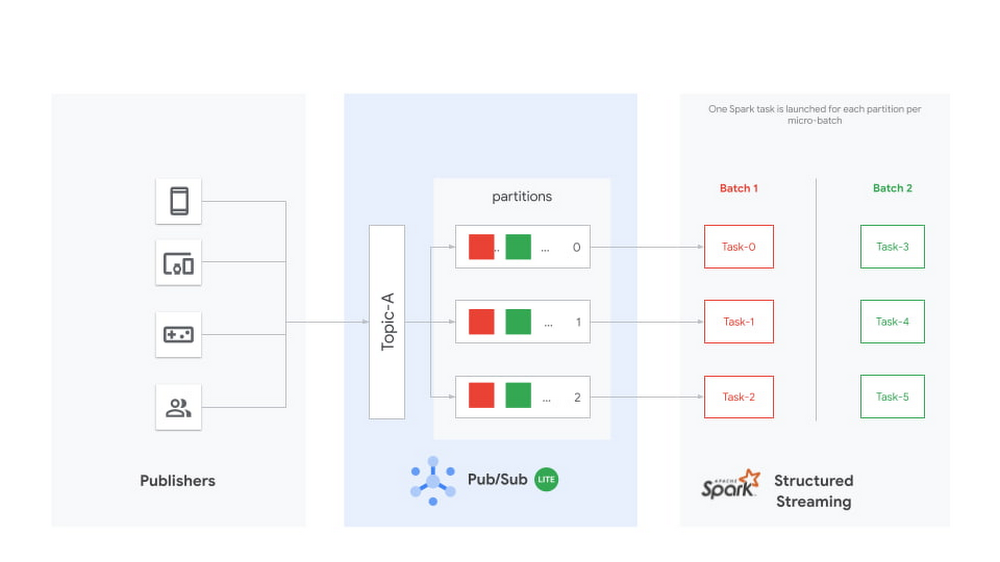
Pub/Sub Lite is only a part of a stream processing system. While Pub/Sub Lite solves the problem of message ingestion and delivery, you’ll still need a message processing component.
Apache Spark is a popular processing framework that’s commonly used as a batch processing system. Streaming processing was introduced in Spark 2.0 using a micro-batch engine. The Spark micro-batch engine processes data streams as small batch jobs that periodically read new data from the streaming source, then run a query or computation on it. The time period for each micro-batch can be configured via triggers to run at fixed intervals. The number of tasks in each Spark job will be equal to the number of partitions in the subscribed Pub/Sub Lite topic. Each Spark task will read the new data from one Pub/Sub Lite partition, and together create a streaming DataFrame or Dataset.
Each Different Structure Streaming pipeline must have its own independent subscription. Note that all subscriptions attached for one topic share the subscribing throughput capacity of that topic.
The connector also supports Spark’s experimental continuous processing mode. In this mode, the connector is designed to map each topic partition to a long-running Spark task. Once the job is submitted, the Spark driver will instruct the executors to create long-running tasks, each with a streaming connection to a different partition within the topic. Note that this mode is not yet considered production-ready; it only supports limited queries and provides only at-least-once guarantees.
Using Pub/Sub Lite with Spark Structured Streaming
Processing streams of data in Pub/Sub Lite with Spark is as simple as the Python script below. For a detailed guide to run a full Java end-to-end word count sample in Dataproc, please refer to the GitHub Readme.
First, instantiate a Spark Session object and read in a Dataframe from the Pub/Sub Lite subscription:
The following snippet processes the stream in two-second-long batches and prints the resulting messages to the terminal:
In practice, you’ll perform transformations on this data. To do this, you will need to consider the schema of the DataFrame:
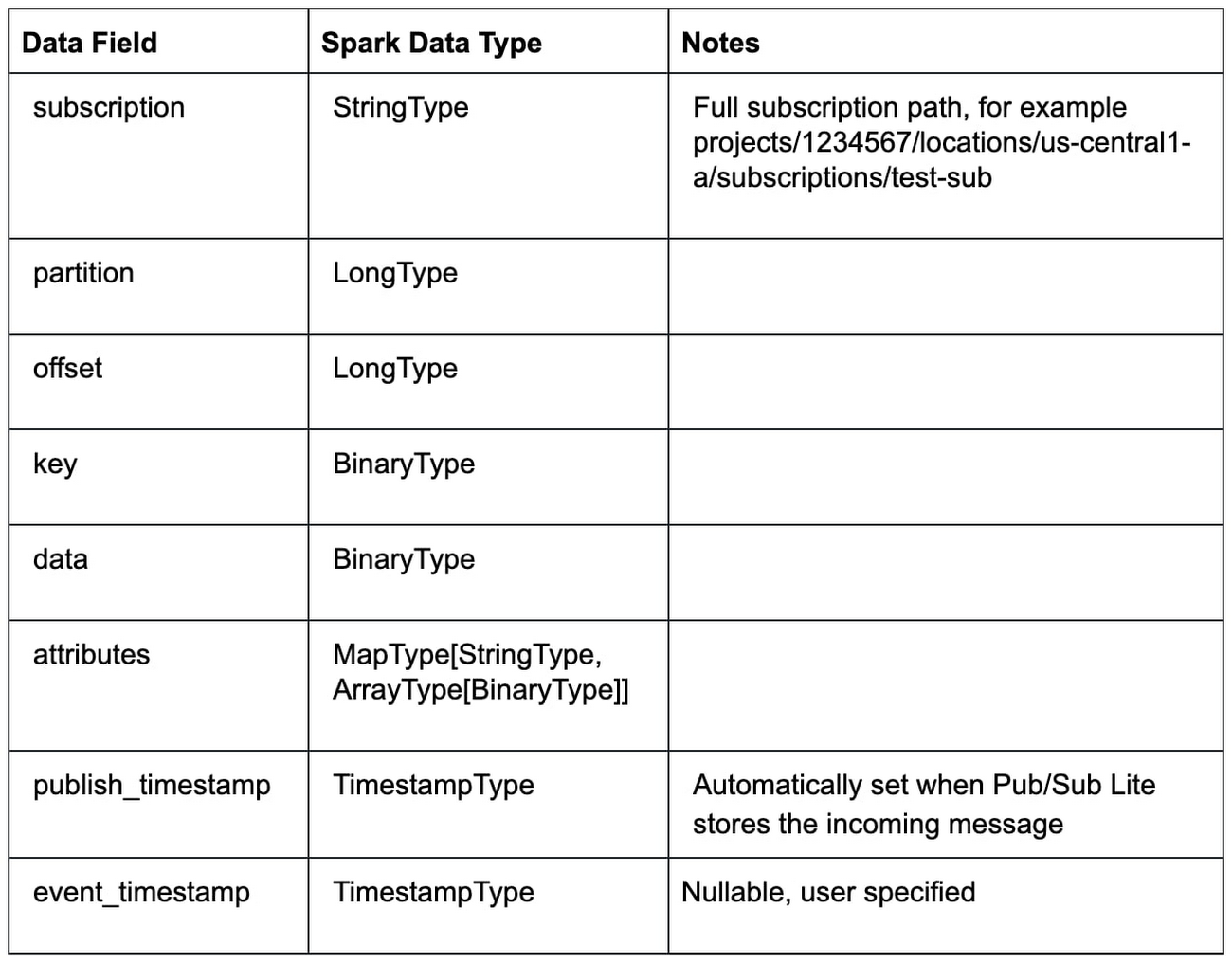
A common transformation from BinaryType to StringType is as follows:
Benchmarks for throughput performance
To get a sense of the throughput performance of the connector, as well as Pub/Sub Lite itself, we turned up an example pipeline in a Dataproc YARN cluster. In the example, the pipeline consumed backlogs from Pub/Sub Lite with no further processing. The Dataproc YARN cluster consisted of one master node and two worker nodes. All nodes were n1-standard-4 machines (4 vCPUs, 15GB memory). All messages were 1 KiB. The total spark process throughput was calculated using processedRowsPerSecond per batch, and spark process throughput per partition was calculated with total spark process throughput divided by the number of partitions.
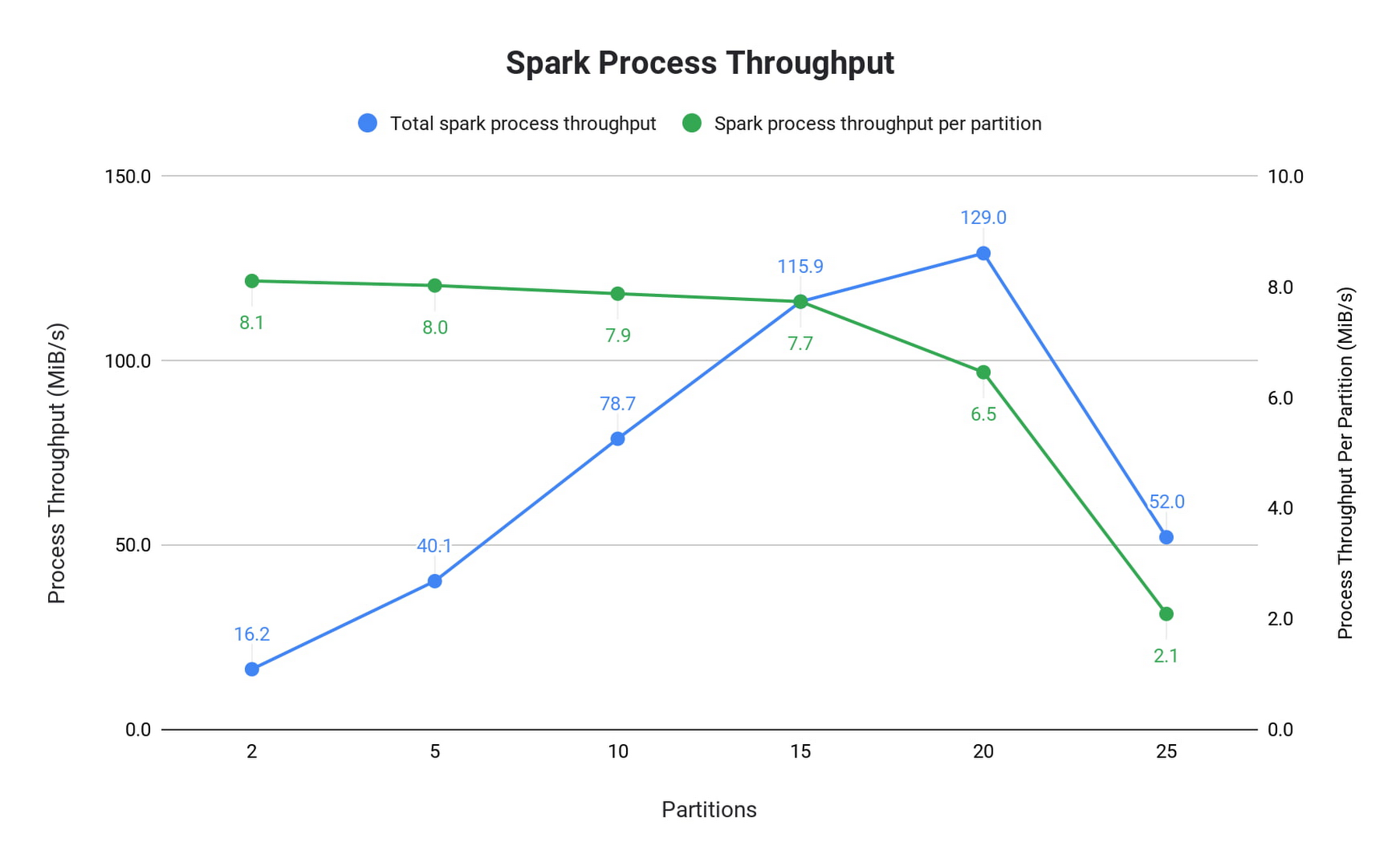
Note that for 25 partitions, the workers were overloaded, and since the processing wall time per batch was determined by the slowest partition, the processedRowsPerSecond dropped dramatically. We can see that this drop is correlated with CPU saturation by looking at CPU utilization:
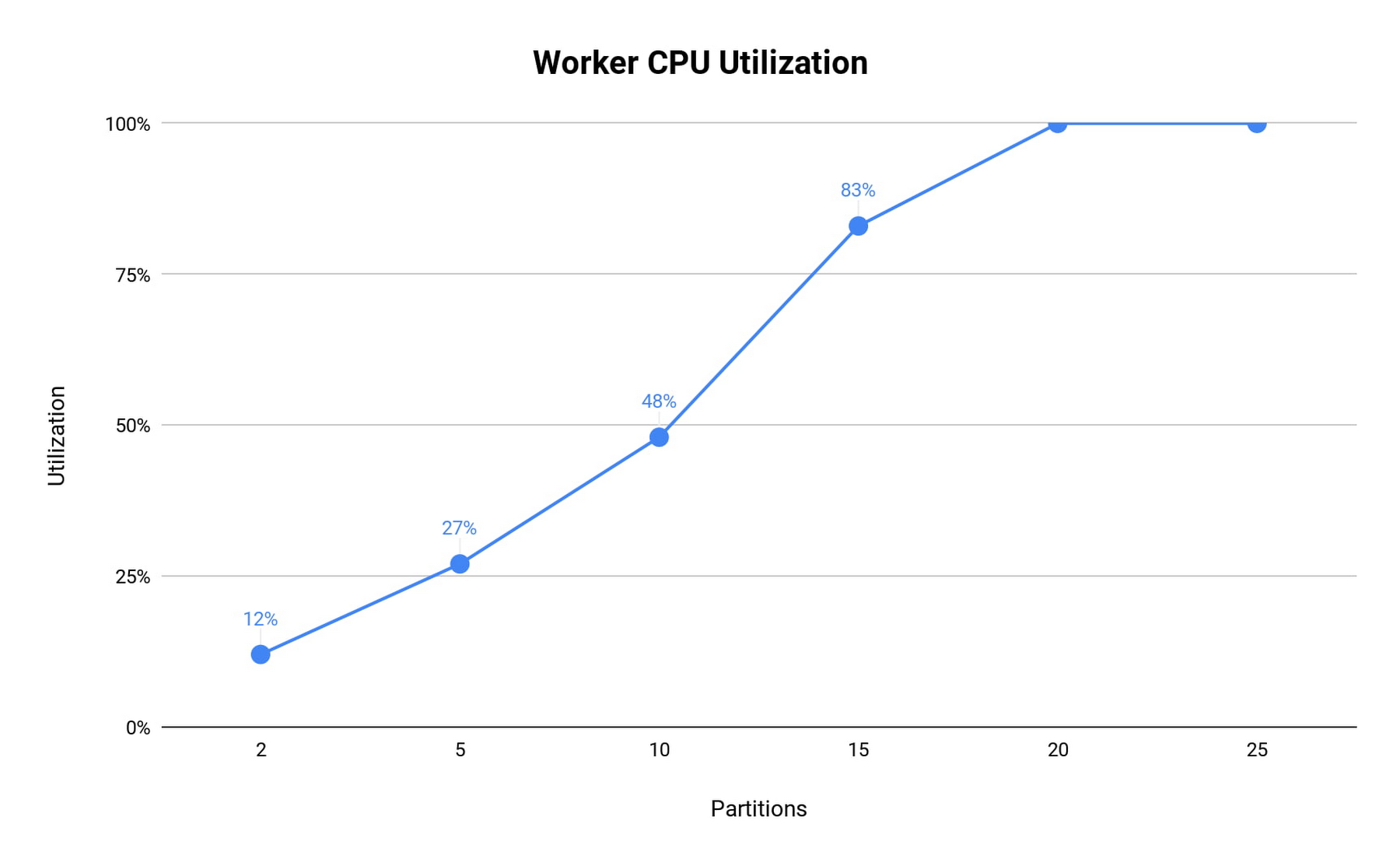
For basic read operation as a baseline, it’s recommended to have 12 partitions (8 MiB/s subscribe throughput each) in a cluster with 8 CPUs. This suggests an approximate rule of thumb: a single n1-standard-series vCPU can handle 12 MiB/s of read throughput. Any significant processing of messages will decrease this capacity.
The benchmark above did not consider memory allocation. In practice, long trigger time or spiky traffic could lead to large micro batches, requiring more memory. Also, complex queries such as aggregation and extended watermarks would require more memory.
Next Steps
We hope you’ll find Pub/Sub Lite to be a useful service for your streaming applications. Please give the connector and Pub/Sub Lite a try following the full set of directions here. We would be grateful for feedback and bug reports submitted as GitHub Issues. We also welcome code contributions to this open source project.
1. Pub/Sub Lite connector as source is compatible with exactly-once guarantee. It needs an idempotent sink to ensure exactly-once guarantee.

