Dividends from data: Building a lean data stack for a Series C Fintech
Andy Turner
Director, Data and AI, PrimaryBid
Bipul Kumar
Data and AI Practice Lead, Google Cloud Customer Engineering UK&I
It is often said that a journey of a thousand miles begins with a single step.
10 years ago, building a data technology stack felt a lot more like a thousand miles than it does today; technology, automation, and business understanding of the value of data have significantly improved. Instead, the problem today is knowing how to take the first step.

Figure: PrimaryBid Overview
PrimaryBid is a regulated capital markets technology platform connecting public companies to their communities during fundraisings. But choosing data technologies presented a challenge as our requirements had several layers:
- PrimaryBid facilitates novel access for retail investors to short-dated fundraising deals in the public equity and debt markets. As such, we need a platform that can be elastic to market conditions.
- PrimaryBid operates in a heavily regulated environment, so our data stack must comply with all applicable requirements.
- PrimaryBid handles many types of sensitive data, making information security a critical requirement.
- PrimaryBid’s data assets are highly proprietary; to make the most of this competitive advantage, we needed a scalable, collaborative AI environment.
- As a business with international ambitions, the technologies we pick have to scale exponentially, and be globally available.
- And, perhaps the biggest cliche, we needed all of the above for as low a cost as possible.
Over the last 12 or so months, we built a lean, secure, low-cost solution to the challenges above, partnering with vendors that are a great fit for us; we have been hugely impressed by the quality of tech available to data teams now, compared with only a few years ago. We built an end-to-end unified Data and AI Platform. In this blog, we will describe some of the decision-making mechanisms together with some of our architectural choices.
The 30,000 foot view
The 30,000 foot view of PrimaryBid’s environment will not surprise any data professional. We gather data from various sources, structure it into something useful, surface it in a variety of ways, and combine it together into models. Throughout this process, we monitor data quality, ensure data privacy, and send alerts to our team when things break.
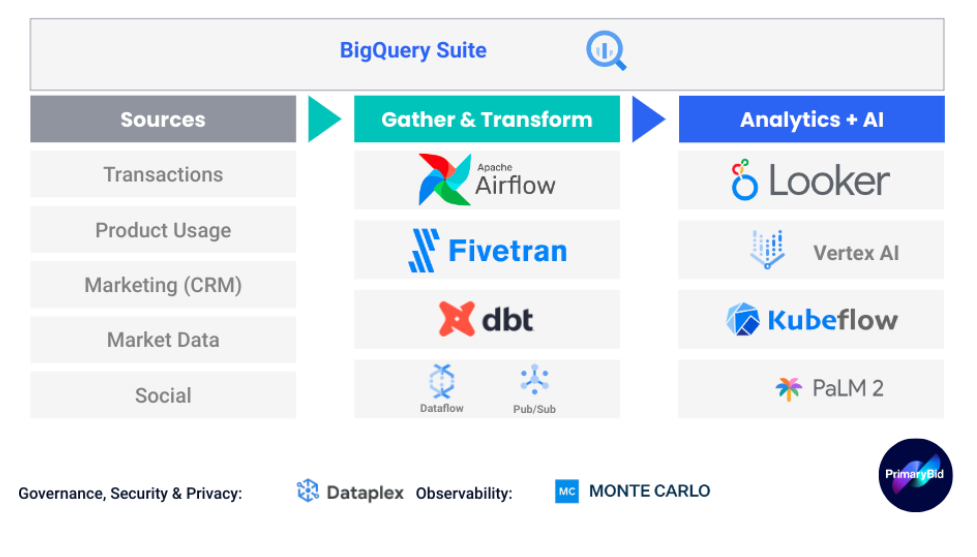
Figure: High Level summary of our data stack
Data gathering and transformation
For getting raw data into our data platform, we wanted technology partners whose solutions were low-code, fast, and scalable. For this purpose, we chose a combination of Fivetran and dbt to meet our needs.
Fivetran supports a huge range of pre-built data connectors, which allow data teams to land new feeds in a matter of minutes. The cost model we have adopted is based on monthly ‘active’ rows, i.e., we only pay for what we use.
Fivetran also takes care of connector maintenance, freeing up massive amounts of engineering time by outsourcing the perpetual cycle of updating API integrations.
Once the data is extracted, dbt turns raw data into a usable structure for downstream tools, a process known as analytics engineering. dbt and Fivetran make a synergistic partnership, with many Fivetran connectors having dbt templates available off the shelf. dbt is hugely popular with data engineers, and contains many best practices from software development that ensure analytics transformations are robust.
Both platforms have their own orchestration tools for pipeline scheduling and monitoring, but we deploy Apache Airflow 2.0, managed via Google Cloud’s Cloud Composer, for finer-grained control.
Data storage, governance, and privacy
This is the point in our data stack where Google Cloud starts to solve a whole variety of our needs.
We start with Google Cloud’s BigQuery. BigQuery is highly scalable, serverless, and separates compute costs from storage costs, allowing us only to pay for exactly what we need at any given time.
Beyond that though, what sold us the BigQuery ecosystem was the integration of the data and model privacy, governance and lineage throughout. Leveraging Google Cloud’s Dataplex, we set security policies in one place, on the raw data itself. As the data is transformed and passed between services, these same security policies are adhered to throughout.
One example is PII, which is locked away from every employee bar a necessary few. We tag data one time with a ‘has_PII’ flag, and it doesn’t matter what tool you are using to access the data, if you do not have permission to PII in the raw data you will never be able to see it anywhere.

Figure: Unified governance using Dataplex
Data analytics
We chose Looker for our self-service and business intelligence (BI) platform based on three key factors:
- Instead of storing data itself, Looker writes SQL queries directly against your data warehouse. To ensure it writes the right query, engineers and analysts build Looker analytics models using ‘LookML’. LookML for the most part is low-code, but for complex transformations, SQL can be written directly into the model, which plays to our team's strong experience with SQL. In this instance we store the data in BigQuery and access through Looker.
- Being able to extend Looker into our platforms was a core decision factor. With the LookML models in place, transformed, clean data can be passed to any downstream service.
- Finally, the interplay between Looker and Dataplex is particularly powerful. Behind the scenes, Looker is writing queries against BigQuery. As it does so, all rules around data security and privacy are preserved.
There is much more to say about the benefits we found using Looker; we look forward to discussing these in a future blog post.
AI and machine learning
The last step in our data pipelines is our AI/ML environment. Here, we have leaned even further into Google Cloud’s offerings, and decided to use Vertex AI for model development, deployment, and monitoring.
To make model building as flexible as possible, we use the open-source Kubeflow framework within Vertex AI Pipeline environment for pipeline orchestration; this framework decomposes each step of the model building process into components, each of which performs a fully self-contained task, and then passes metadata and model artifacts to the next component in the pipeline. The result is highly adaptable and visible ML pipelines, where individual elements can be upgraded or debugged independently without affecting the rest of the code base.
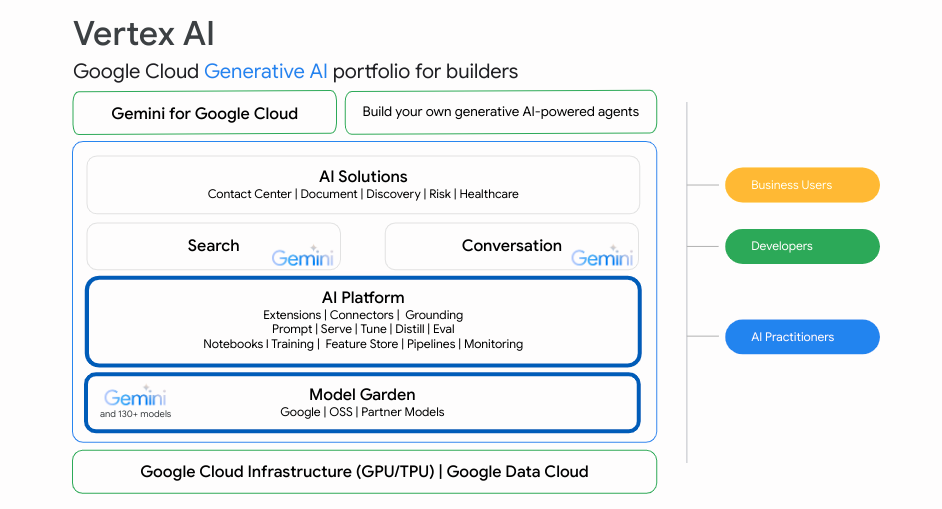
Figure: Vertex AI Platform
Finishing touches
With this key functionality set up, we’ve added a few more components to add even more functionality and resilience to the stack:
- Real-ime pipelines: running alongside our FiveTran ingestion, we added a lightweight pipeline that brings in core transactional data in real time. This leverages a combination of managed Google Cloud services, namely Pub/Sub and Dataflow, and adds both speed and resilience to our most important data feeds.
- Reverse ETL: Leveraging a CDP partner, we write analytics attributes about our customers back into our customer relationship management tools, to ensure we can build relevant audiences for marketing and service communications.
- Generative AI: following the huge increase in available gen AI technologies, we’ve built several internal applications that leverage Google’s PaLM 2. We are working to build an external application too — watch this space!
So there you have it, a whistle-stop tour of a data stack. We’re thrilled with the choices we’ve made, and are getting great feedback from the business. We hope you found this useful and look forward to covering how we use Looker for BI in our organization.
Special thanks to the PrimaryBid Data Team, as well as Stathis Onasoglou and Dave Elliott for their input prior to publication.


