Moving a publishing workflow to BigQuery for new data insights
Charles Baer
Product Manager, Google Cloud
Google Cloud’s technology powers both our customers as well as our internal teams. Recently, the Solutions Architect team decided to move an internal process to use BigQuery to streamline and better focus efforts across the team.
The Solutions Architect team publishes reference guides for customers to use as they build applications on Google Cloud. Our publishing process has many steps, including outline approval, draft, peer review, technical editing, legal review, PR approval and finally, publishing on our site. This process involves collaboration across the technical editing, legal, and PR teams.
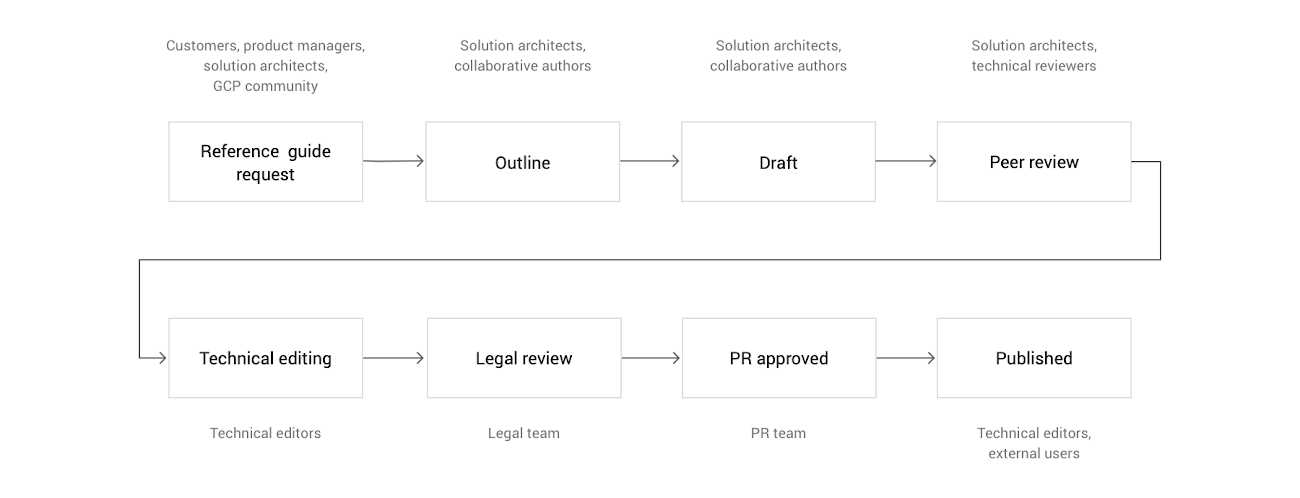
With so many steps and people involved, it’s important that we effectively collaborate. Our team uses a collaboration tool running on Google Cloud Platform (GCP) as a central repository and workflow for our reference guides.
Increased data needs required more sophisticated tools
As our team of solution architects grew and our reporting needs became more sophisticated, we realized that we couldn’t effectively provide the insights that we needed directly in our existing collaboration tool. For example, we needed to build and share status dashboards of our reference guides, build a roadmap for upcoming work, and analyze how long our solutions take to publish, from outline approval to publication. We also needed to share this information outside our team, but didn’t want to share unnecessary information by broadly granting access to our entire collaboration instance.
Building a script with BigQuery on the back end
Since our collaboration tool provides a robust and flexible REST API, we decided to write an export script which stored the results in BigQuery. We chose BigQuery because we knew that we could write advanced queries against the data and then use Data Studio to build our dashboards. Using BigQuery for analysis provided a scalable solution that is well-integrated into other GCP tools and has support for both batch and real-time inserts using the streaming API.
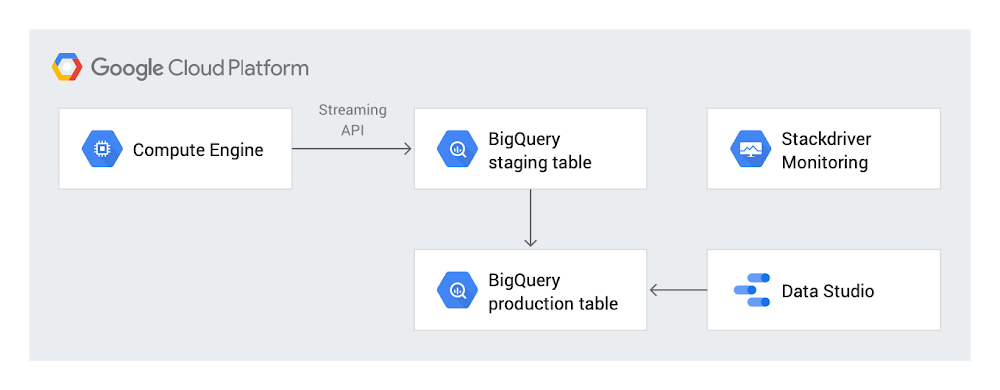
We used a simple Python script to read the issues from the API and then insert the entries into BigQuery using the streaming API. We chose the streaming API, rather than Cloud Pub/Sub or Cloud Dataflow, because we wanted to repopulate the BigQuery content with the latest data several times a day. The Google API Python client library was an obvious choice, because it provides an idiomatic way to interact with the Google APIs, including the BigQuery streaming API.
Since this data would only be used for reporting purposes, we opted to keep only the most recent version of the data as extracted. There were two reasons for this decision:
- Master data: There would never be any question about which data was the master version of the data.
- Historical data: We had no use cases that required capturing any historical data that wasn’t already captured in the data extract.
Following common extract, transform, load (ETL) best practices, we used a staging table and a separate production table so that we could load data into the staging table without impacting users of the data. The design we created based on ETL best practices called for first deleting all the records from the staging table, loading the staging table, and then replacing the production table with the contents.
When using the streaming API, the BigQuery streaming buffer remains active for about 30 to 60 minutes or more after use, which means that you can’t delete or change data during that time. Since we used the streaming API, we scheduled the load every three hours to balance getting data into BigQuery quickly and being able to subsequently delete the data from the staging table during the load process.
Once our data was in BigQuery, we could write SQL queries directly against the data or use any of the wide range of integrated tools available to analyze the data. We chose Data Studio for visualization because it’s well-integrated with BigQuery, offers customizable dashboard capabilities, provides the ability to collaborate, and of course, is free.
Because BigQuery datasets can be shared with users, this opened up the usability of the data for whomever was granted access and also had appropriate authorization. This also meant that we could combine this data in BigQuery with other datasets. For example, we track the online engagement metrics for our reference guides and load them into BigQuery. With both datasets in BigQuery, it made it easy to factor in the online engagement numbers to build dashboards.
Creating a sample dashboard
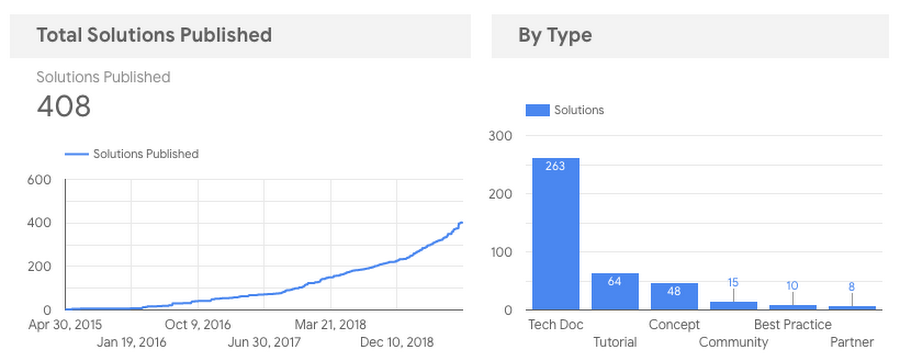
One of the biggest reasons that we wanted to create reporting against our publishing process is to track the publishing process over time. Data Studio made it easy to build a dashboard with charts, similar to the two charts below. Building the dashboard in Data Studio allowed us to easily analyze our publication metrics over time and then share the specific dashboards with teams outside ours.
Monitoring the load process
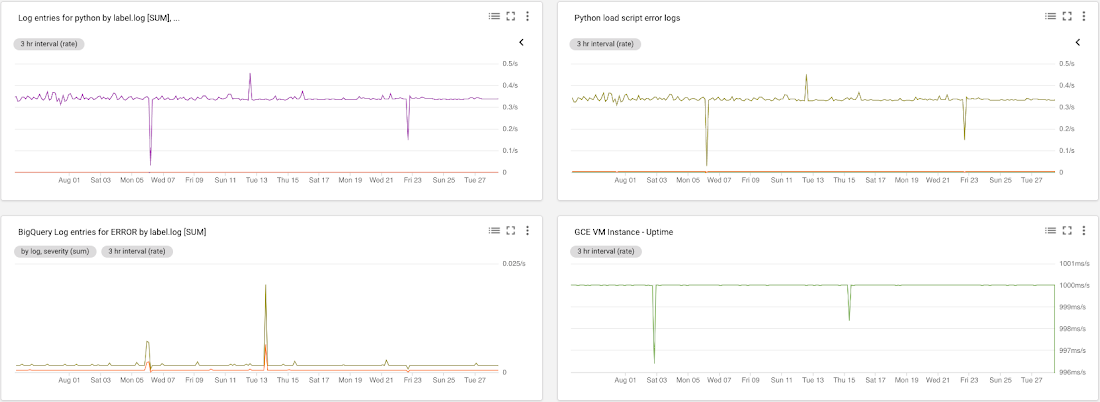
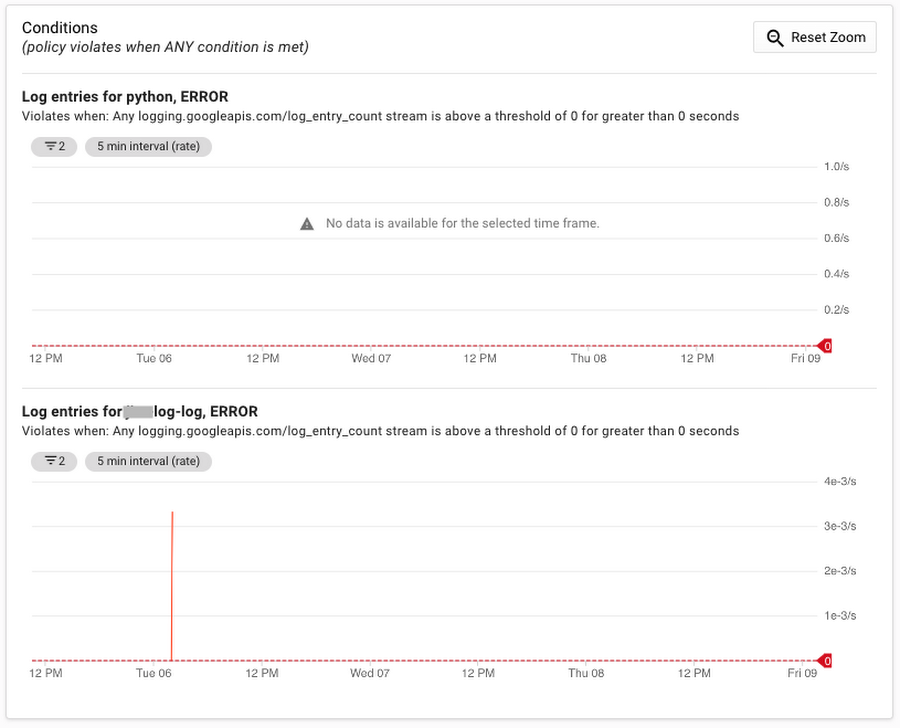
Monitoring is an important part of any ETL pipeline. Stackdriver Monitoring provides monitoring, alerting and dashboards for GCP environments. We opted to use the Google Cloud Logging module in the Python load script, because this would generate logs for errors in Stackdriver Logging that we could use for error alerting in Stackdriver Monitoring. We set up a Stackdriver Monitoring Workspace specifically for the project with the load process. We then created a management dashboard to track any application errors. We set up alerts to send an SMS notification whenever errors appeared in the load process log files. Here’s a look at the dashboards in the Stackdriver Workspace:
And this shows the details of the alerts we set up:
BigQuery provides the flexibility for you to meet your business or analytical needs, whether they’re petabyte-sized or not. BigQuery’s streaming API means that you can stream data directly into BigQuery and provide end users with rapid access to data. Data Studio provides an easy-to-use integration with BigQuery that makes it simple to develop advanced dashboards. The cost-per-query approach means that you’ll pay for what you store and analyze, though BigQuery also offers flat-rate pricing if you have a high number of large queries. For our team, we’ve been able to gain considerable new insights into our publishing process using BigQuery, which have helped us both refine our publishing process and focus more effort on the most popular technical topics.
If you haven’t already, check out what BigQuery can do using the BigQuery public datasets and see what else you can do with GCP in our reference guides.

