Announcing the GA of Data Fusion, the bridge to data analytics
Bhooshan Mogal
Product Manager
Nitin Motgi
Group Product Manager
Building dependable, flexible data integration to gather the data your business needs, and preparing it for data analytics, is an essential step toward successful big data analytics. But traditional data processing and DIY ETL processes are complex and time-consuming, slowing down data analysis. At Google Cloud, our aim is to radically simplify data integration and ingestion processes to accelerate time to insights. Code-free development of ETL and ELT data pipelines is here. We’re announcing the general availability of Cloud Data Fusion, a managed, cloud-native data ingestion and integration service that can bring the capabilities of a seasoned data engineer to any team—whether they know a little code or none at all.
Data Fusion equips developers, data engineers, and business analysts to easily build and manage ETL and ELT pipelines to cleanse, transform and blend data from a broad range of sources. You can skip the expertise bottlenecks and focus instead on learning from your data. Built on the open source project CDAP, Data Fusion’s open core ensures portability for users across hybrid and multi-cloud environments. CDAP’s broad integration with on-premises and public cloud platforms helps Data Fusion users easily access Google Cloud’s big data and analytics tools, like BigQuery.
Data Fusion lets Vodafone deliver BI modernization in weeks, not quarters
Vodafone is rethinking data and analytics as they move from complex BI to actionable insights. With Cloud Data Fusion, the company is successfully modernizing BI stack operations across global markets.
“Modernizing the BI stack for 26 operating countries is complex and challenging,” says Osman Peermamode, director of business intelligence and analytics at Vodafone Group. “Cloud Data Fusion is one of the fundamental and critical building blocks to BI modernization. With Data Fusion, we are able to quickly aggregate data from various sources, cleanse and blend without code, and standardize pipelines for faster delivery of projects. It not only improves productivity but has also provided agility to transform multiple markets quickly. Additionally, we are now able to access data loads and reports faster; 25 minutes runtime today vs. 36 hours previously. Finally, Data Fusion lineage capability has provided much-needed insights into the quality of KPIs. We are very excited to partner with Google Cloud and the Data Fusion team to make our BI transformation a success.”
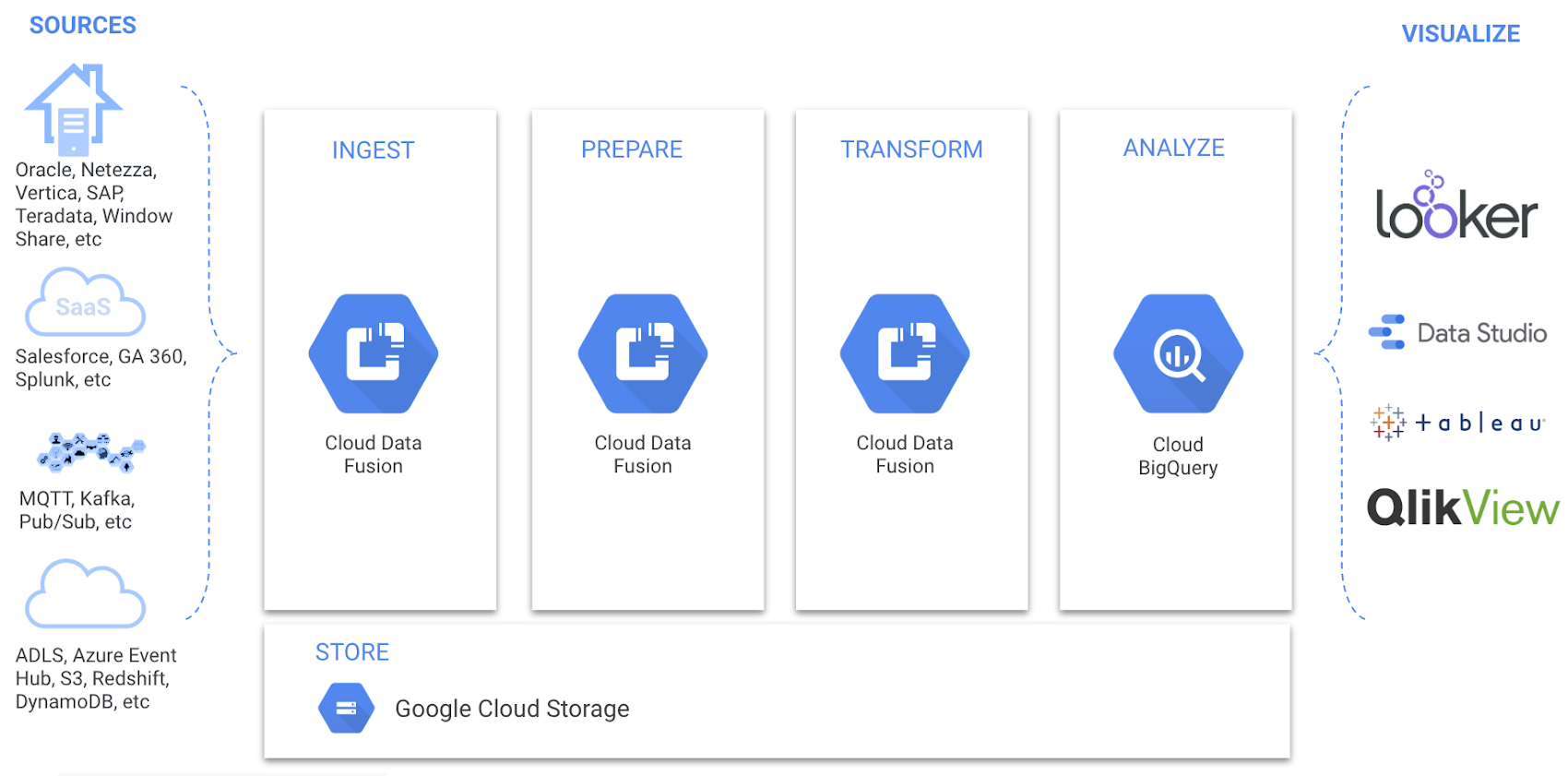
We have been listening to Data Fusion beta users, and now, Data Fusion is generally available, along with the features that our users asked for. Here are some of the new capabilities we are launching in Data Fusion:
- Secure access to on-premises data with private IP
- Encryption of data at-rest with Customer Managed Encryption Keys (CMEK)
- VPC Service Controls for preventing data exfiltration
- Field-level data lineage in Alpha
- Expanded connector ecosystem
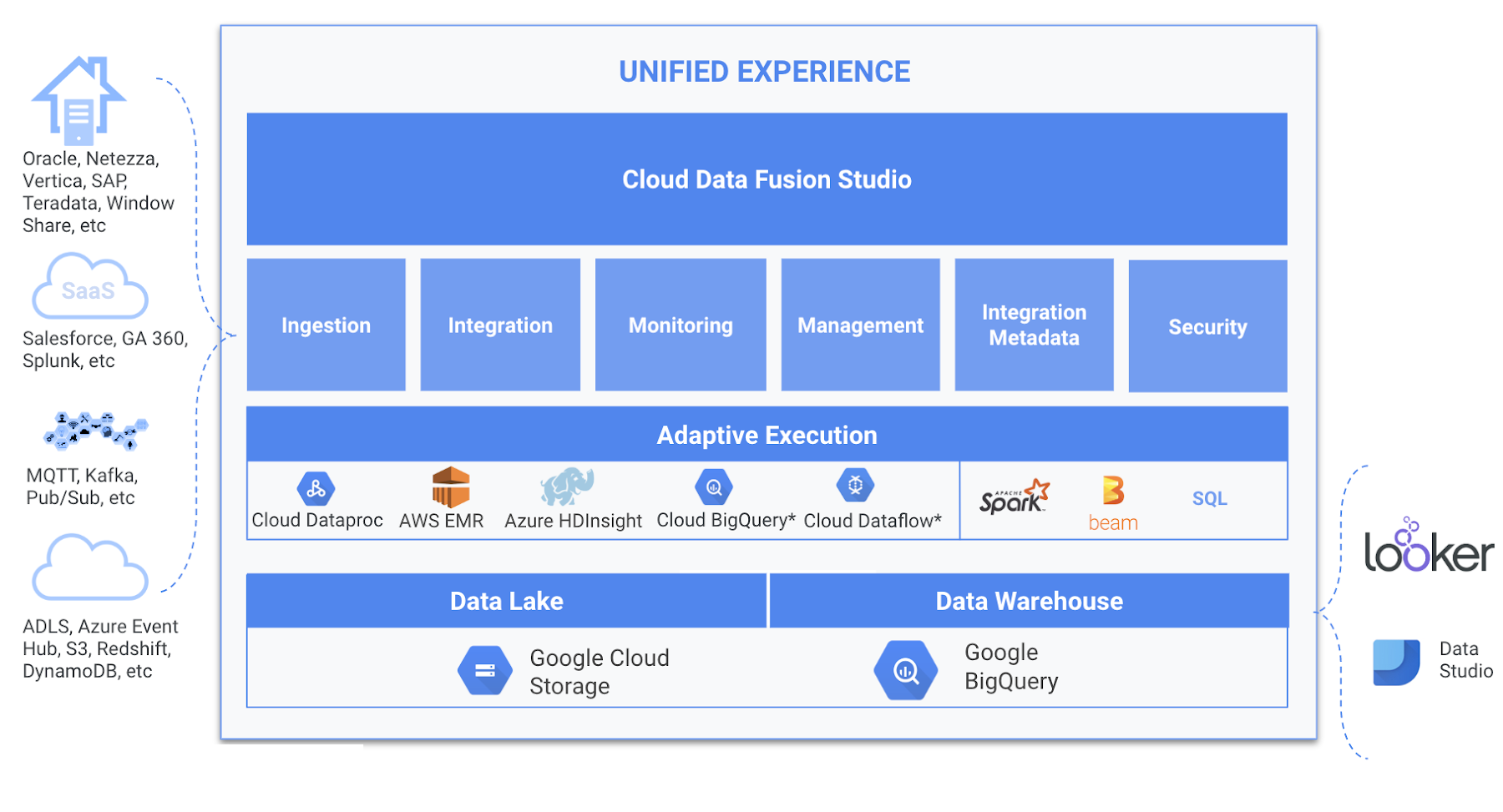
Getting to know Data Fusion
Data Fusion can make it much easier to build pipelines and bring all your data together. Here’s more detail about the recently launched features.
Securely access on-premises data with Private IP
Securing the movement of data should be easy. With private service access in Data Fusion, you can lock down an instance to run entirely on private IP-only compute resources not accessible through the public internet. Instances can now connect to on-premises resources, such as RDBMS, securely over a private network. This means you no longer have to make prohibitive networking changes to access your data from Data Fusion.
Encryption of data at rest with Customer Managed Encryption Keys
Encryption of data at rest is foundational to any data protection strategy. Google Cloud Platform (GCP) encrypts data at rest using Google’s default encryption keys. In addition to providing encryption by default, Data Fusion now supports Customer Managed Encryption Keys (CMEK) for even greater levels of control across all user data in supported storage systems. You can read CMEK-encrypted data as a source, and will also be able to specify CMEK keys for encrypting all data written by Data Fusion to supported services on GCP.
VPC Service Controls for preventing data exfiltration
The requirement for the protection of sensitive data is higher than ever. VPC Service Controls allows GCP users to define a security perimeter around platform resources in order to protect private data and mitigate exfiltration risks. With this in mind, we’re happy to announce you can now add Data Fusion instances to your service perimeter and run pipelines in a VPC Service Controls environment.
Field-level data lineage, now in Alpha
Field-level lineage allows enterprises to simplify critical tasks, such as root cause analysis of data errors, analyze the impact of changes, and seamlessly govern their data. It also serves as a key enabler for compliance and regulatory reporting by allowing you to trace data as it flows through, at a granular level, including the transformations that were performed on individual fields.
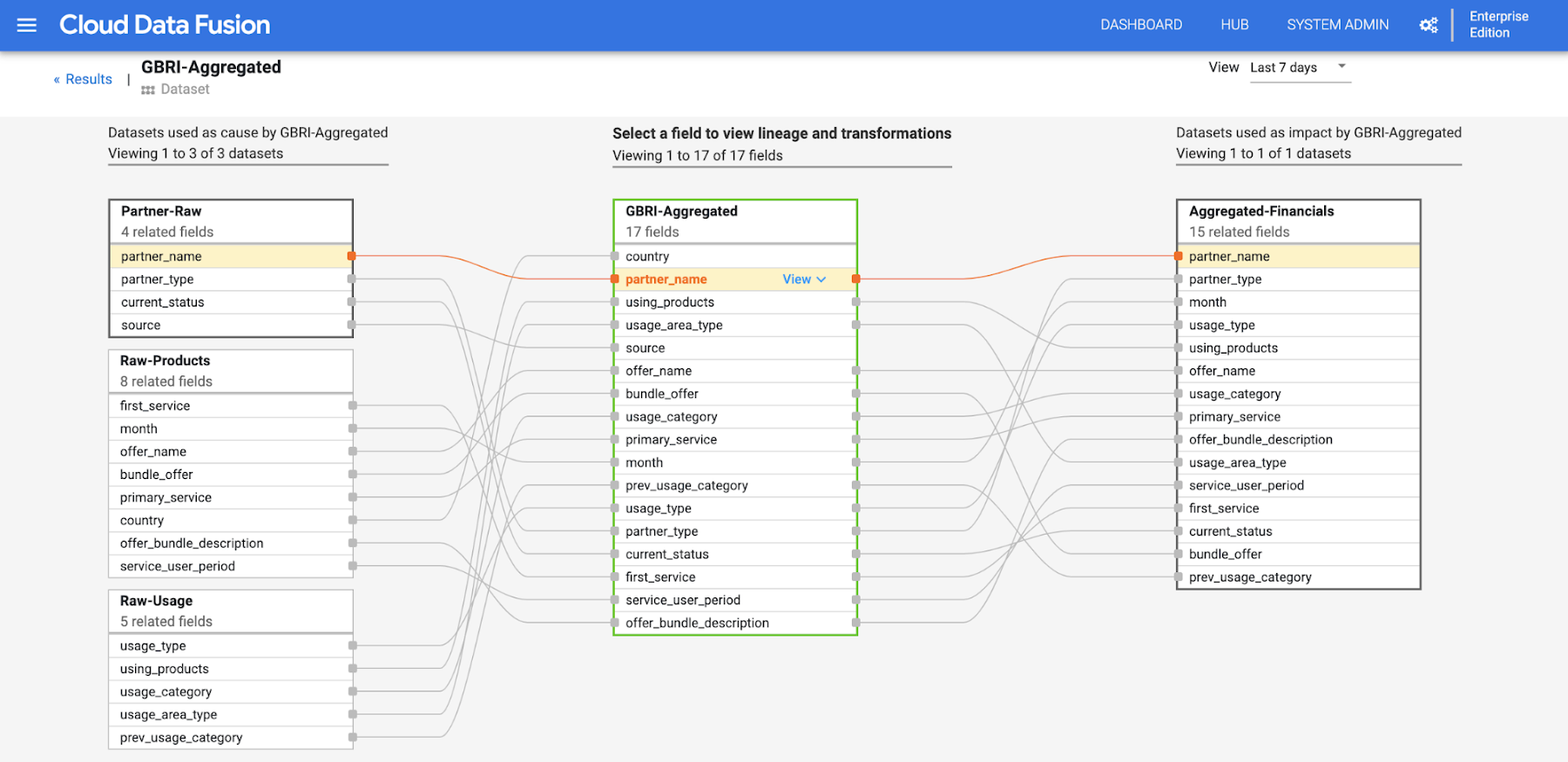
Expanded connector ecosystem
This Data Fusion release also includes new connectors that can help you integrate your data from a variety of relational databases (SAP Hana, Teradata), NoSQL stores (MongoDB) and SaaS applications (Salesforce, Google Analytics 360, etc).
No matter where you stand, you’re now ready for data analytics on the cloud! What are you waiting for? Check out the Data Fusion Quickstart Guide and build your first pipeline today.


