Introducing six new cryptocurrencies in BigQuery Public Datasets—and how to analyze them

Allen Day
Developer Advocate, Digital Assets at Google Cloud
Evgeny Medvedev
Author of Blockchain ETL
Since they emerged in 2009, cryptocurrencies have experienced their share of volatility—and are a continual source of fascination. In the past year, as part of the BigQuery Public Datasets program, Google Cloud released datasets consisting of the blockchain transaction history for Bitcoin and Ethereum, to help you better understand cryptocurrency. Today, we're releasing an additional six cryptocurrency blockchains.
We are also including a set of queries and views that map all blockchain datasets to a double-entry book data structure that enables multi-chain meta-analyses, as well as integration with conventional financial record processing systems.
Additional blockchain datasets
The six cryptocurrency blockchain datasets we’re releasing today are Bitcoin Cash, Dash, Dogecoin, Ethereum Classic, Litecoin, and Zcash.
Five of these datasets, along with the previously published Bitcoin dataset now follow a common schema that enables comparative analyses. We are releasing this group of Bitcoin-like datasets (Bitcoin, Bitcoin Cash, Dash, Dogecoin, Litecoin and Zcash) together because they all have similar implementations, i.e., their source code is derived from Bitcoin’s. Similarly, we’re also releasing the Ethereum Classic dataset alongside the previously published Ethereum dataset, and Ethereum Classic is also using the same common schema.
A unified data ingest architecture
All datasets update every 24 hours via a common codebase, the Blockchain ETL ingestion framework (built with Cloud Composer, previously described here), to accommodate a variety of Bitcoin-like cryptocurrencies. While this means higher latency for loading Bitcoin blocks into BigQuery, it also means that:
- We are able to ingest additional BigQuery datasets with less effort, meaning additional datasets can be onboarded more quickly in the future.
- We can implement a low-latency loading solution once that can be used to enable real-time streaming transactions for all blockchains.
Unified schema and views
Since we provided the original Bitcoin dataset last year, we’ve learned how users want to access data, and restructured the dataset accordingly. Some of these changes address performance and convenience concerns, yielding faster and lower cost queries (commonly accessed nested data are denormalized; each table is partitioned by time).
We’ve also included more data, such as script op-codes. Most Bitcoin transactions describe transfers of value not simply as a debit/credit pair, but rather as a series of functions that describe both simple transfers and more complex transactions.
Having these scripts available for Bitcoin-like datasets enables more advanced analyses similar to this smart contract analyzer that Tomasz Kolinko recently built on top of the BigQuery Ethereum dataset. For example, we can now identify and report on patterns of activity involving multi-signature wallets. This is particularly important for analyzing privacy-oriented cryptocurrencies like Zcash.
For analytics interoperability, we designed a unified schema that allows all Bitcoin-like datasets to share queries. To further interoperate with Ethereum and ERC-20 token transactions, we also created some views that abstract the blockchain ledger to be presented as a double-entry accounting ledger.
Double-entry book view: example queries
To motivate an initial exploration of these new datasets, let’s start with a simple example, comparing the way to query both payments and receipts across multiple cryptocurrencies. This comparison is the simplest way to verify that a cryptocurrency is operating as intended, and at least operationally, is a mathematically correct store of value.
1. Balance queries demonstrating preservation of value
Heres are some equivalent balance queries for the Bitcoin and Dogecoin datasets:
Note that the only difference between them is the name of the data location. You can swap in Bitcoin Cash, Dash, Litecoin, and Zcash in a similar fashion.
2. Understanding miner economics on Bitcoin
The BigQuery dataset makes it possible to analyze how miners are allocating space in the blocks they mine.
This query shows that transaction fees on the bitcoin network follows a Poisson distribution, confirming that there are zero-fee transactions being included in mined blocks.
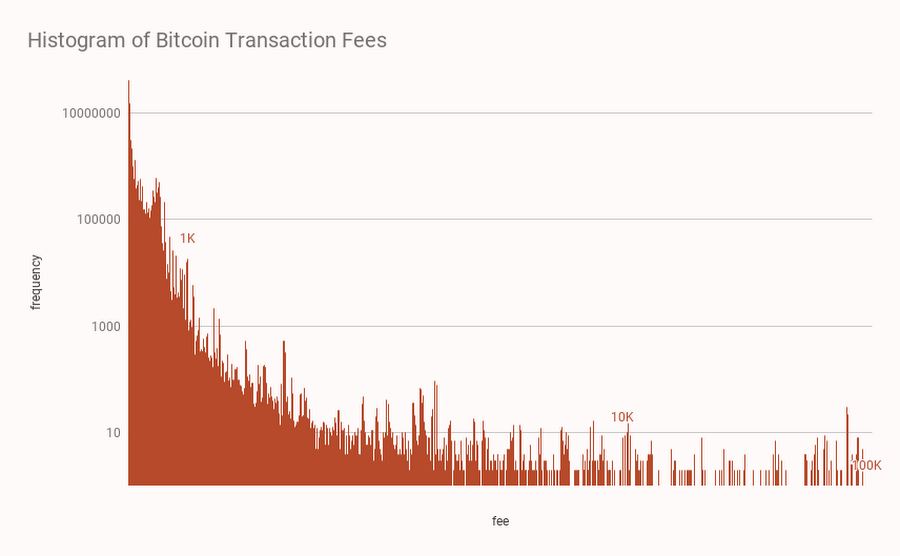
Given that miners are incentivized to profit from transaction fees, it begs the question: why are they including zero-fee transactions? Possible reasons include:
- Miners are including their own transactions for zero fees.
- Miners run transaction accelerators, i.e., off-chain services that allows transactors to pay mining fees out-of-band (typically with fiat currency) for the purpose of accelerating confirmation of transactions.
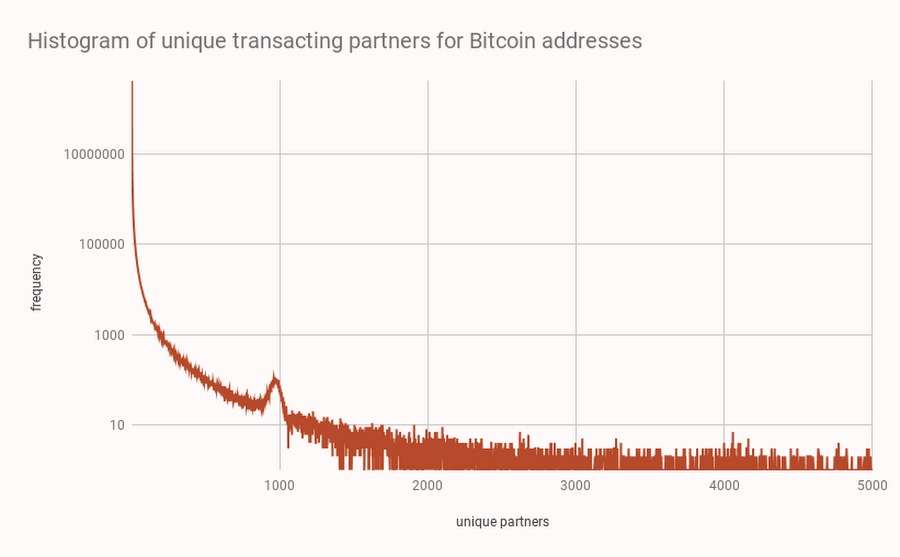
3. Understanding how often Bitcoin addresses are reused
Over 91% of addresses on the Bitcoin network have been used only once.
Creating a new Bitcoin address for each inbound payment is a suggested best practice for users seeking to protect their privacy. This is because using blockchain analytics it is possible to identify which other addresses a given user’s wallet has transacted with and the size of the shared transactions.
This query can be plotted to show the relationship between addresses and the number of transacting partners:
Multi-chain crypto-econometrics
Beyond quality control and auditing applications, presenting cryptocurrency in a traditional format enables integration with other financial data management systems. As an example, let’s consider a common economic measure, the Gini Coefficient. In the field of macroeconomics, the Gini Coefficient is a member of a family of econometric measures of wealth inequality. Values range between 0.0 and 1.0, with completely distributed wealth (all members have the same amount) mapping to a value of 0.0 and completely accumulated wealth (one member has everything) mapping to 1.0.
Typically, the Gini Coefficient is estimated for a specific country’s economy based on data sampling or imputation. For crypto-economies, we have complete transparency of the data at the highest possible resolution.
In addition to data transparency, one of the purported benefits of cryptocurrencies is that they allow the implementation of money to more closely resemble the implementation of digital information. It follows that a fully digitized money network will come to resemble the internet, with reduced transactional friction and fewer barriers that impede capital flow. Frequently, implicit in this narrative is that capital will distribute more equally. But we don’t always observe that particular outcome, and the crypto-assets presented here display a broad spectrum of distribution patterns over time. You can read more about using the Gini coefficient to reason about crypto-economic network performance in Quantifying Decentralization.
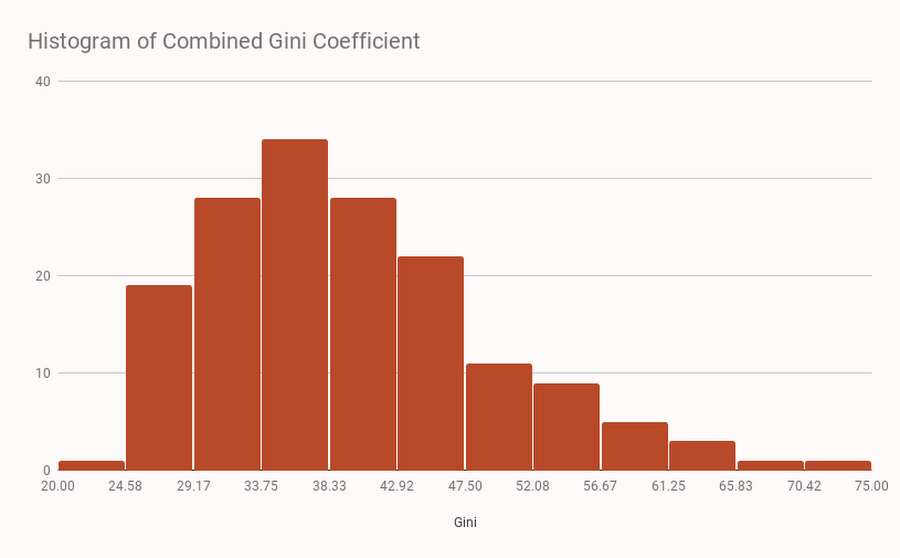
To set a baseline to interpret our findings, consider how resources are distributed in traditional, non-crypto economies. According to a World Bank analysis in 2013, recent Gini coefficients for world economies have a mean value of 39.6 (with a standard deviation of 9.6). We plot a histogram of the reported data below. Some recent Gini measures include:
- South Africa (2010): 67
- Sweden (2008): 26
- United States (2011): 48
- Venezuela (2011): 39
We use the double-entry book pattern to compare the equality of cryptocurrency distribution of the Bitcoin-like datasets being released today along with Ethereum and a few Ethereum-based ERC-20 tokens. Primary data were normalized using a few different views (BTC-family to DE-Book, Ethereum to DE-Book, and ERC-20 to DE-book).
In the figure below, the Gini coefficient is rendered for the top 10,000 address balances within each dataset, tabulated daily and across the entire history. The Bitcoin-like cryptocurrencies are rendered in ochre tones while the Ethereum chains and ERC-20 Maker token are rendered in blue tones. Note that Bitcoin Cash is rendered as a dotted line, diverging from Bitcoin in mid-2017. Similarly, Ethereum classic diverges as a dotted line away from Ethereum.
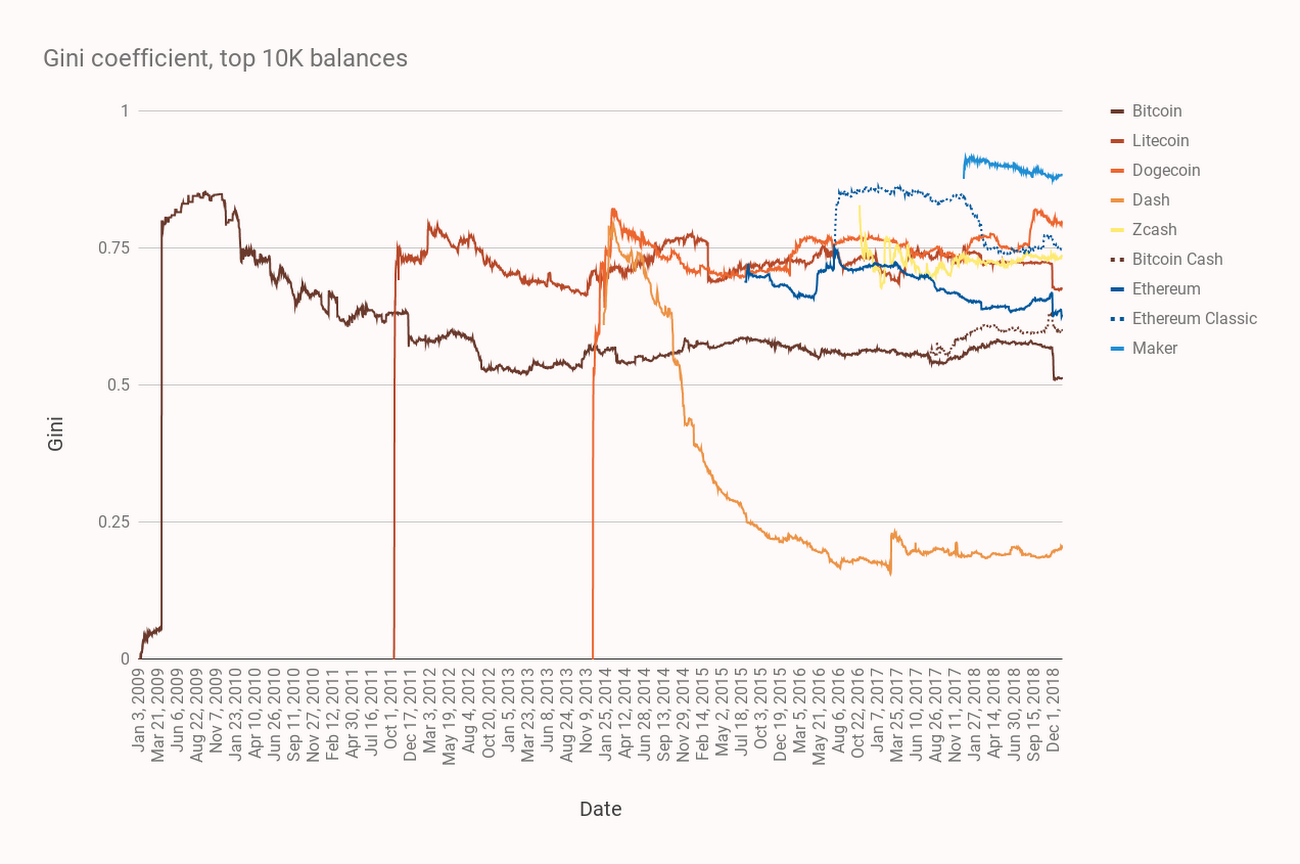
It’s difficult to make conclusive statements about the crypto-economies from the Gini coefficient for the following reasons:
- Many of the crypto-assets are stored in exchanges and don’t correspond to individual holders. This biases the Gini coefficient toward accumulation.
- Gini is known to be sensitive to including small balances in the analysis and is usually done on large addresses only. Removing small balances, as we did here, biases the Gini coefficient toward distribution.
- In our analysis all addresses are treated as individual holders. In reality, multiple addresses can belong to the same individual. This can bias the Gini either toward accumulation or distribution.
And when examining the chart to compare specific cryptocurrencies:
- Zcash in particular is difficult to measure because it has many so-called shielded transactions that produce addresses for which the balance cannot be accurately tabulated. It’s not clear in which direction shielded transactions bias the Gini coefficient. However we do speculate that there is asymmetric interest in using shielded transactions: larger holders are more likely to want to keep their holdings private and it follows that Gini for Zcash is probably biased toward distribution.
- Dash has a system property whereby interest payments may be earned from the network by address balances that hold a minimum 1000 DASH. Large asset holders are incentivized to split holdings amongst multiple addresses, which biases Gini toward distribution. Even so, Dash is remarkably well distributed relative to all other cryptocurrencies examined here.
- Bitcoin Cash was purportedly created to increase transfer-of-value use cases through lower transaction fees, which should ultimately lead to a lower Gini coefficient of address balances. However, we see that the opposite is true—Bitcoin Cash holdings have actually accumulated since Bitcoin Cash forked from Bitcoin. Similarly, the Ethereum Classic currency was rapidly accumulated post-divergence and remains so.
- The ERC-20 token Maker (a stablecoin) has a distribution that is decoupled from its parent chain, Ethereum. Maker was issued as distinct asset on the Ethereum chain, in contrast to Ethereum’s native currency, Ether.
- In early December 2018, Bitcoin, Ethereum, and Litecoin had a major distribution event, while Bitcoin Cash had a major accumulation event. This was the largest redistribution of large Bitcoin balances since December, 2011. The Bitcoin redistribution appears to be related to an announced Coinbase reorganization of funds storage. Given the synchronization of movements, it is likely that the Ethereum redistribution was also Coinbase activity.
Here’s the code to query the participating addresses. Also find a visualization of the distribution event below, with addresses as circles and lines between circles as value transfers. The original holding address is at the center. Sizes are determined by the post-event distribution of value, with peripheral circle areas proportional to the final balance and edge weights are proportional to the logarithm of the amount of Ether transferred.
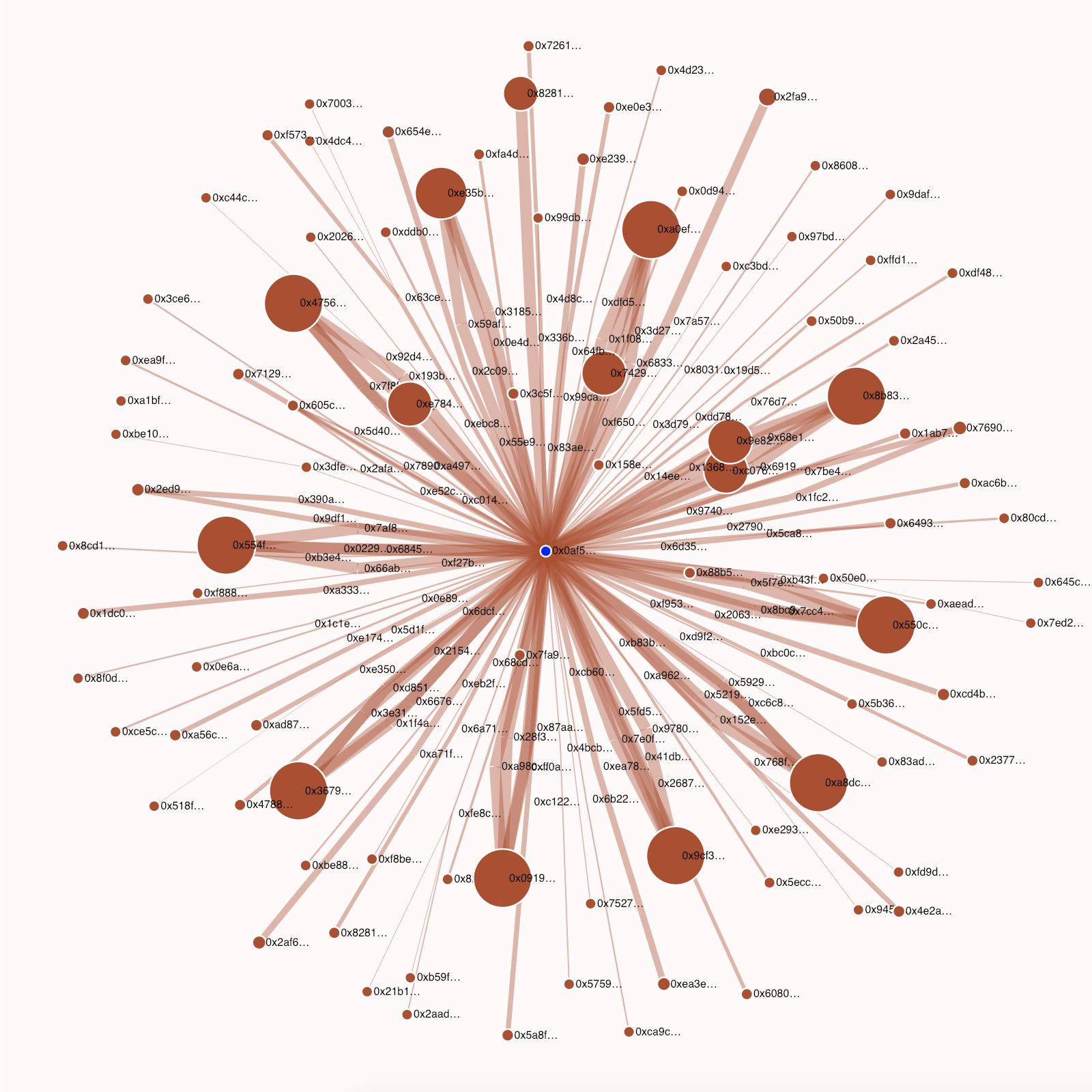
Studies in the domains of ecology and network science tell us that biodiversity is positively correlated to ecological stability and increases ecosystem productivity by supporting more complex community structures. The downward trend of Gini (i.e. higher levels of diversity) for crypto-asset holdings is likely a positive sign for the future health of crypto-economies.
The Gini coefficient is but one of a number of econometric indicators of wealth inequality, and other indicators may give contradictory results. Rather than drawing conclusions from the analysis presented here, we emphasize that we’ve built useful infrastructure for performing analysis, and fully expect that motivated analysts will swap in their own methods.
Address classification
Blockchain transaction history can be aggregated by address and used to analyze user behavior. To motivate further exploration, we present a simple classifier that can detect Bitcoin mining pools. As a brief historical note, mining pools were created when the difficulty of mining Bitcoin reached such a level that rewards could be expected only once every few years. Miners began to pool their resources to earn a smaller share of rewards more consistently and in proportion to their contribution to the pool in which they were mining.
First, we constructed 26 feature vectors to characterize incoming and outgoing transaction flows to each address. Next, we trained the model using labels derived from transaction signatures. Many large mining pools identify themselves in the signature of blocks' Coinbase transactions. Parsing these signatures, we labelled 10,000 addresses as belonging to known mining pools. One million other addresses were included in the dataset as “non-miners.” The query used to generate our features and labels can be seen here, and the source code for this analysis can be found in a Kaggle notebook here.
Model selection
We used a random forest classification model for its strong out-of-the-box effectiveness at building a good classifier and ability to model nonlinear effects.
Because known mining pools are a very small percentage of our data, we are interested in correctly identifying as many of them as possible. In other words, we focused on maximizing recall. To ensure the minority class is adequately represented, we weighted classes in inverse proportion to how frequently they appear in the data.
Interpreting the results
The confusion matrix below summarizes the performance of the classification model on a subset of addresses reserved for model testing. False positives (in the upper right quadrant) merit closer inspection. These addresses may belong to “dark” mining pools, i.e., those which are not publicly known or do not identify themselves in Coinbase transaction signatures.
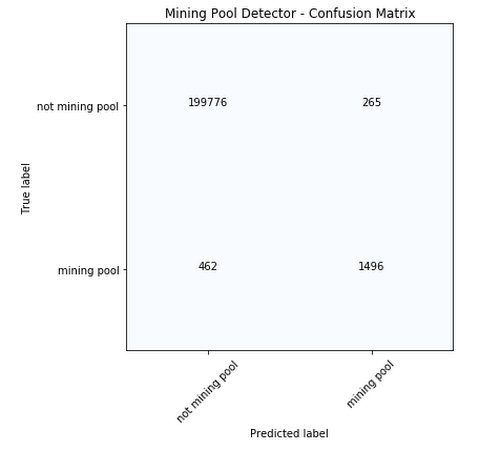
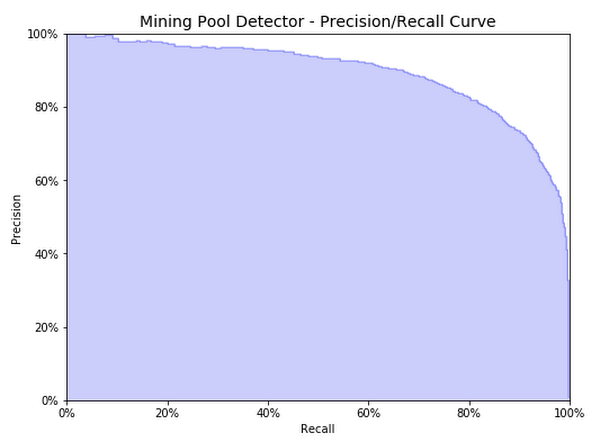
Because our dataset is imbalanced, as you can see in the matrix above, it is useful to examine the relationship between precision and recall. The model threshold can be adjusted to increase recall (less false negatives), but at the expense of decreased precision (more false positives).
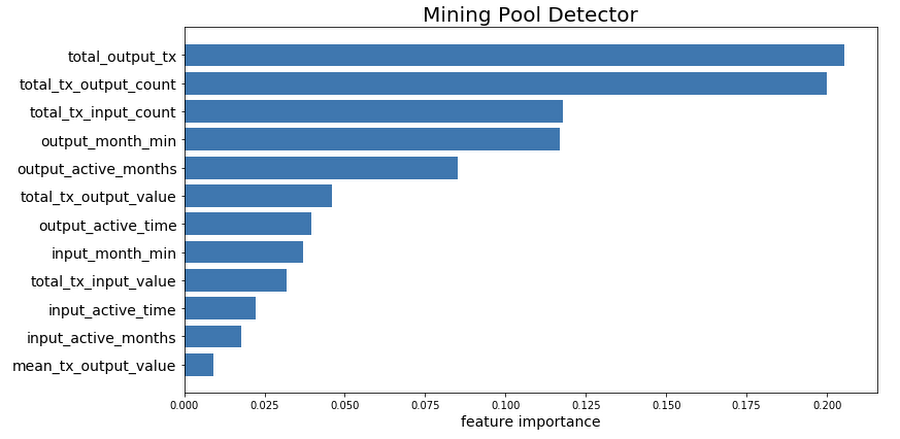
We can examine relative feature importance to determine which features are the strongest predictors in our model. Unsurprisingly, given that mining pools are making many small payments to the cooperating members, the following features have the most predictive power for a mining pool address:
- Number of output transactions
- Total number of transaction outputs
- Total number of transaction inputs
For a deeper understanding of query performance on the blockchain, check out a comparison of transaction throughputs for blockchains in BigQuery..
Next steps
To get started exploring the new datasets, here are links to them in BigQuery:
- Bitcoin (new location): bigquery-public-data.crypto_bitcoin
- Bitcoin Cash: bigquery-public-data.crypto_bitcoin_cash
- Dash: bigquery-public-data.crypto_dash
- Dogecoin: bigquery-public-data.crypto_dogecoin
- Ethereum (new location): bigquery-public-data.crypto_ethereum
- Ethereum Classic: bigquery-public-data.crypto_ethereum_classic
- Litecoin: bigquery-public-data.crypto_litecoin
- Zcash: bigquery-public-data.crypto_zcash
There’s also a Kaggle notebook that illustrates how to import data into a notebook for applying machine learning algorithms to the data. We hope these new public datasets encourage you to try out BigQuery and BigQuery ML for yourself. Or, if you run your own enterprise-focused blockchain, these datasets and sample queries can guide you as you form your own blockchain analytics.
Until then, if you have questions about this blog post, feel free to reach out to the authors on Twitter: Allen Day, Evgeny Medvedev, Nirmal AK, and Will Price. And here’s a shout-out to the outside contributors who helped develop and review this blog post: Gitcoin, for supporting Blockchain ETL; Samuel Omidiora and Yaz Khoury, for contributing to Blockchain ETL; and Aleksey Studnev of Bloxy for valuable discussions of analyses.