Built with BigQuery: How Oden provides actionable recommendations with network resiliency to optimize manufacturing processes
Dr. Ali Arsanjani
Director, AI/ML Partner Engineering, Head of AI Center of Excellence, Google Cloud
Devon Peticolas
Principal Engineer, Oden Technologies
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialBackground
The Oden Technologies solution is an analytics layer for manufacturers that combines and analyzes all process information from machines and production systems to give real-time visibility to the biggest causes of inefficiency and recommendations to address them. Oden empowers front-line plant teams to make effective decisions, such as prioritizing resources more effectively, solving issues faster, and realizing optimal behavior.
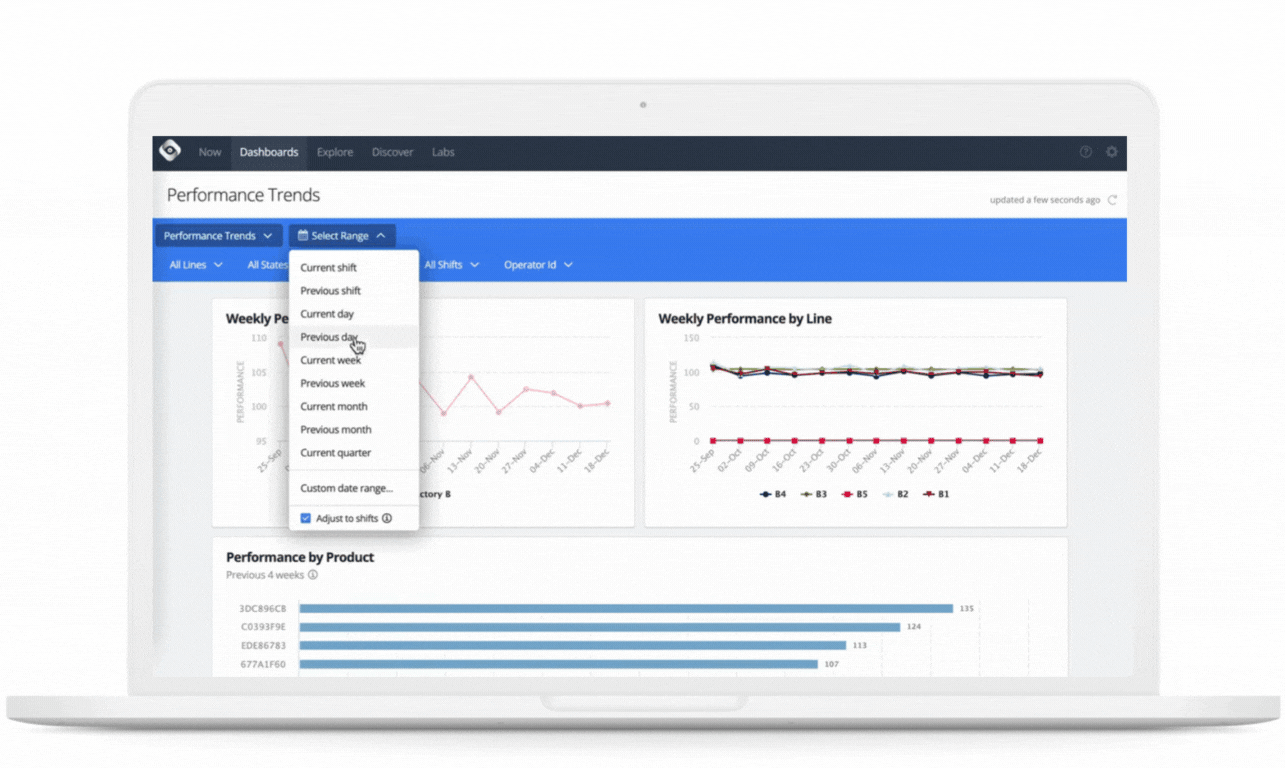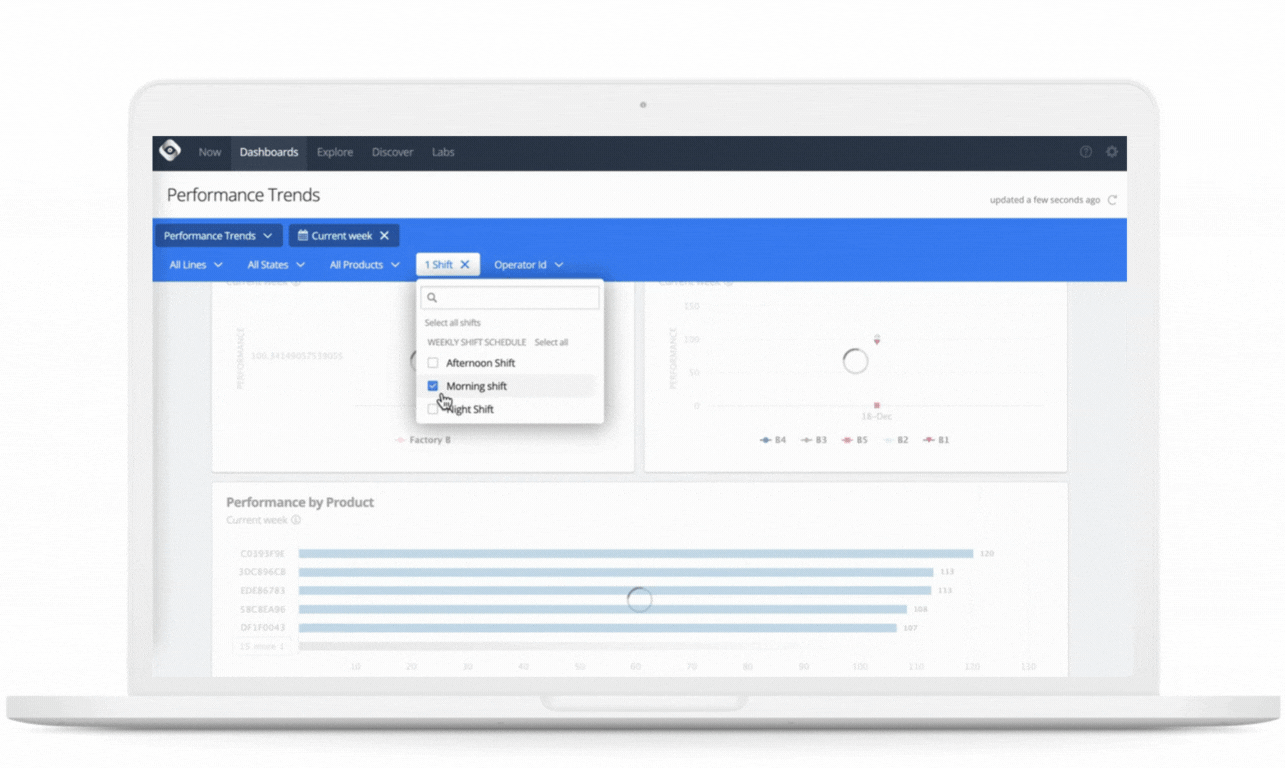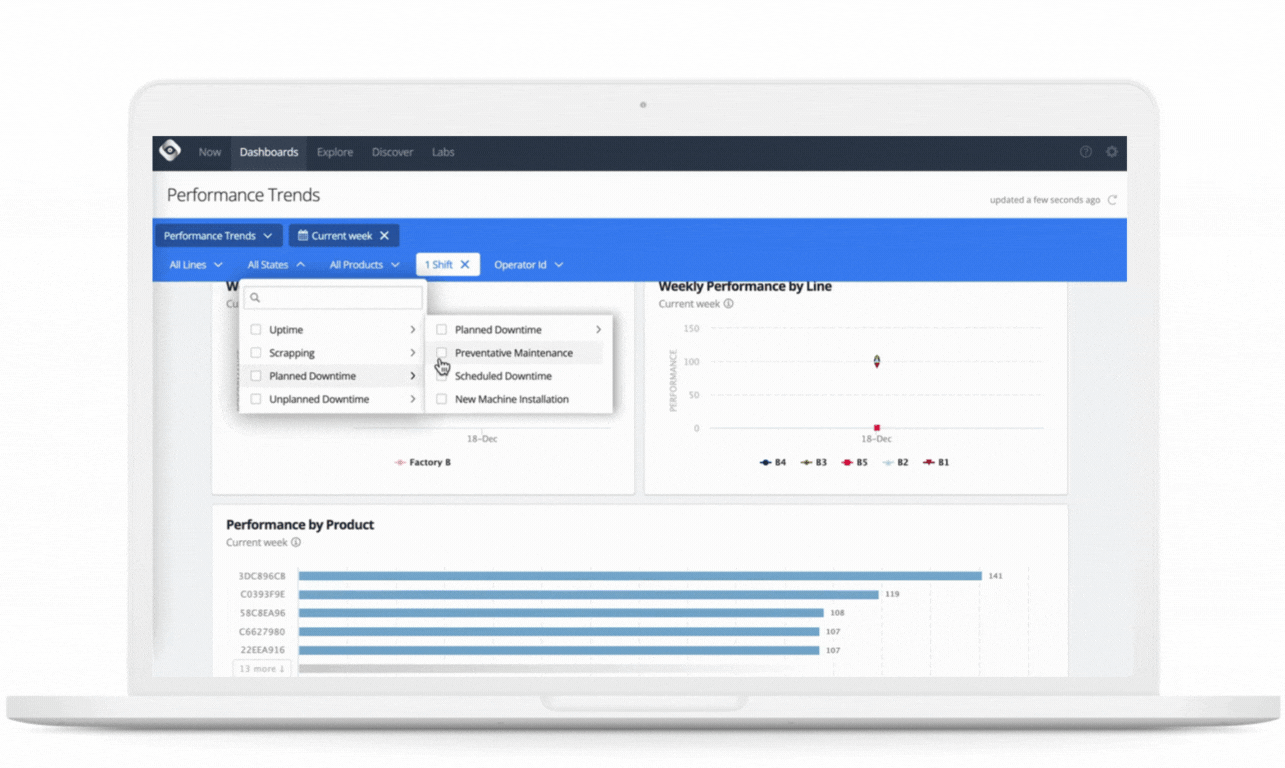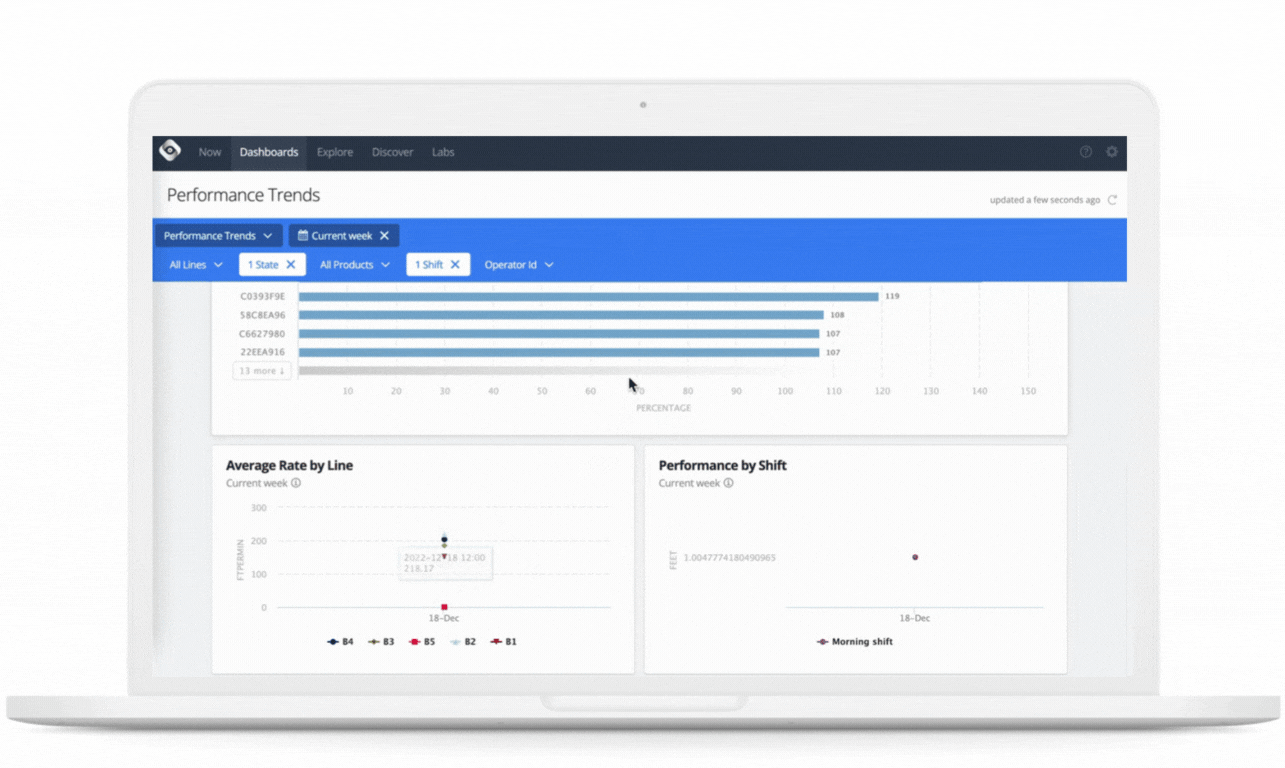
Use cases: Challenges and problems solved
Manufacturing plants have limited resources and would like to use them optimally by eliminating any inefficiencies and making recommendations and providing data points as a key input for decision making. These data points are based on a torrent of data coming from multiple devices.
Oden’s customers are manufacturers with continuous and batch processes, such as in plastics extrusion, paper and pulp, and chemicals. Oden powers real-time and historical dashboards and reports necessary for this decision-making through leveraging the underlying Google Cloud Platform.
Oden’s platform aggregates streaming, time-series data from multiple devices and instruments and processes them in real-time. This data is in the form of continuously sampled real-world sensor readings (metrics) that are ingested into CloudIoT and transformed in real-time using Dataflow before being written to Oden's time series database. Transformations include data cleaning, normalization, synchronization, smoothing, outlier removal, and multi-metric calculations that are built in collaboration with manufacturing customers. The time-series database then powers real-time and historical dashboards and reports.
One of the major challenges of working with real-time manufacturing data is handling network disruptions. Manufacturing environments are often not well served by ISPs and can experience network issues due to environmental and process conditions or other factors. When this happens, data can be backed up locally and arrive late after the connection recovers. To avoid overloading real-time dataflow jobs with this late data, BigQuery supports late data handling and recoveries.
In addition to the sensor data, Oden collects metadata about the production process and factory operation such as products manufactured on each line, their specifications and quality. Integrations provide the metadata via Oden’s Integration APIs running on Google Kubernetes Engine (GKE), which then writes it to a PostgreSQL database hosted in CloudSQL. The solution then uses this metadata to contextualize the time-series data in manufacturing applications.
Oden uses this data in several ways, including real-time monitoring and alerting, dashboards for line operators and production managers, historical query tools for quality engineers, and machine learning models trained on historical data and scored in real-time to provide live predictions, recommendations, and insights. This is all served in an easy to access and understand UI, greatly empowering employees across the factory to use data to improve their lines of business.
The second major challenge in manufacturing systems, is achieving quality specifications on the final product for it to be sold. Typically, Quality Assurance is conducted offline: after production has completed, a sample is taken from the final product, and a test is performed to determine physical properties of the product. However, this introduces a lag between the actual time period of production, and information about the effectiveness of that production—sometimes hours (or even days) after the fact. This prevents proactive adjustments that could correct for quality failures, and results in considerable waste.
Solution architecture
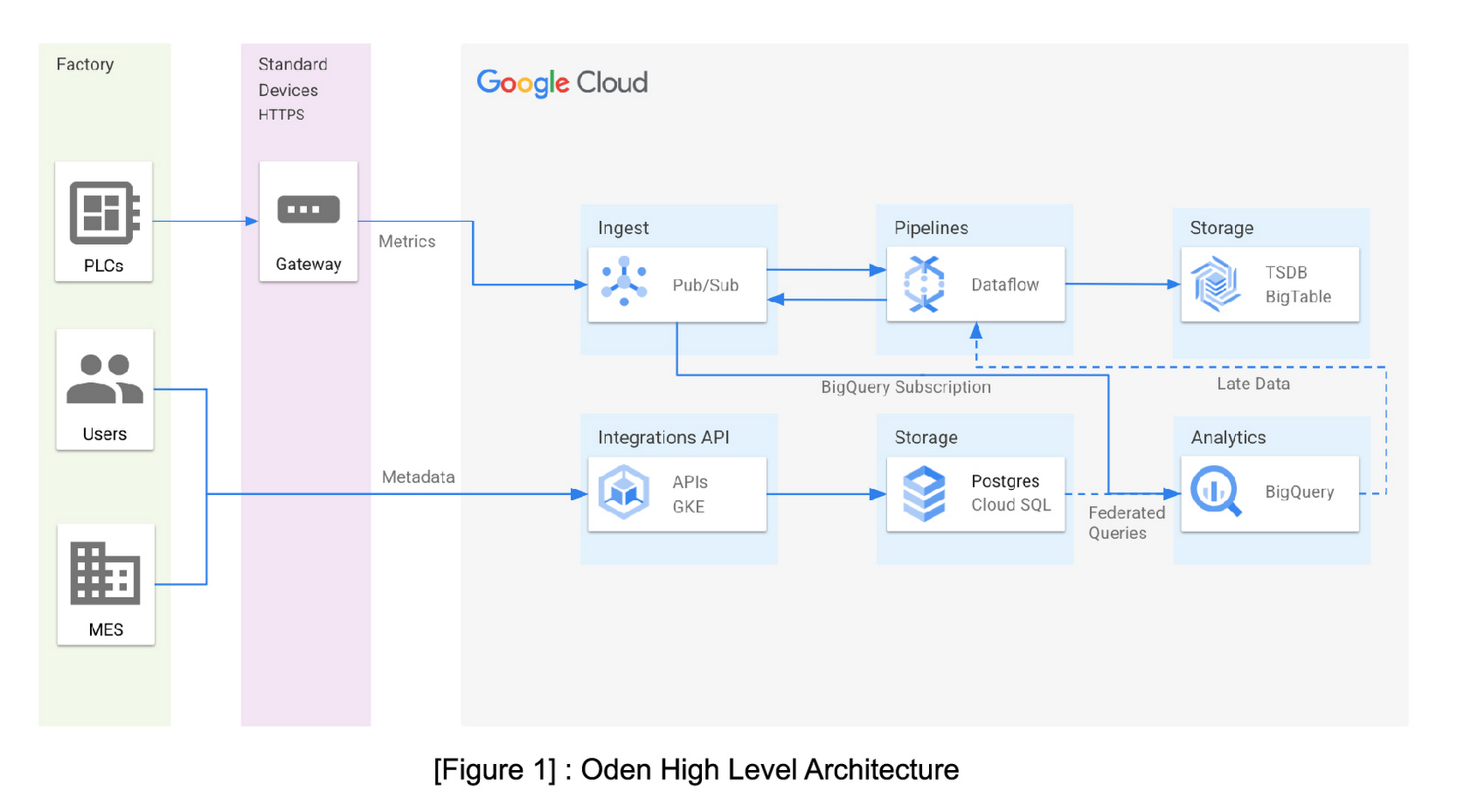
At the heart of the Oden platform is Google BigQuery, which plays an important backstage role in Oden’s data-driven software. Metric data is written simultaneously to BigQuery via a BigQuery Subscription through Cloud PubSub and metadata from CloudSQL is accessible via BigQuery’s Federated Queries. This makes BigQuery an exploratory engine for all customer data allowing Oden’s data scientists and engineers to support the data pipelines and build Oden’s machine learning models.
Sometimes these queries are ad-hoc analysis that helps understand data better. For example, here’s a BigQuery query joining both the native BigQuery metrics table and a Federated Query to the metadata in PostgreSQL This query helps determine the average lag between the event time and ingest time of customer metrics by day for November:
In addition to ad-hoc queries, there are also several key features of Oden that use BigQuery as their foundation. Below, two major features that leverage BigQuery as the highly scalable source of truth for data are covered.
Use case 1: The data reliability challenge of manufacturing and the cloud
As mentioned earlier, one of the major challenges of working with real-time manufacturing data is handling network disruptions. After the connection recovers, you encounter data that has been backed up and is out of temporal sequence. To avoid overloading real-time dataflow jobs with this late data, BigQuery is used to support late data handling and recoveries.
The data transformation jobs that run on Dataflow are written in the Apache Beam framework and usually perform their transformations by reading metrics from an input Pubsub topic and writing back to an output topic. This forms a directed acyclic graph (DAG) of transformation stages before the final metrics are written to the time-series database. But the streaming jobs degrade in performance when handling large bursts of late data putting the ability at risk to meet Service Level Agreements (SLAs), which guarantee customers high availability and fast end-to-end delivery of real-time features.
A key tenet of the Apache Beam model is that transformations can be applied to both bounded and unbounded collections of data. With this in mind, Apache Beam can be used for both streaming and batch processing. Oden takes this a step further with a universal shared connector for every one of the transformation jobs which allows the entire job to switch between a regular “streaming mode” and an alternative “Batch Mode.” In “Batch Mode,” the streaming jobs can do the same transformation but use Avro files or BigQuery as their data source.
This “Batch Mode'' feature started as a method of testing and running large batch recoveries after outages. But it has since evolved into a solution to late data handling problems. All data that comes in “late” to Oden bypasses the real-time Dataflow streaming jobs and is written to a special “Late Metrics” PubSub topic and then to BigQuery. Nightly, these “Batch Mode” jobs are deployed and data is queried that wasn’t processed that day out of BigQuery and results written back to the time-series database. This creates two SLAs for customers; a real-time one of seconds for “on-time” data and a batch one of 24 hours for any data that arrives late.
Occasionally, there is a need to backfill transformations of these streaming jobs due to regressions or new features to backport over old data. In these cases, batch jobs are leveraged again. Additionally, jobs specific to customer data are joined with metrics and customer configuration data hosted in CloudSQL via BigQuery’s Federated queries to CloudSQL.
By using BigQuery for recoveries, dataflow jobs continue to run smoothly, even in the face of network disruptions. This allows maintaining high accuracy and reliability in real-time data analysis and reporting. Since moving to separate BigQuery-powered late-data handling, the median system latency of calculated metrics feature for real-time metrics is under 2s which allows customers to observe and respond to their custom multi-sensor calculated metrics instantly.
Use case 2: Building and delivering predictive quality models
The next use case deals with applying machine learning to manufacturing: predicting offline quality test results using real-time process metrics. This is a challenging problem in manufacturing environments, where not only is high accuracy and reliability necessary, but the data is also collected at different sampling rates (seconds, minutes, and hours) and stored in several different systems. The merged datasets represent the comprehensive view of data to factory personnel, who use the entire set of context information to make operational decisions. This ensures Predictive Quality models access this same full picture of the manufacturing process as it provides predictions.
At Oden, BigQuery addresses the two key challenges of machine learning in the manufacturing environment:
Using time series data stored in time series database, summary aggregates are performed to construct features as input for model training and scoring.
Using federated queries to access context metadata, data is merged with the aggregates to fully characterize the production period. This allows easily combining the data from both sources and using it to train machine learning models.
Oden uses a variety of models and embeddings — ranging from linear models (Elastic Nets, Lasso), ensemble models (boosted trees, random forests) to DNNs that allow addressing the different complexity-accuracy-interpretability requirements of customers.
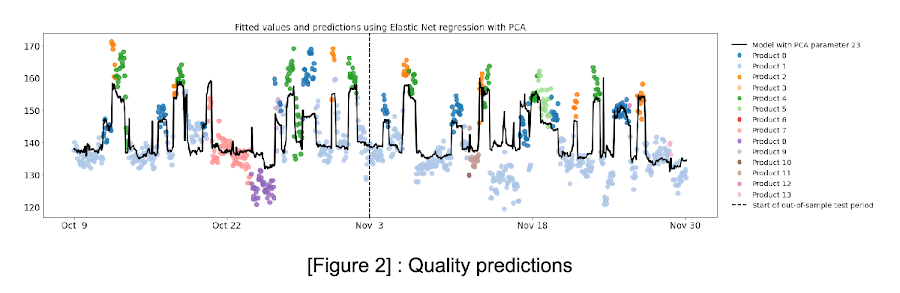
The chart shows out-of-sample predictions of offline quality test values, compared with the actual values that were observed after the end of production. The predicted values provide lead time of quality problems of up to one hour.
Models are trained using an automated pipeline based on Apache Airflow and scikit learn, and models are stored in Google Cloud Storage for versioning and retrieval. Once the models are trained, they can be used to predict the outcomes of quality tests in real-time via a streaming Dataflow job. This allows factory floor operators to identify and address potential problems before they become more serious or have a large impact. This improves the overall efficiency of the production process, and reduces the amount of waste that a factory generates. Factory floor operators receive up-to-date information about the quality characteristics of current production conditions, up to an hour before the actual test value is available for inspection. This gives early warning to help catch quality failures. In turn, this reduces material waste and machine downtime, metrics that are central to many manufacturers’ continuous improvement initiatives, as well as their day-to-day operations.
Operators come to rely upon predictive models to execute their roles effectively, regardless of their experience level or their familiarity with a specific type of production or machinery, and up-to-date models are critical to the success of the predictions in improving manufacturing processes. Hence, in addition to training, life-cycle management of models and ML ops are important considerations in deploying reliable models to the factory floor. Oden is focusing on leveraging Vertex AI to make the ML model lifecycle more simple and efficient.
Oden’s Predictive Quality model empowers operators to take proactive steps to optimize production on the factory floor, and allows for real-time reactions to changes in the manufacturing process. This contributes to cost reduction, energy savings, and reduced material wasted.
The future of BigQuery at Oden
Actionable data, like the processed data generated by Oden, has become such a critical part of making predictions and decisions to remain competitive in the manufacturing space. In order to use these insights to their full potential, businesses need a low barrier to access data, unify the data with other data sources, derive richer insights and make learned decisions. Oden already leads the market in having trustworthy, usable, and understandable insights from combined process, production, and machine data that is accessible from everyone within the plant to improve their line of business. There is opportunity to go beyond the Oden interface to integrate with even more business systems The data can be made available in the form of finished datasets, hosted in BigQuery. Google Cloud has launched a new service called Analytics Hub , powered by BigQuery with the intent to make data sharing easier, secure, searchable, reliable and highly scalable.
Analytics Hub is based on the Publish-Subscribe model where BigQuery datasets are enlisted into a Data exchange as a Shared dataset, which hosts hundreds of listings. It lets users share multiple BigQuery objects such as views, tables, external tables, models etc into the Data exchange. A Data exchange can be marked public or private for a dedicated sharing. On the other end, businesses can subscribe to one or more listings in their BigQuery instance, where it is consumed as a Linked dataset to run queries against. Analytics Hub sets up a real-time data pipeline with a low-code no-code approach to share data, while giving Oden complete control over what data needs to be shared for better governance.
This empowers advanced users, who have use-cases that exceed the common workflows already achievable with Oden’s configurable dashboard and query tools, to leverage the capabilities of BigQuery in their organization. This brings Oden’s internal success with BigQuery directly to advanced users. With BigQuery, they can join against datasets not in Oden, express complex BigQuery queries, load data directly with Google’s BigQuery client libraries, and integrate Oden data into third party Business Intelligence software such as Google Data Studio.
Better together
Google Cloud and Oden are forging a strong partnership in several areas, most of which are central to customers needs. Oden has developed a turnkey solution by using the best in class Google Cloud tools and technologies, delivering pre-built models to accelerate time to value and enabling manufacturers to have accessible and impactful insights without hiring a data science team. Together, Google and Oden are expanding the way manufacturers access and use data by creating a clear path to centralize production, machine, and process data into the larger enterprise data platform paving the way for energy savings, material waste reduction and cost optimization,
Click here to learn more about Oden Technologies or to request a demo.
The Built with BigQuery advantage for ISVs
Google is helping tech companies like Oden Technologies build innovative applications on Google’s data cloud with simplified access to technology, helpful and dedicated engineering support, and joint go-to-market programs through the Built with BigQuery initiative, launched in April ‘22 as part of the Google Data Cloud Summit. Participating companies can:
Get started fast with a Google-funded, pre-configured sandbox.
Accelerate product design and architecture through access to designated experts from the ISV Center of Excellence who can provide insight into key use cases, architectural patterns, and best practices.
Amplify success with joint marketing programs to drive awareness, generate demand, and increase adoption.
BigQuery gives ISVs the advantage of a powerful, highly scalable data warehouse that’s integrated with Google Cloud’s open, secure, sustainable platform. And with a huge partner ecosystem and support for multi-cloud, open source tools and APIs, Google provides technology companies the portability and extensibility they need to avoid data lock-in.
Click here to learn more about Built with BigQuery.
We thank the Google Cloud and Oden team members who co-authored the blog: Oden: Henry Linder, Staff Data Scientist & Deepak Turaga, SVP Data Science and Engineering. Google: Sujit Khasnis, Solutions Architect & Merlin Yammsi, Solutions Consultant

