The new data scientist: From analyst to agentic architect
Yasmeen Ahmad
Managing Director, Data Cloud, Google Cloud
The role of the data scientist is rapidly transforming. For the past decade, their mission has centered on analyzing the past to run predictive models that informed business decisions. Today, that is no longer enough. The market now demands that data scientists build the future by designing and deploying intelligent, autonomous agents that can reason, act, and learn on behalf of the enterprise.
This transition moves the data scientist from an analyst to an agentic architect. But the tools of the past — fragmented notebooks, siloed data systems, and complex paths to production — create friction that breaks the creative flow.
At Big Data London, we are announcing the next wave of data innovations built on an AI-native stack, designed to address these challenges. These capabilities help data scientists move beyond analysis to action by enabling them to:
-
Stop wasting time context-switching. We're delivering a single, intelligent notebook environment where you can instantly use SQL, Python, and Spark together, letting you build and iterate in one place instead of fighting your tools.
-
Build agents that understand the real world. We're giving you native, SQL-based access to the messy, real-time data — like live event streams and unstructured data — that your agents need to make smart, context-aware decisions.
-
Go from prototype to production in minutes, not weeks. We're providing a complete 'Build-Deploy-Connect' toolkit to move your logic from a single notebook into a secure, production-grade fleet of autonomous agents.
Unifying the environment for data science
The greatest challenge of data science productivity is friction. Data scientists live in a state of constant, forced context-switching: writing SQL in one client, exporting data, loading it into a Python notebook, configuring a separate Spark cluster for heavy lifting, and then switching to a BI tool just to visualize results. Every switch breaks the creative "flow state" where real discovery happens. Our priority is to eliminate this friction by creating the single, intelligent environment an architect needs to engineer, build, and deploy — not just run predictive models.
Today, we are launching fundamental enhancements to Colab Enterprise notebooks in BigQuery and Vertex AI. We’ve added native SQL cells (preview), so you can now iterate on SQL queries and Python code in the same place. This lets you use SQL for data exploration and immediately pipe the results into a BigQuery DataFrame to build models in Python. Furthermore, rich interactive visualization cells (preview) automatically generate editable charts from your data to quickly assess the analysis. This integration breaks the barrier between SQL, Python, and visualization, transforming the notebook into an integrated development environment for data science tasks.
But an integrated environment is only half the solution; it must also be intelligent. This is the power of our Data Science Agent, which acts as an "interactive partner" inside Colab. Recent enhancements to this agent mean it can now incorporate sophisticated tool usage (preview) within its detailed plans, including the use of BigQuery ML for training and inferencing, BigQuery DataFrames for analysis using Python, or large scale Spark transformations. This means your analysis gets more advanced, your demanding workloads are more cost-effective to run, and your models get into production quicker.
In addition, we are also making our Lightning Engine generally available. The Lightning Engine accelerates Spark performance more than 4x compared to open-source Spark. And Lightning Engine is ML and AI-ready by default, seamlessly integrating with BigQuery Notebooks, Vertex AI, and VS Code. This means you can use the same accelerated Spark runtime across your entire workflow in any tool of choice — from initial exploration in a notebook to distributed training on Vertex AI. We're also announcing advanced support for Spark 4.0 (preview), bringing its latest innovations directly to you.
Building agents that understand the real world
Agentic architects build systems that will sense and respond to the world in real time. This requires access to data that has historically been siloed in separate, specialized systems such as live event streams and unstructured data. To address this challenge we are making real-time streams and unstructured data more accessible for data science teams.
First, to process real-time data using SQL we are announcing stateful processing for BigQuery continuous queries (preview). In the past, it was difficult to ask questions about patterns over time using just SQL on live data. This new capability changes that. It gives your SQL queries a "memory," allowing you to ask complex, state-aware questions. For example, instead of just seeing a single transaction, you can ask, "Has this credit card's average transaction value over the last 5 minutes suddenly spiked by 300%?" An agent can now detect this suspicious velocity pattern — which a human analyst reviewing individual alerts would miss — and proactively trigger a temporary block on the card before a major fraudulent charge goes through. This unlocks powerful new use cases, from real-time fraud detection to adaptive security agents that learn and identify new attack patterns as they happen.
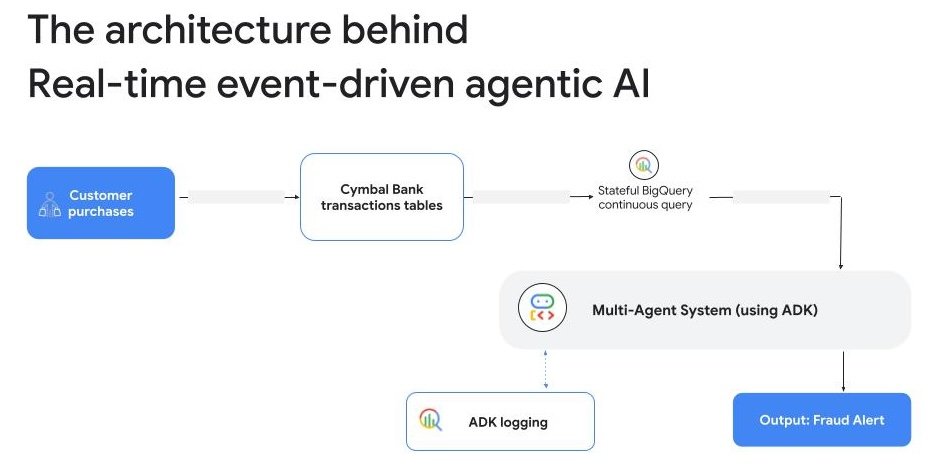
Second, we are removing the friction to build AI applications using a vector database, by helping data teams with autonomous embedding generation in BigQuery (preview) over multimodal data. Building on our BigQuery Vector Search capabilities, you no longer have to build, manage, or maintain a separate, complex data pipeline just to create and update your vector embeddings. BigQuery now takes care of this automatically as data arrives and as users search for new terms in natural language. This capability enables agents to connect user intent to enterprise data, and it’s already powering systems like the in-store product finder at Morrisons, which handles 50,000 customer searches on a busy day. Customers can use the product finder on their phones as they walk around the supermarket. By typing in the name of a product, they can immediately find which aisle a product is on and in which part of that aisle. The system uses semantic search to identify the specific product SKU, querying real-time store layout and product catalog data.
Trusted, production ready multi-agent development
When an analyst delivers a report and their job is done. When an architect deploys an autonomous application or agent, their job has just begun. This shift from notebook-as-prototype to agent-as-product introduces a critical new set of challenges: How do you move your notebook logic into a scalable, secure, and production-ready fleet of agents?
To solve this, we are providing a complete "Build-Deploy-Connect" toolkit for the agent architect. First, the Agent Development Kit (ADK) provides the framework to build, test, and orchestrate your logic into a fleet of specialized, production-grade agents. This is how you move from a single-file prototype to a robust, multi-agent system. And this agentic fleet doesn't just find problems — it acts on them. ADK allows agents to 'close the loop' by taking intelligent, autonomous actions, from triggering alerts to creating and populating detailed case files directly in operational systems like ServiceNow or Salesforce.
A huge challenge until now was securely connecting these agents to your enterprise data, forcing developers to build and maintain their own custom integrations. To solve this, we launched first-party BigQuery tools directly integrated within ADK or via MCP. These are Google-maintained, secure tools that allow your agent to intelligently discover datasets, get table info, and execute SQL queries, freeing your team to focus on agent logic, not foundational plumbing. In addition, your agentic fleet can now easily connect to any data platform in Google Cloud using our MCP Toolbox. Available across BigQuery, AlloyDB, Cloud SQL, and Spanner, MCP Toolbox provides a secure, universal 'plug' for your agent fleet, connecting them to both the data sources and the tools they need to function.
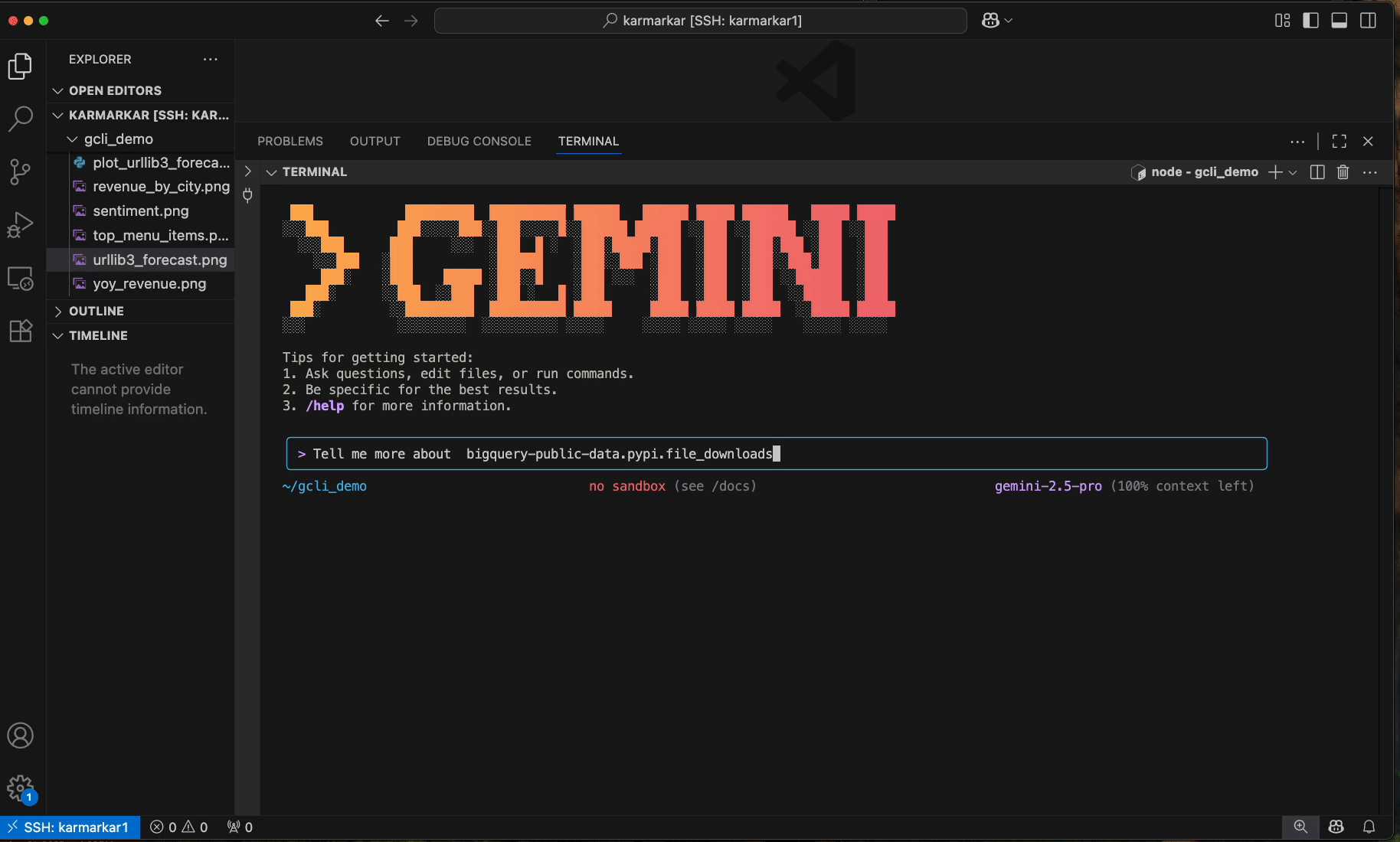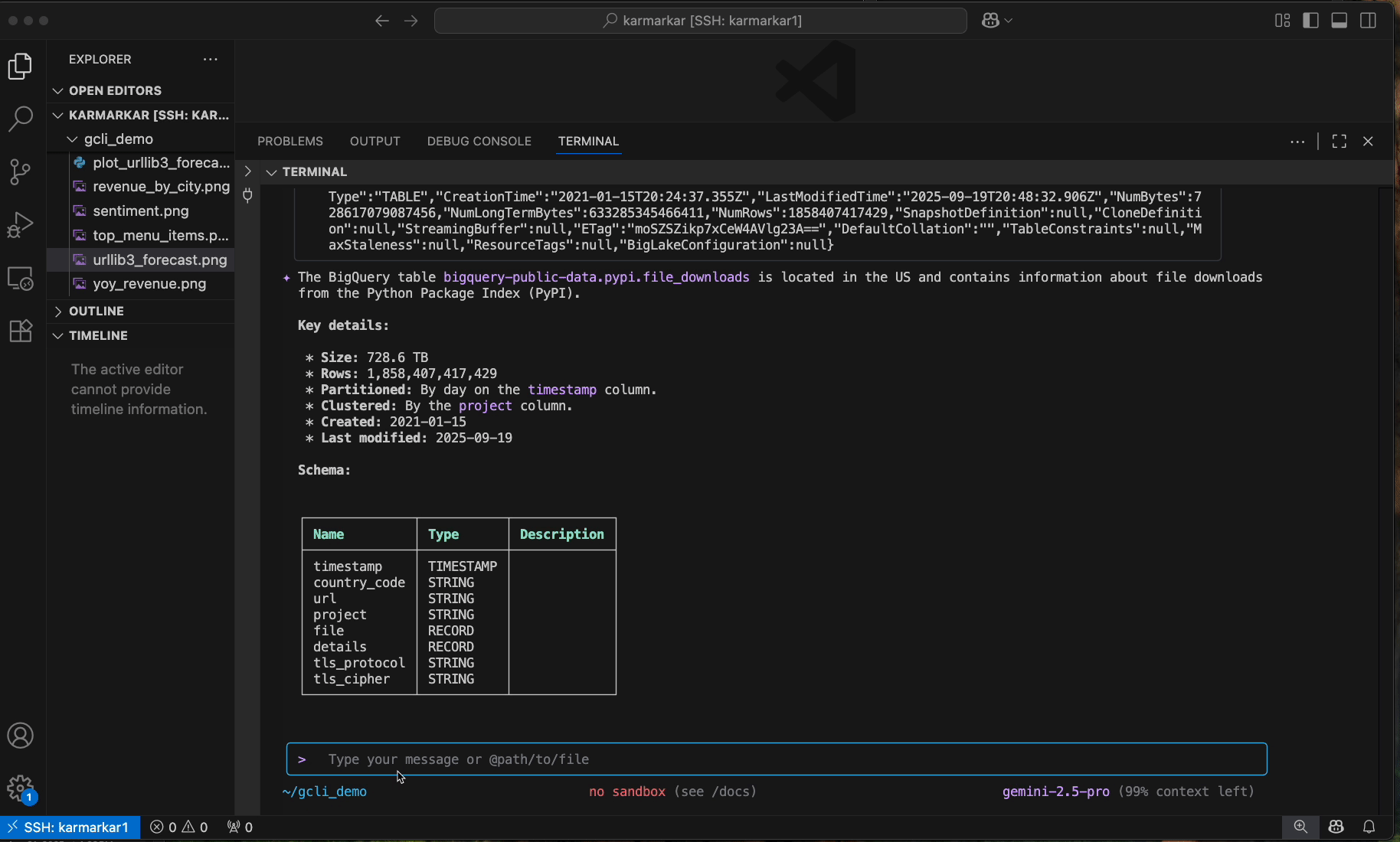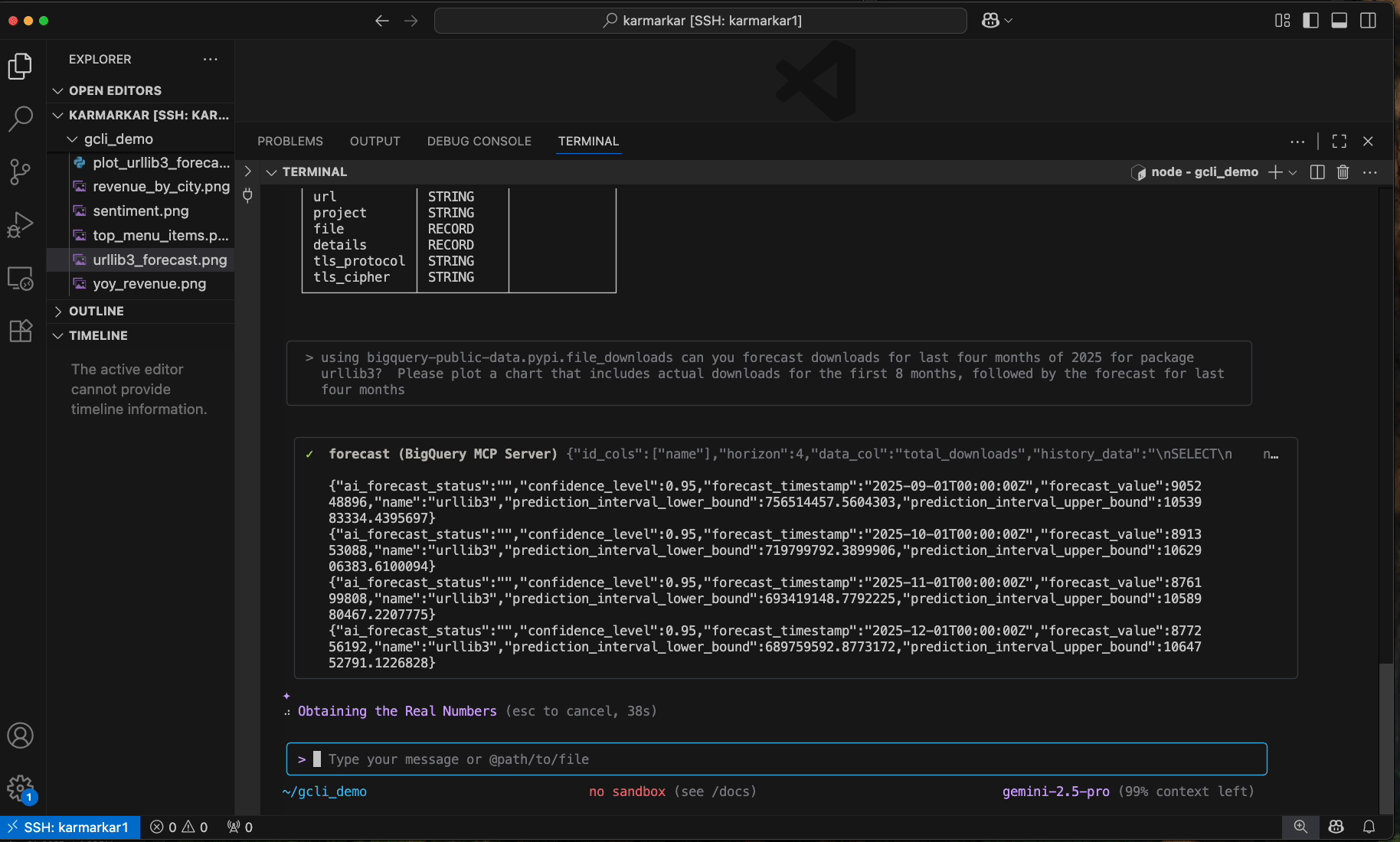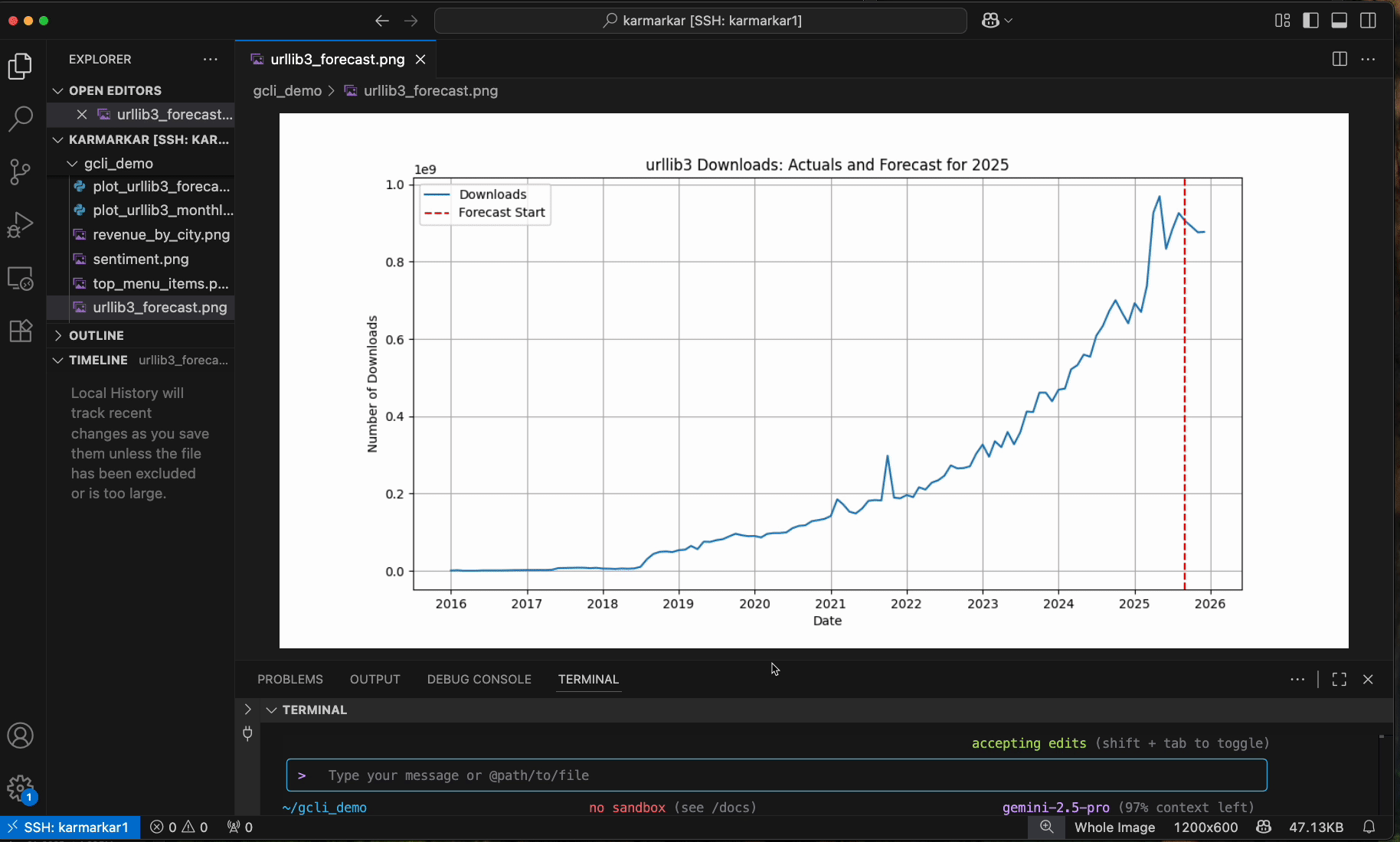
This "Build-Deploy-Connect" toolkit also extends to the architect's own workflow. While ADK helps agents connect to data, the architect (the human developer) needs to manage this system using a new primary interface: the command line (CLI). To eliminate the friction of switching to a UI for data tasks, we are integrating data tasks directly into the terminal with our new Gemini CLI extensions for Data Cloud (preview). Through the agentic Gemini CLI, developers can now use natural language to find datasets, analyze data, or generate forecasts — for example, you can simply state gemini bq "analyze error rates for 'checkout-service'" — and even pipe results to local tools like Matplotlib, all without leaving your terminal.
Architecting the future
These innovations transform the impact data scientists can have within the organization. Using an AI-native stack we are now unifying the development environment in new ways, expanding data boundaries, and enabling trusted production ready development.
You can now automate tasks and use agents to become an agentic architect helping your organization to sense, reason, and act with intelligence. Ready to experience this transformation? Check out our new Data Science eBook with eight practical use cases and notebooks to get you started building today.

