Deliver trusted insights with Dataplex data profiling and automatic data quality
Sandeep Karmarkar
Product lead, BigQuery
Jitendra Koshti
Engineering Manager
We are excited to announce the general availability of data profiling and automatic data quality (AutoDQ) in Dataplex. These features enable Google Cloud customers to build trust in their analytical data in a scalable and automated manner.
Power innovation, decision-making, and differentiated customer experience with high-quality data
Data quality has always been an essential foundation for successful analytics and ML models. In these past six months, the rapid rise of artificial intelligence (AI) has led to an explosion in the use of machine learning (ML) models. The importance of data quality in machine learning has become even more critical in recent months. Data scientists and analysts need to understand their data more deeply before building the models. It will ultimately lead to more accurate and reliable ML outcomes.
Dataplex data profiling and AutoDQ make it easy to build and maintain this information in a scalable and efficient manner. These features offer:
Reduction in time to insights about the data
- Dataplex makes it easy and quick to go from data to its profile and quality. These features have zero-setup requirements and are easy to start within the BigQuery UI.
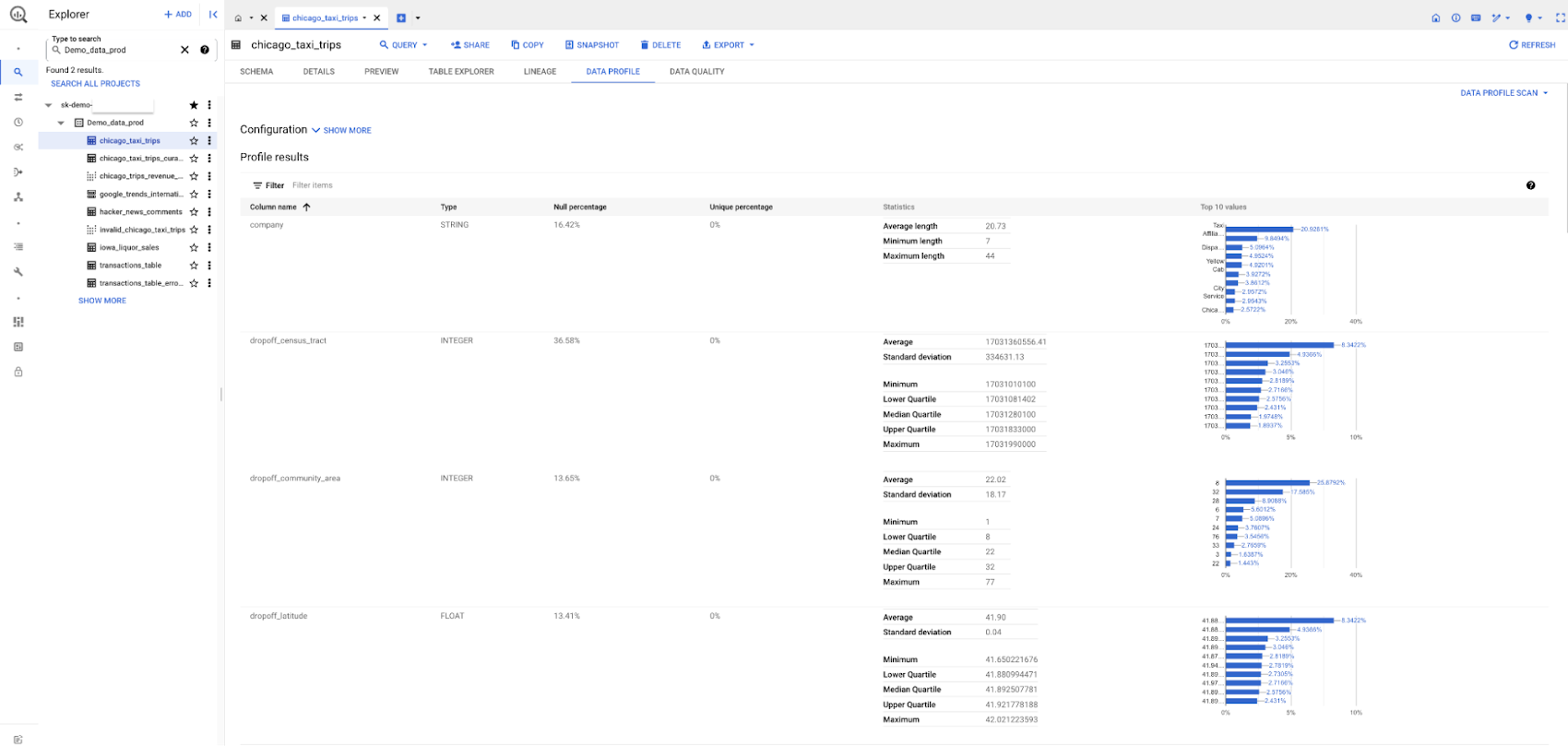
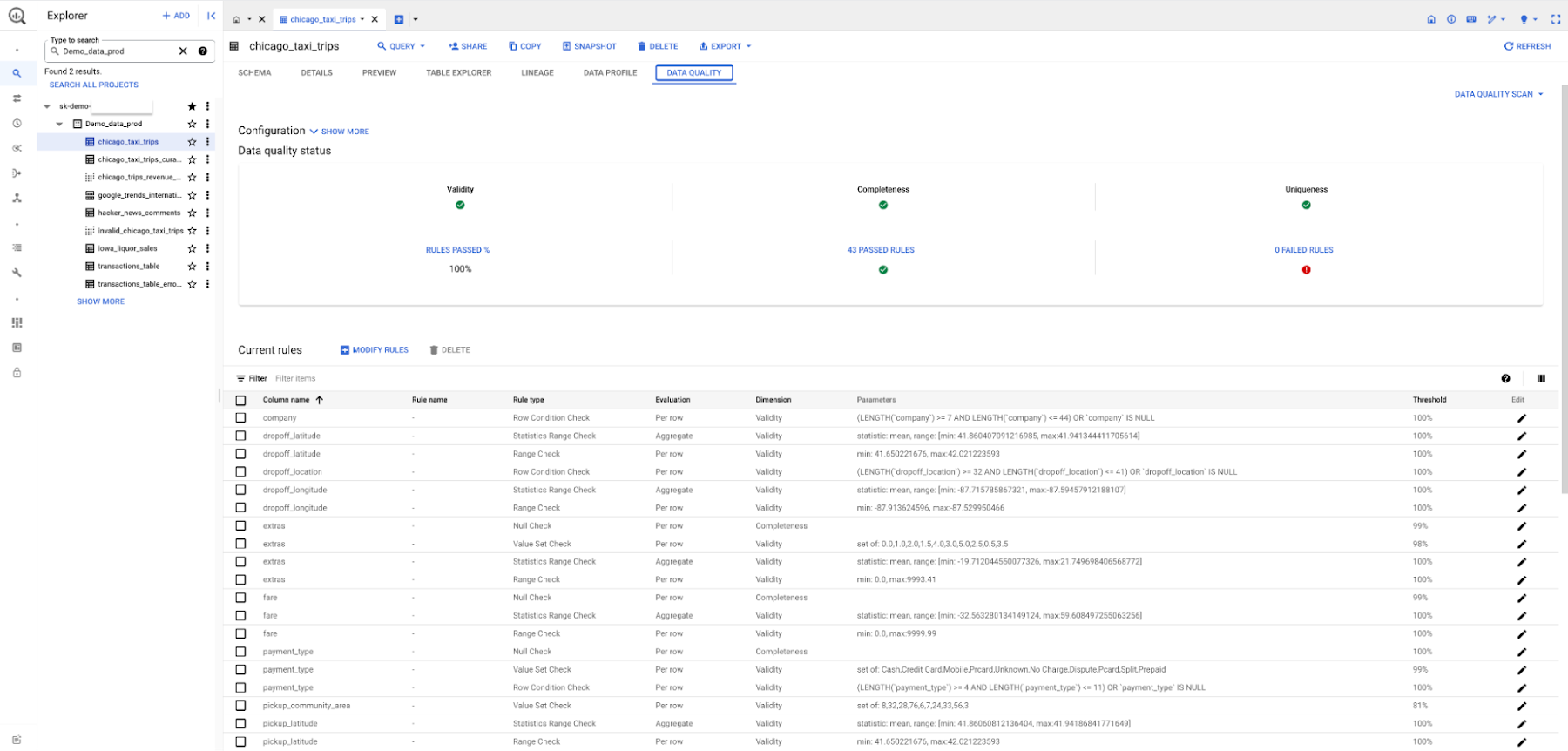
- Dataplex AutoDQ will get you started with intelligent rule recommendations and generate quality reports within a short time. Similarly, with a single click, Dataplex data profiling will generate meaningful insights like data distribution, top-N, unique percentages, etc.
Rich platform capabilities
Secure, performant, and efficient executionDataplex data profiling and AutoDQ are powerful new tools that can help organizations to improve their data quality and build more accurate and reliable insights and models.
- The underlying capabilities of the platform allow users to build an end-to-end solution with desired customizations.
- Dataplex AutoDQ enables a data quality solution from rules to reports to alerts. AutoDQ rules can also incorporate BigQuery ML for advanced use cases.
- On the other hand, with the information Data profiling generates, you can build custom AI/ML models like drift detection for detecting meaningful shifts in your training data.
- These features are designed to work with petabyte-scale data without any data copy. While it leverages the scale-out power of BigQuery behind the scenes, it has zero impact on customers’ BigQuery slots and reservations.
What our customers have to say
Here is what some of our customers say about Dataplex data profiling and AutoDQ:
“At Paramount we have data coming from multiple vendors and data anomalies might occur from time to time with data from different sources and integration channels. We have started incorporating Dataplex AutoDQ and BigQuery ML to address the challenges to detect and get alerted on anomalies in real time. This is not only efficient but it will improve the accuracy of our data.” - Bhaskara Peta, SVP Data Engineering, Paramount Global
“At Orange, we are always on the cutting edge of innovation and rely on trusted insights to power this innovation. As we move our data and AI workloads to GCP, we have been looking for an elegant, integrated data quality service to provide a seamless experience to our data engineering team. We started using Dataplex AutoDQ at a very early stage and we believe it could become a strong basis in our journey to Data Democracy. We are also excited to continue partnering with Google on building a stronger and innovative roadmap!” - Guillaume Prévost, Lead Tech, Data and AI, Orange
New features
New and exciting additional features since the public preview include:
Configure and view results in BigQuery UI in addition to Dataplex
You can now perform data quality and data profiling tasks directly from BigQuery in addition to Dataplex. Data owners can configure their data scans and publish the latest results of their data profile and data quality scans next to the table information in BigQuery. This information can then be viewed by any user with the appropriate authorization, regardless of the project in which the table resides. This makes it easier for users to get started with data quality and data profiling, and it provides a more consistent experience across all of the tools they use to manage their data.
New deployment options
In addition to our rich UI, we also added support for creating, managing, and deploying data quality and data profiling scans using a variety of methods, including:
Terraform: A first-class Terraform operator for deploying and managing data quality and data profiling resources.
Python and Java client libraries: We provide client libraries for Python and Java that make it easy to interact with Dataplex data profiling and AutoDQ from your code.
CLI: We also have a comprehensive CLI that can be used to create, manage, and deploy scans from the command line.
YAML: When using the CLI or Terraform, you can create and manage your scans using a YAML-based specification.
We have also made Airflow operators available for data quality to allow engineers to build data-quality checks within their data production pipelines. The airflow operator gives data engineers more flexibility in using AutoDQ, making it easier to integrate data quality checks with their existing data pipelines.

New configuration options to save costs and/or protect sensitive data
We have enhanced the core capabilities of Dataplex data profiling and AutoDQ to make them more flexible and scalable.
Row filters: Users can now specify row filters to focus on data from certain segments or to eliminate certain data from the scan. This can be useful for tuning scans for specific use cases, such as compliance or privacy.
Column filters: You can now specify column filters to avoid publishing stats on sensitive columns. This can help to protect sensitive data from unauthorized access.
Sampling: You can now sample your data for quick tests to save costs. This can be useful for getting a quick overview of the data quality and data profile without having to scan the entire dataset.
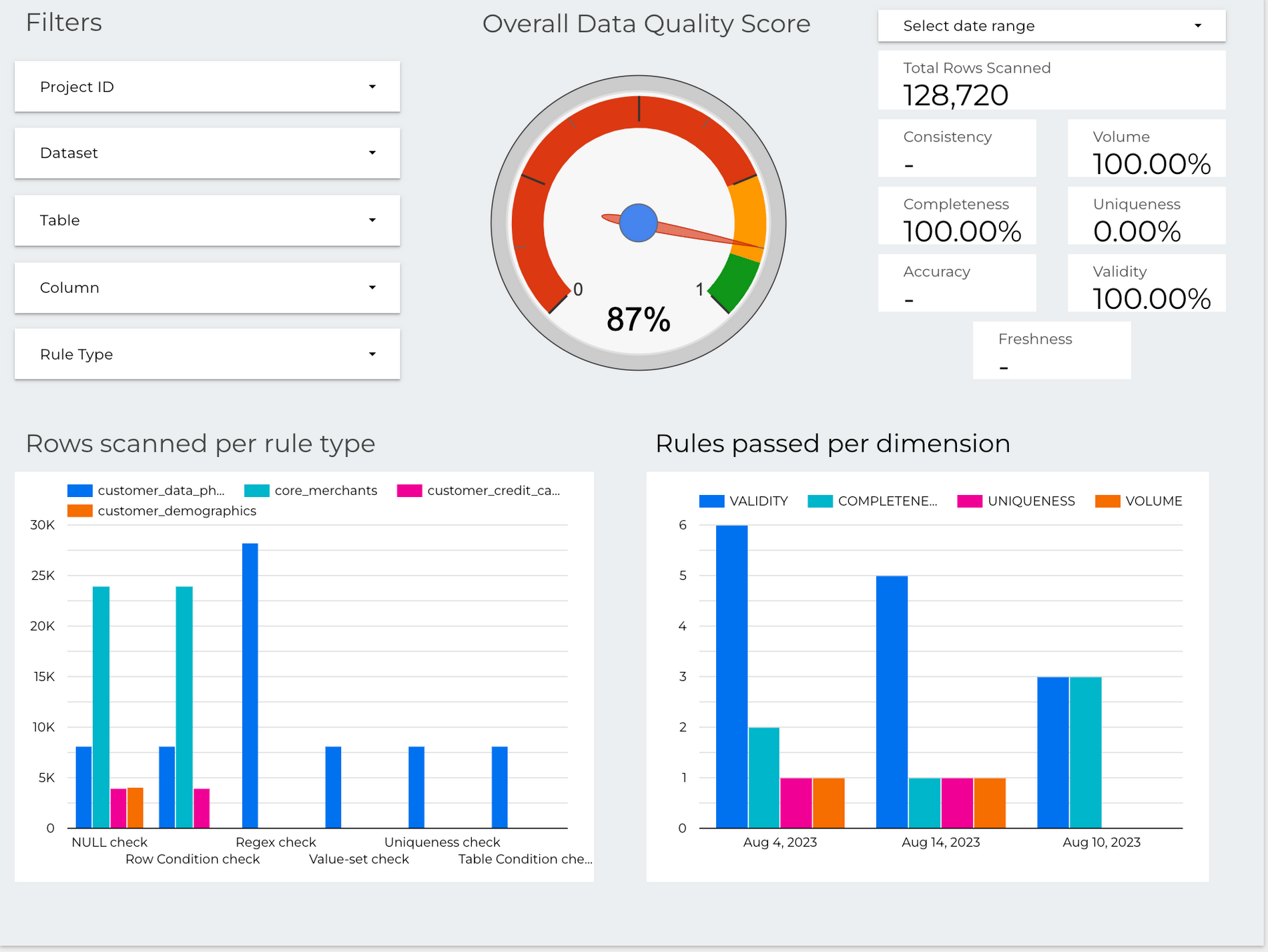
Build your reports or downstream ML models
Dataplex data profiling and AutoDQ can also export metrics to a BigQuery table. This makes it easy to build downstream applications that use the metrics, such as:
Drift detection: You can use BQML to build a model that predicts the expected values for the metrics. You can then use this model to detect any changes in the metrics that indicate data drift.
- Data-quality dashboard: You can build a dashboard that visualizes the metrics for a data domain. This can help you to identify any data quality issues.
We are grateful to our customers for partnering with us to build data trust, and we are excited to make these features generally available so that even more customers can benefit.
Learn more
Get started by creating a data profile or data quality scan on BigQuery public data
Learn more about Dataplex Data profiling


